1. Introduction
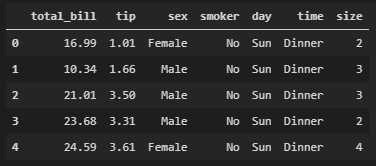
In this article we will use classic dataset "tips.csv" as example.
import pandas as pd
import numpy as np
tips = pd.read_csv("tips.csv")
tips.head()
2. Tradition Method
Tradionally, we will use groupby() and "[[" to subset variables, and then we can do a summary with aggregation function.
This process is easy to understand so many people will learn it at the first place, however, it has a shortcoming:
The aggregation function is applied to each variable seperatly. If we want to do summary with calculation of two or more varibales, we have to do it in one or more addtional steps.
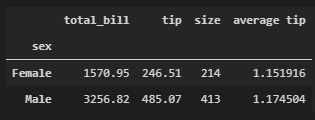
For example, In below process, aggregation function "sum" is applied to "total_bill", "tip", "size", seperatly. If we want to do summary with calculation of sum(tip) / sum(size), we will have to do it in addional step.
In other words, the process is verbose:
1. We have to name intermediate variables, which is sometimes hard to think a reasonable name and it will not be used at all in other place else.
2. We are over typing additional gramma to make sense. Like [, ", =...
3. We are using imperative programming, which may harm the modifiability of our code in future.
summary_sex = tips.groupby("sex")[["total_bill", "tip", "size"]].sum()
summary_sex["average tip"] = summary_sex["tip"] / summary_sex["size"]
summary_sex
3. agg()
agg() was first introducted at 0.20.0 version of pandas. It reduces some part of verbose with idea of pipline.
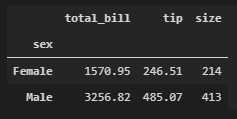
to_summary = {"total_bill": np.sum, "tip": np.sum, "size": np.sum}
tips.groupby("sex").agg(to_summary)
It may seem not so much different than tradional method we mentioned above. But thanks to the idea of pipline, we can continue to add manipulation after it.
1. We don‘t have to name intermediate variables.
2. We are less typing but doing more jobs. And the readability is even better.
(By the way, if you don‘t like np.sum, we can use a string "sum" instead. Other aggregation functions are the same)
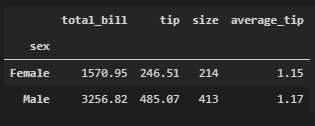
to_summary = {"total_bill": np.sum, "tip": np.sum, "size": np.sum}
(tips.groupby("sex")
.agg(to_summary)
.assign(average_tip=lambda df: df["tip"]/df["size"])
.round(2)
)
The process is better than trational method, but still we are doing aggregation to each variable seperately. How can we do summary with calculation of two or more variables in one step?
4. apply()
The differnce between agg() and apply() is that apply() can access to whole dataframe. Because of this, it can do summary with calculation of two or more variables in only one step.
(But also because of that, if the dataframe is huge, apply() may run slow)
I am surprised I have spent so much time to find a solution of this process. And I certainly will use it a lot in future daily analysis.
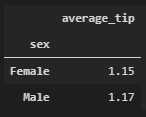
def func_average_tip(df):
result = {
"average_tip": df["tip"].sum() / df["size"].sum()
}
return pd.Series(result)
tips.groupby("sex").apply(func_average_tip).round(2)
Data Aggregation in Python Pandas
原文:https://www.cnblogs.com/drvongoosewing/p/13968739.html