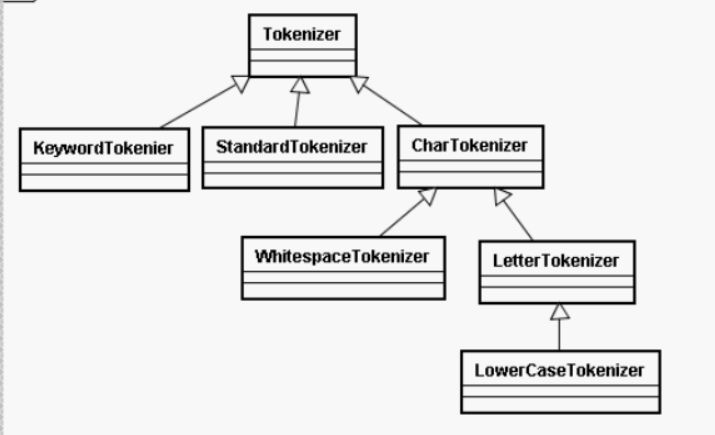
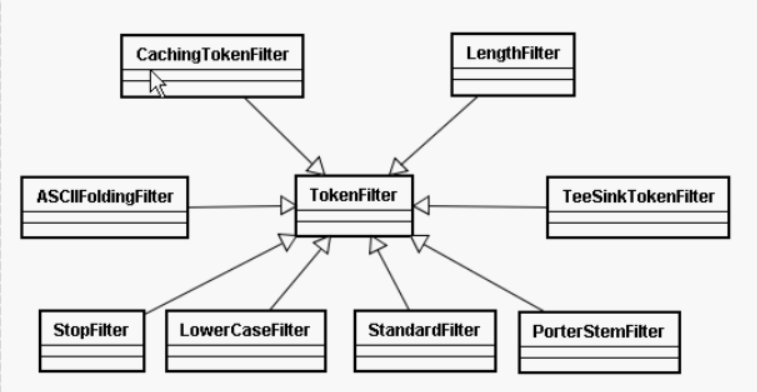
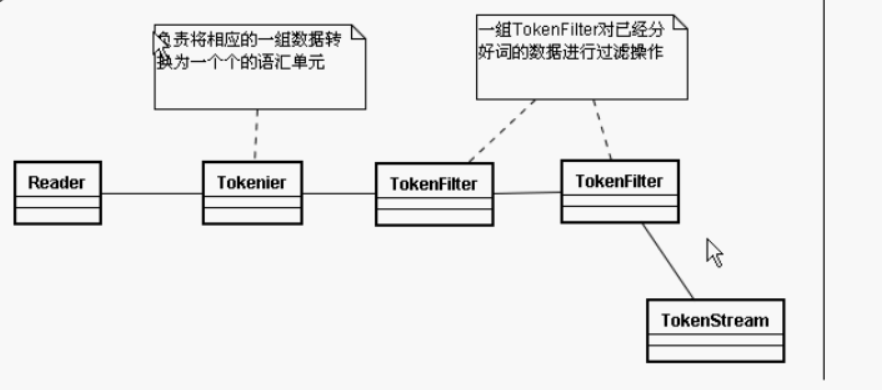
4.TokenFilter
二、Attribute类
//前三个很重要!
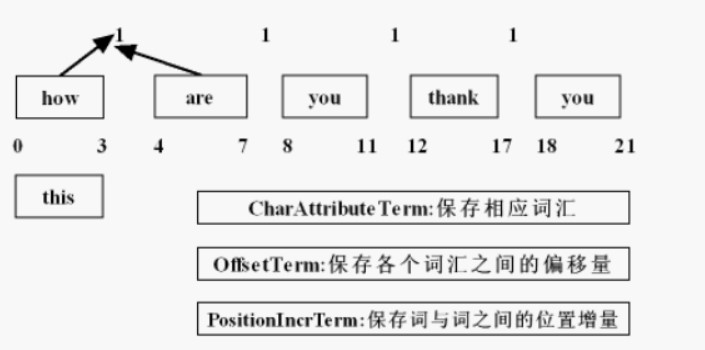
PositionIncrementAttribute pia = stream.addAttribute(PositionIncrementAttribute.class);
//位置增量的属性,存储语汇单元之间的距离(可做同义词)
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class);
//每个语汇单元的位置偏移量
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
//存储每一个分词的单元信息
TypeAttribute ta = stream.addAttribute(TypeAttribute.class);
//分词器的类型信息原文:https://www.cnblogs.com/nuistjungu/p/13975808.html