本文主要承接上文,以tsne的方式,侧面验证聚类的效果。流程大致为:1.用sklearn对数据进行tsne降维; 2.用Matplotlib进行数据可视化和数据探索。
上次写到航空公司客户的RFM价值分析,即抽取航空公司2012年4月1日至2014年3月31日的数据,构建出客户关系长度L、消费时间间隔R、消费频率F、飞行里程M、折扣系数的平均值C共5个维度的特征,再对特征进行标准化后,用k-means聚类,对62044位会员进行聚类,并聚成5个客户群。
尽管对比聚类中心,我们可以对航空公式当前的客群有一个大体的learning,但仍然有必要在尽可能保持数据信息的完整程度的情况下,去判断当前对每个客户的聚类结果是否符合我们的预期。由于每位客户拥有5个维度的特征,我们没有办法去可视化聚类效果,因此需要对数据进行降维处理。可以考虑的方法有二个:一、主成分分析,在尽可能保持信息完整度的情况下,把数据转为不相关的主成分,实现降维;二、t-sne,将高纬度的数据分布映射到低维度的数据,尽可能减少,二种分布的差异。本文尝试用tsne来实现高维度数据的可视化分析。
t-SNE 算法对每个数据点近邻的分布进行建模,其中近邻是指相互靠近数据点的集合。在原始高维空间中,我们将高维空间建模为高斯分布,而在二维输出空间中,我们可以将其建模为 t 分布。该过程的目标是找到将高维空间映射到二维空间的变换,并且最小化所有点在这两个分布之间的差距。与高斯分布相比 t 分布有较长的尾部,这有助于数据点在二维空间中更均匀地分布。
控制拟合的主要参数为困惑度(Perplexity)。困惑度大致等价于在匹配每个点的原始和拟合分布时考虑的最近邻数,较低的困惑度意味着我们在匹配原分布并拟合每一个数据点到目标分布时只考虑最近的几个最近邻,而较高的困惑度意味着拥有较大的「全局观」。
因为分布是基于距离的,所以所有的数据必须是数值型。我们应该将类别变量通过二值编码或相似的方法转化为数值型变量,并且归一化数据也是也十分有效,因为归一化数据后就不会出现变量的取值范围相差过大。
当前的数据结构为标准化后的客户关系长度L、消费时间间隔R、消费频率F、飞行里程M、折扣系数的平均值C,数据结构如下:
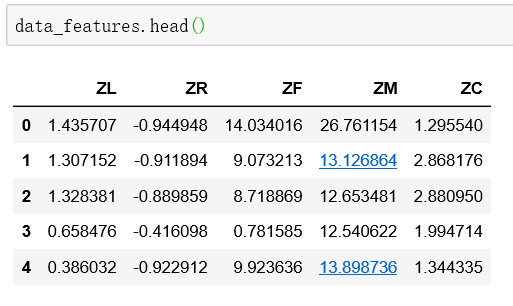
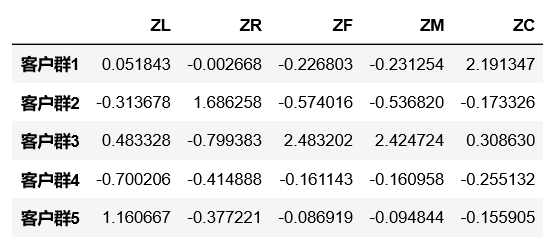
我们把客户聚成5类客户群,其中
我们先把所有的样本和样本的聚类结果先拼接在一起:
data = pd.concat([data_features,pd.Series(kmodel.predict(data_features),index =data_features.index,name ="Cluster") ],axis=1)
#选500个样本 X = data[data.columns[:-1]].sample(n=500,axis = "index",random_state=1234) labels = data[data.columns[-1]].sample(n=500,axis = "index",random_state=1234)
为了把聚类中心,也画上去,我们也需要对聚类中心进行t-sne算法的映射:
X = X.append(cluster_center)
labels = labels.append(pd.Series(cluster_center.index.str.slice(-1).astype("int")-1,index = cluster_center.index )diaouong
调用sklearn中的工具,对当前的数据集进行t-sne的映射:
from sklearn.manifold import TSNE Y = TSNE(learning_rate=100,random_state=1234).fit_transform(X ,labels )
通过matplotlib,对转换后的数据进行可视化:
import numpy as np np.random.seed(19680801) import matplotlib.pyplot as plt fig, ax = plt.subplots() for label in labels.unique(): ax.scatter(Y[:,0][labels.index == "客户群" + str(label+1)],Y[:,1][labels.index == "客户群" + str(label +1)],s=100,marker = "*",edgecolors = "b") ax.text(Y[:,0][labels.index == "客户群" + str(label+1)],Y[:,1][labels.index == "客户群" + str(label +1)],f"客户群{label+1}") ax.scatter(Y[:,0][labels == label], Y[:,1][labels == label], s=20, label="客户群" + str(label+ 1),) ax.legend() ax.set_xlim([-25,40]) plt.show()
得到的结果如下图:
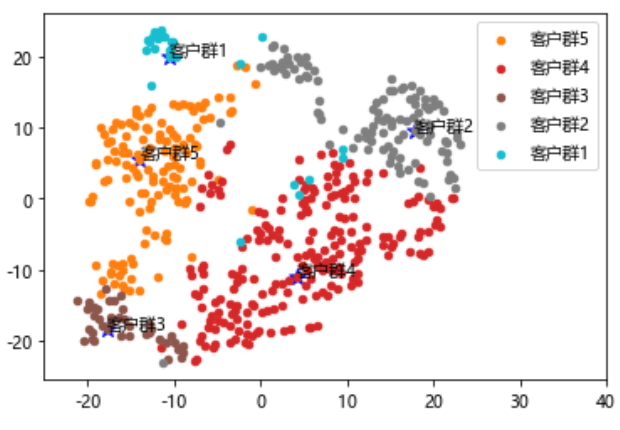
和咱们之前的learning相比,t-sne的可视化结果可以发现:
展示的结果基本符合了我们对不同客群的预期了解。
pease&love

诶,又一个双十一了,J可以挥霍的时间又少了一年噢。
额,最近小伙伴们似乎发现了J最近的变化。毕竟不可能一直走可爱路线吧,这不也想试试看能不能成精致的猪猪男孩么。借各位吉言,J重回单身了。每一段感情后呀,多少都会有些思考和感悟啦。安静的时候还是会想东西,跟别人说话的时候也会多一份暖意。开始留意下巴有没剃干净的胡渣,也明白不是所有人都喜欢替自己擦去脸颊汗珠的感觉。哦,下班路过专柜时,也会开始留意些什么。(钱包,危。。)
EMM,其实我以为可以很快振作重新开始啦,但是没想到健忘的人呀,要放下也没那么容易啦。不过难受的时候呀,想想被删掉的照片呀,想想昏昏沉沉回到上海的那天,直到过了12点还是收到其他人的问候的时候呀,我也就释然了吧。
也许呀,等到放晴的那天,也许我会比较好一点。
对了,我的吉他还像要练成了噢。
原文:https://www.cnblogs.com/307825064j/p/13982884.html
