为什么要数据分表?
因为在存数据的时候,为了方便缩减内存,会把类型,品牌..等再单独建立一个表,同时各个品牌,类型都有个独立的id,那么大表里填写类型与品牌的时候直接写上对应的类型品牌的id即可,这样可以缩减内存
1:把查询到的数据用insert into的方式放到另一个表中
insert into 新表名(新表名的字段名)select 旧表名的字段 from 旧表名
2:新建一个表同时又把查询到的数据放到新表中
注:如果新表没有跟查询的数据一样的字段,那执行之后的就是查询的字段名和数据都在新表中另成一列,如果需要把查询出的数据放到新表中的新建的字段里去,那就在旧表名的字段名加个“as 新字段名”,改成新字段名,那么数据就不会多一列而distinct是用来去重旧表的数据
create table 新表名(id int unsigned primary key auto_increment,新字段名 varchar(5))
select distinct 旧表名的字段名 from 旧表名
3:如果需要把独立的品牌表对应的id放到大表中,那么步骤如下
第一步解析:先查出我们想要的数据
第二步解析:把select * from换成update另外再加一句set.......
注:每个表中都必须要有相关联的数据,否则无意义
第一步:select * from 大表名 inner join 独立品牌表名 on 独立品牌表名.字段名=大表名.字段名
第二步:update 大表名 inner join 独立品牌表名 on 独立品牌表名.字段名=大表名.字段名 set 大表名.字段名=独立品牌名.要被改成id的字段名
连接
mysql -uroot -p 直接回车 输入密码
查看所有仓库
show databases;
使用某个仓库(重要)
use 数据库名;
查看所有的表
show tables;
查看表结构
desc 表名;
show create table 表名;
遇到中文乱码输入以下就不会再乱了
set charset gbk;
备份
--以管理员身份运行cmd程序
cd C:\Program Files (x86)\MySQL\MySQL Server 5.1\bin
mysqldump -uroot -p 数据库名 > 表名.sql
# 按提示输入mysql的密码
恢复
--先创建新的数据库
mysql -uroot -p 新数据库名< 表名.sql
#按提示输入mysql密码
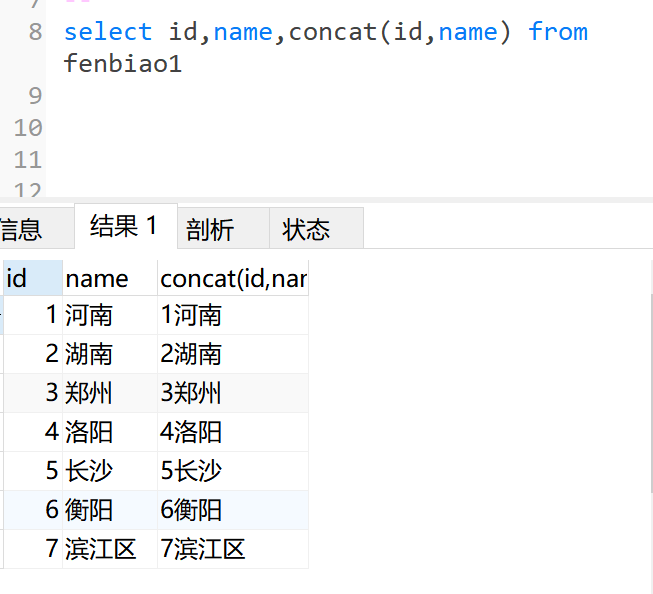
就是两个字段的数据拼成一句话在执行后会另出一列,用来放至这一句话,concat的两个字段中间也可加中文拼句子
select 字段1,字段2,concat(字段1,字段2) from 表名
select length(‘abc‘);
例如select * from 表名 where length(字段名)=9
就会出现这个字段名带两个中文的数据,一个中文输入3,除掉中文,其他字母跟符号1个就输入1就好了
在select 字段,字段,后面加入以下格式的语法加完后再加where 表名
left(字段,数量) 左边意思为要显示字段左边开始的多少个字符
right(字段,数量) 右边同上
substring (字段,位置,数量) substring就是加了一个位置,从某个位置取多少字符
select ltrim(‘字段‘) 去除某字段的左边边的空格
select rtrim(‘字段‘) 去除某字段的右边的空格
select trim(‘字段‘) 去除某字段的左右两边的空格 字符串中间含有空格则去除不了
select upper(‘字段名‘) 变成大写
select lower(‘字段名‘)变成小写
求四舍五入round(n,d),n表示原数,d表示小数位置,默认为0
例如:select round(1,6);
求x的y次幂pow(x,y)
select pow(2,3);
获取圆周率PI()
select PI()
随机数rand(),值为0-1.0的浮点数
select rand();
例如随即取一条数据
select * from 表名 order by rand() limit 1 意思为随即取一条升序里的一条数据
当前日期
select current_date();
当前时间
select current_time();
当前日期时间
select now();
日期格式化 date_fromat (now()参数1-参数2);
括号里可以写的参数如下,如果需要中间隔开,加上“/”或者“-”
%Y 获取完整年份
%y 获取简写年份
%m 获取月份
%H 获取24小时进制的小时数
%h 获取12小时的小时数
%1获取分
%s获取秒
case语法
意思为:当某个值等于我们设置的值时,就会执行相应的操作
当字段1的值等于某个比较值的时候,对应结果会被返回,如果不等于则不返回,如果所有的比较值都不相等则返回else的结果,如果没有else并且所有比较值都不相等则返回null
select 字段1,字段2,case 字段1 when 字段1的值 then concat(left(字段2,取多少字段2的值(写数字就行)),‘写中文也可以‘) from 表名
语法如下
delimiter $$ 把结尾;改为$$结尾
create function 函数名称(参数列表) returns 返回类型
begin
sql语句
$$
delimiter; 这个是改完$$结尾之后,再改回;结尾
说明:delimiter用于设置分割符,默认为分号,因为一条语法有了一个分号就代表不能再继续写了,delimiter就是用于把分号改成$$这样可以多写几天语法,逗号隔开,$$结束
在sql语句部分编写的语句需要以分号结尾,此时回车会直接执行,所以要创建存储过程前指定其他符号作为分割符,此处用//,也可以使用其他字符
示例:
要求创建函数my_trim,用于删除字符串左右两侧的空格
step1:设置分割符
先写好经常使用的select的语句
然后在select前写一句create view 视图的名字 as select语句
接着视图里面会有这个查询出来的数据,且相当于一个表,还取了名字
下次再使用的时候直接写成select * from 视图的名字,就会执行上次查询过的数据
需要修改视图的数据也可以设计视图,把sql语句修改,且数据都存在服务端的mysql
还有重要一点,视图可以找到数据的来源和被修改过的字段名字(有时候为了方便会把字段改名)
例子:转账
大大和小小都有一千元,大大需要转500给小小
步骤:begin:
update account set money=money-500 where name=‘大大‘
update account set money=money-500 where name=‘小小‘
commit;或者collback;
先输入一个update,成功后再输入第二个,如果语句有失败的那么输入rollback; 把扣掉的500返回给大大,如果都成功了输入commit则完成提交
可以让查询数据的时候更快,也相当于给众多数据建个目录,分类方便查找
缺点:在添加新数据的时候,会降低更新表的速度,加入新的数据时,mysql不仅要保存数据还要保存索引文件
在查询数据的时候在select前面加个explain就可以看到该字段是否有索引
查询某表是否有索引
show index from 表名
创建表的时候就在某个字段加个索引
create table 表名(字段1 类型.....,字段2 类型.....)
key (需要加索引的字段名);
在已经存在的表添加索引
create index 索引名称 on 表名(字段(长度))
删除索引
drop index 索引名称 on 表名
就是a表的某个字段的值只能在b表的某个字段的值范围内
缺点也是更新表的速度比较慢,a表中会有个下拉项,b表内有什么数据,那a就只能选什么
从表名就是a,主是b
alter table 从表名 add foreign key(从表字段)references 主表名(主表字段);
删除外键:alter table 表名 drop foreign key 外键名称;
外键名称获取方式:show create table 从表名
先执行,会出现创建表的语句,找到其中一句constraint这个单词开头的语句,这个单词后面的就是外键名称,把名称复制到删除外键的语法就可以删除
注:使用password()函数进行密码加密
注意修改完成后需要刷新权限就是提交的意思
第一步:use mysql; 打开数据库
第二步:update user set password=password(‘新密码‘) where user=‘用户名‘
第三步:flush privileges;
1:若想mysql登录不需要密码直接登录时
centos中:配置文件位置为/etc/my.cnt
windows中:配置文件位置为C:\Program Files(x88)\MySQL Server 5.1\my.ini
修改,找到mysqld,在它的下一行,输入skip-grant-tables
[mysqld]
skip-grant-tables
缺点是,这样的安全性太低,任何人都可以直接登录
2:接着改完之后,就可以update改密码了
3:还原配置文件,把刚才添加的skip-grant-tables删除,重启
原文:https://www.cnblogs.com/yangfen/p/13951558.html