原理
在Reudce端进行Join连接是MapReduce框架进行表之间Join操作最为常见的模式。
1.Reduce端Join实现原理
(1)Map端的主要工作,为来自不同表(文件)的key/value对打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
(2)Reduce端的主要工作,在Reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在map阶段已经打标志)分开,最后进行笛卡尔只就ok了。
2.Reduce端Join的使用场景
Reduce端连接比Map端连接更为普遍,因为在map阶段不能获取所有需要的join字段,即:同一个key对应的字段可能位于不同map中,但是Reduce端连接效率比较低,因为所有数据都必须经过Shuffle过程。
3.本实验的Reduce端Join代码执行流程:
(1)Map端读取所有的文件,并在输出的内容里加上标识,代表数据是从哪个文件里来的。
(2)在Reduce处理函数中,按照标识对数据进行处理。
(3)然后将相同的key值进行Join连接操作,求出结果并直接输出。
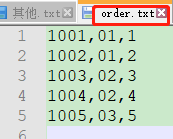
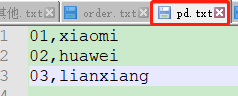
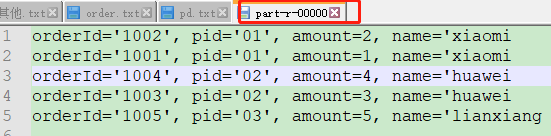
package com.atguigu.reduceJoin; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class OrderBean implements WritableComparable <OrderBean> { private String orderId; private String pid; private int amount; private String name; @Override public String toString() { return "orderId=‘" + orderId + ‘\‘‘ + ", pid=‘" + pid + ‘\‘‘ + ", amount=" + amount + ", name=‘" + name ; } public void setOrderId(String orderId) { this.orderId = orderId; } public void setPid(String pid) { this.pid = pid; } public void setAmount(int amount) { this.amount = amount; } public void setName(String name) { this.name = name; } public String getOrderId() { return orderId; } public String getPid() { return pid; } public int getAmount() { return amount; } public String getName() { return name; } //排序:先按照pid排序,再按照name排序 @Override public int compareTo(OrderBean o) { int compare = this.pid.compareTo(o.pid);//先比较pid if(compare == 0){ return o.name.compareTo(this.name); //比较名字 }else{ return compare; } } @Override public void write(DataOutput out) throws IOException { out.writeUTF(orderId); out.writeUTF(pid); out.writeInt(amount); out.writeUTF(name); } @Override public void readFields(DataInput in) throws IOException { this.orderId = in.readUTF(); this.pid = in.readUTF(); this.amount = in.readInt(); this.name = in.readUTF(); } }
package com.atguigu.reduceJoin; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; public class RJcomparator extends WritableComparator { protected RJcomparator(){ super(OrderBean.class,true); } //按照pid分组 @Override public int compare(WritableComparable a, WritableComparable b) { OrderBean oa =(OrderBean) a; OrderBean ob =(OrderBean) b; return oa.getPid().compareTo(ob.getPid()); } }
package com.atguigu.reduceJoin; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class RJdriver { public static void main(String[] args) throws Exception { Job job = Job.getInstance(new Configuration()); job.setJarByClass(RJdriver.class); job.setMapperClass(RJmapper.class); job.setReducerClass(RJreducer.class); job.setMapOutputKeyClass(OrderBean.class); job.setMapOutputValueClass(NullWritable.class); job.setOutputKeyClass(OrderBean.class); job.setOutputValueClass(NullWritable.class); job.setGroupingComparatorClass(RJcomparator.class); FileInputFormat.setInputPaths(job,new Path("E:\\input")); FileOutputFormat.setOutputPath(job,new Path("E:\\output")); boolean b = job.waitForCompletion(true); System.exit(b?0:1); } }
package com.atguigu.reduceJoin; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; public class RJmapper extends Mapper<LongWritable, Text,OrderBean, NullWritable> { private OrderBean orderBean= new OrderBean(); private String filename; @Override protected void setup(Context context) throws IOException, InterruptedException { FileSplit fs = (FileSplit)context.getInputSplit(); filename = fs.getPath().getName(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split(","); if (filename.equals("order.txt")){ orderBean.setOrderId(fields[0]); orderBean.setPid(fields[1]); orderBean.setAmount(Integer.parseInt(fields[2])); orderBean.setName(""); }else{ orderBean.setOrderId(""); orderBean.setPid(fields[0]); orderBean.setAmount(0); orderBean.setName(fields[1]); } context.write(orderBean,NullWritable.get()); } }
package com.atguigu.reduceJoin; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; public class RJreducer extends Reducer<OrderBean,NullWritable,OrderBean,NullWritable> { @Override protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { Iterator<NullWritable> iterator = values.iterator(); iterator.next(); String name = key.getName(); while(iterator.hasNext()){ iterator.next(); key.setName(name); context.write(key,NullWritable.get()); } } } /* orderid pid amount name null 01 null 小米 1001 01 1 null 1004 01 4 null */
原文:https://www.cnblogs.com/hapyygril/p/14012387.html