统计学(statistics):收集、处理、分析、解释数据并从数据中得出结论的科学。
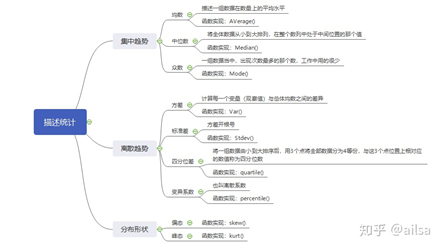
描述统计(discriptive statistics):研究的是数据收集、处理、汇总、图表描述、概括与分析等统计方法。
描述统计其实就是对数据进行总体特征的概述,例子:说一下班级这次考试的情况如何
推断统计(inferential statistics):是研究如何利用样本数据来推断总体特征的统计方法
推断统计其实是建立在描述统计的基础之上,在对总体数据有了大致的了解之后,运用一些分析方法,对数据进行预测,并达到统计决策的目的,其实不管是在统计学上,还是在实际的业务分析中,我们做分析的终极目的就是用来得出我们结论,应用于决策。例如:房价预测,通过预测数据来进行销售,用户看到房价走势,如果一路走高,是不是要提早下手
全过程最关键的一步,良好的开端是成功的一半 选题--明确研究目的--提出假设--明确总体范围--确立观察指标--控制研究中的偏移--给出具体的研究方案
收集数据,来源数据库,问卷等
数据整理非常重要,现在的数据处理工具也比较好用,一定要把数据清洗干净,数据清洗好了才能得出正确的结论
统计描述:了解样本数据的情况,是全部工作的基础,是尽量精确、直观而全面的对所获得的样本进行呈现
统计推断:从样本信息外推到总体,以获得对所感兴趣问题的解答
参数估计:样本-->所在总体特征
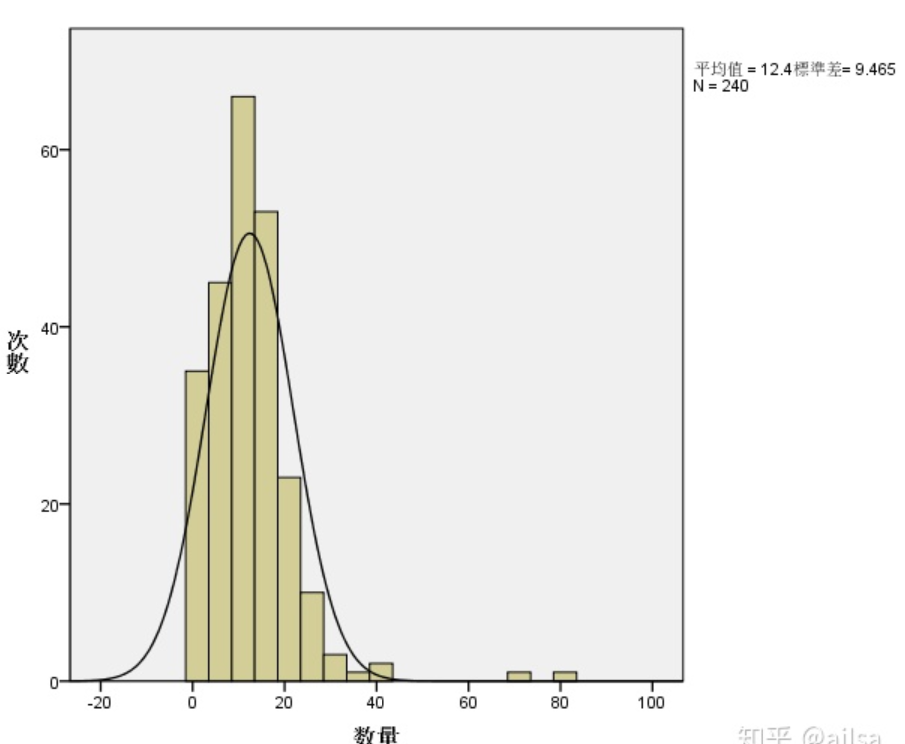
高峰组段在什么位置
均数(mean):总体均数和样本均数,受极值的影响很大
中位数(Median):将全体数据从小到大排列,在整个数列中处于中间位置的那个值就是中位数。不受极端值的影响,在具有个别极大或极小值的分布数列中,中位数比均数更具有代表性
中位数的应用场景:对于对称性的数据,优先均数,仅仅对于均数不能使用的情况才使用中位数加以描述。
众数:一组数据当中,出现次数最多的那个数,工作中用的很少
Excel怎么操作
使用函数,还有更方便的操作,讲完离散趋势再说
均数:average()
中位数:median()
众数:mode()
数据分布范围是什么,分散程度如何
离均差:x-μ 个体偏离均值的程度
总体方差:离均差平方和/样本量
总体标准差:方差开根号
样本标准差: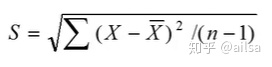
存在的问题:
1.测量尺度的相差太大:例如蚂蚁和大象的体重变异
2.计算单位不同:比较身高和体重的变异程度
变异系数 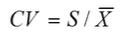
变异系数解决了不同样本变异程度对比的问题
配件A的变异系数 = 7.6/13.5 = 0.562963
维修费的变异系数 = 120.7/247.9 = 0.48689
二者有一定差异,但是差的不多,还算保持一致
百分位数: 是一个位置指标,用Px表示,一个百分位数Px将一组观察值分为两部分,理论上有x%的观察值比它小,有(100-x)%的观察值比它大,适用于各种分布
四分位数:P25、P50和P75分位数分别称作下四分位数,中位数 上四分位数
Excel怎么实现
使用函数
方差:var.s(num1,num2,....)
标准差:stdev.s(num1,num2,....)
变异系数:标准差/均值
百分位数:percentile.inc(array,k)
四分位数:quartile.inc(array,k)
是否对称,分布曲线的形状
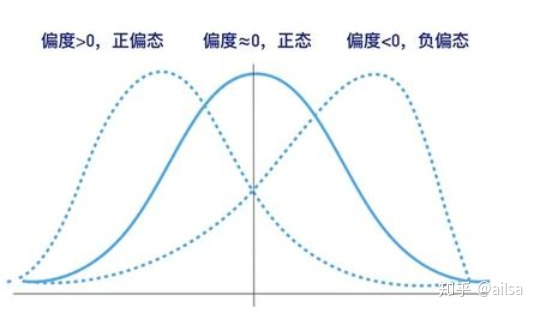
偏态 峰态
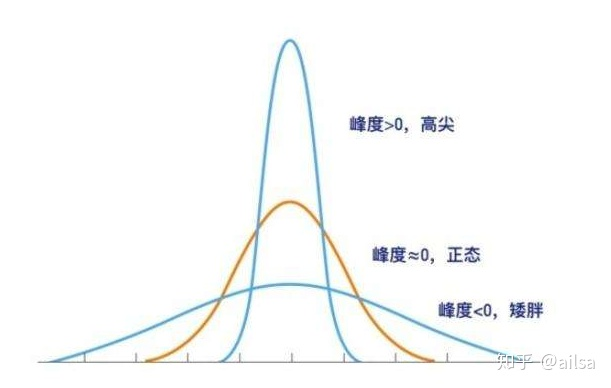
Excel怎么实现
使用函数
偏度:skew()
峰度:kurt()
原文:https://www.cnblogs.com/Teyisang/p/14013392.html