现在CPU都是多核cpu,且拥有多级缓存,如下图的CPU缓存模型
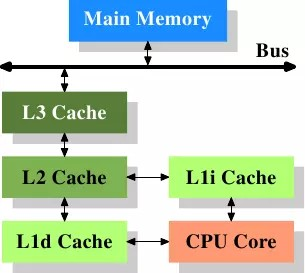
目前的CPU都是多核心的,每个核心都有自己的L1、L2缓存,当多个CPU同时操作同一份数据,就会出现缓存不一致的问题。
有两种解决方法:
第一种的话,如果cpu某核要做i++操作,会向总线上发出一个LOCK#信号,阻塞了其他cpu,锁定期间开销较大,所以一般不采用这种方法。
此时,MESI缓存一致性协议应运而生,分为四种状态
各种状态含义如下:
M:被修改的。处于这一状态的数据,只在本CPU中有缓存数据,而其他CPU中没有。同时其状态相对于内存中的值来说,是已经被修改的,且没有更新到内存中。
E:独占的。处于这一状态的数据,只有在本CPU中有缓存,且其数据没有修改,即与内存中一致。
S:共享的。处于这一状态的数据在多个CPU中都有缓存,且与内存一致。
I:无效的。本CPU中的这份缓存已经无效。
值得注意的是,TSO内存模型后来引入了storebuffer,变成如下
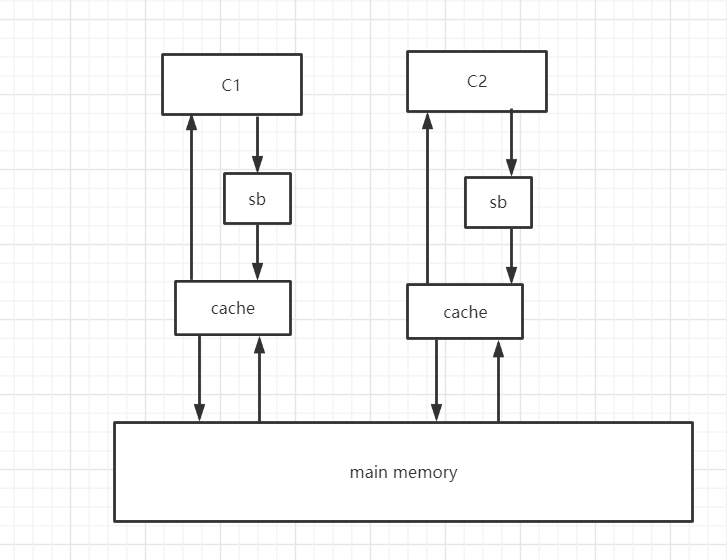
因为MESI缓存一致性协议,所以L1,L2,L3等CPU多级缓存被抽象成cache,那么为什么要加入storebuffer
原因:
从上面可以看出,MESI缓存一致性协议其实是保证了抽象cache的缓存一致性,而java中的volatile其实是通过内存屏障保证处理器到sb到L1缓存中间的防止指令的重排序导致不确定结果。
同时,volatile是java语言层面给出的保证,MESI缓存一致性协议只适用于L1/L2/L3 cache中,在storebuffer等影响下,仍然有重排序产生.
分析得比较浅显,本文仅仅是为自己复习起到抛砖引玉的作用。
原文:https://www.cnblogs.com/linjh-ccc/p/14013612.html