对一个测试工程师来说,测试用例的设计编写是一项必须掌握的能力,但有效的设计和熟练的编写测试用例却是一个十分复杂的技术,测试用例编写者不仅要掌握软件测试技术和流程,而且要对整个软件不管从业务,还是对软件的设计、程序模块的结构、功能规格说明等都要有透彻的理解。
测试的设计方法不是单独存在的,具体到每个测试项目里都有很多种方法,每种类型都有各自的特点。
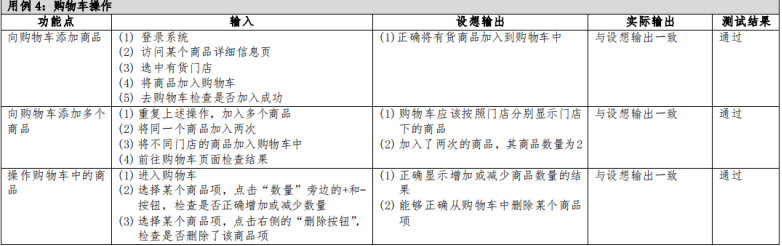
测试用例是执行测试的依据,把测试系统的操作步骤用文档的形式描述出来
(1)测试用例是为达到最佳的测试效果或高效的揭露隐藏的错误,而精心设计的少量测试数据,包括测试输入、执行条件和预期的结果,实际结果
(2)测试用例是执行的最小实体。
(3)测试用例是测试工作的指导,是软件测试的必须遵守的准则,更是软件测试质量稳定的根本保障
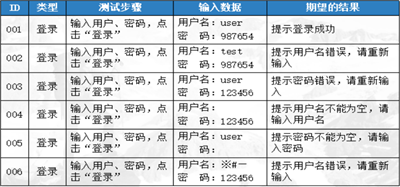
1、有效性:测试用例的能够被使用,且被不同人员使用测试结果一致
2、可重复性:良好的测试用例具有重复使用的功能。(回归测试)
3、易组织性:好的测试用例会分门别类地提供给测试人员参考和使用(功能、性能、易用分类编号)
4、清晰、简洁:好的测试用例描述清晰,每一步都应有相应的作用,有很强的的针对性,不应出现一些无用的操作步骤。
5、可维护性:由于软件开发过程中需求变更等原因的影响,常常对测试用例进行修改、增加、删除等,以便测试用符合相应测试要求。
在开始实施测试之前设计好测试用例,可以避免盲目测试并提高测试效率。
测试用例的使用令软件测试的实施重点突出、目的明确。
在软件版本更新后只需修正少部分的测试用例便可展开测试工作,降低工作强度、缩短项目周期。
检验软件是否满足客户需求、体现一个测试人员的工作量、展现测试用例的设计思路
代表性:能够代表并覆盖各种合理的和不合理、合法的和不合法的、边界的和越界的以及极限的输入数据、操作等。
针对性:对程序中的可能存在的错误有针对性地测试
可判定性:测试执行结果的正确性是可判定的,每一个测试用例都应有相应的期望结果
可重现性:对同样的测试用例,系统的执行结果应当是相同的。
用例编号、测试模块、用例标题、用例级别、测试环境、测试输入、执行操作、预期结果,实际结果….
应用场景:多用于输入框
有效,无效
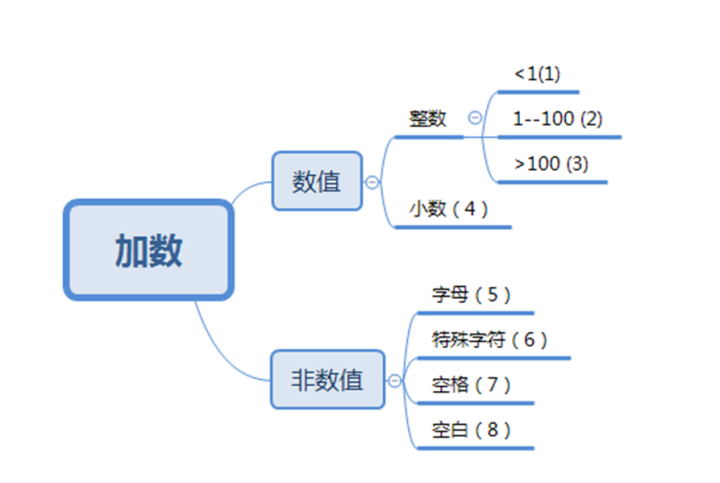
等价类划分是指分步骤地把海量(无限)的测试用例集减得很小,但过程同样有效。
等价类 :何为等价类,某个输入域的集合,在这个集合中每个输入条件都是等效的。
一般可分为有效等价类和无效等价类
比如:一个青少年考试的分数(备注13-17岁为青少年)
假设青少年年龄为x,13<=x<=17,数学成绩为y:0<=y<=100
那么年龄按照等价类划分可分为x<13,13<=x<=17,x>17,有效等价类是13<=x<=17,无效等价类是x<13,x>17
数学成绩按照等价类划分可分为y<0,0<=y<=100,y>100,有效等价类是0<=y<=100,无效等价类是y<0,y>100
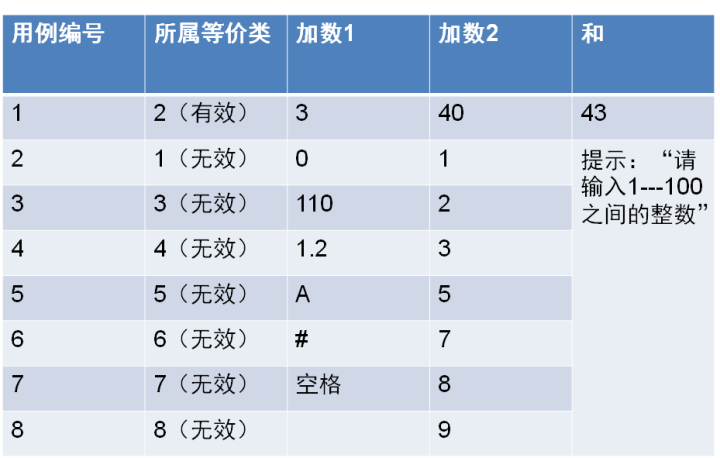
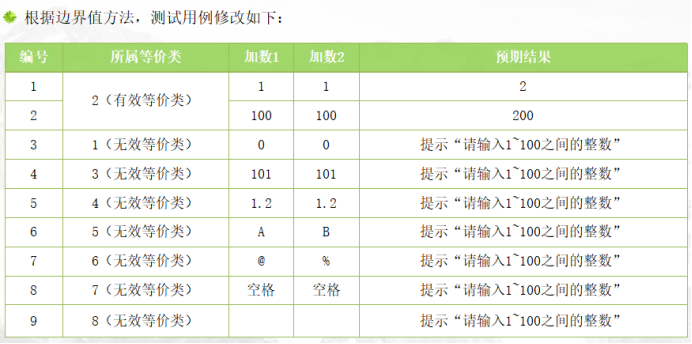
计算两个1~100之间整数的和。
如果要进行完全测试,一共要设计多少个测试用例呢?
加数1有1~100共计100个取值,加数2也有1~100共计100个取值,所以他们之间的组合就有100*100=10000种组合可能,但这只是测试了正常范围内的取值。如果用户输入的数据不在1~100之间呢,穷举测试肯定不可能的。由此引入了等价类划分思想。
等价类划分为:
有效等价类:指符合《需求规格说明书》,输入合理的数据集合
无效等价类:指不符合《需求规格说明书》,输入不合理的数据集合

我们将输入域分成了一个有效等价类(1~100)和两个无效等价类(<1,>100),并为每一个等价类进行编号,然后我们就可以从每一个等价类中选取一个代表性的数据来测试,设计如下表所示的测试用
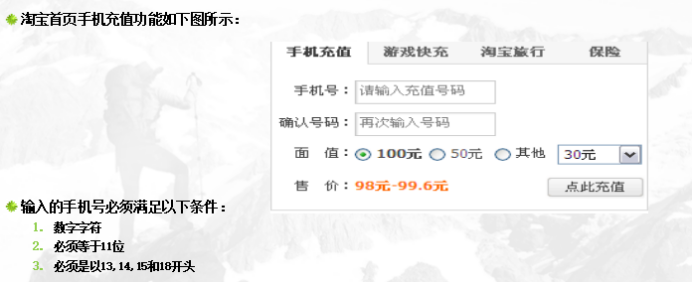
划分等价类并编号,下表为等价类划分的结果

一般边界值分析是因为程序开发循环体时的取数可能会因为<,<=搞错。
比如下面代码
for(int i = 0;i <100; i ++)
{
int j = i+1;
System.out.println("循环第“+j+"次")//循环地做某件事情
}
这里的程序是循环了100次,所以会做100次;
如果程序员不小心,把i <100写成i <= 100,则多循环添加一次,这时候边界值检查是一个很好的测试方法。
比如:在一个系统中,填写一个多少岁的青少年考了多少分(假设成年人年龄为x,13<=x<=17,数学成绩为y:0<=y<=100
根据上面的等价类划分法我们可知,年龄的有效等价类是13<=x<=17,所以边界值就是12, 18
数学成绩的,有效等价类是0<=y<=100,所以边界值就是-1,0,100,101
对数据进行软件测试,就是在检查用户输入的信息、返回的结果以及中间计算结果是否正确。即使最简单的程序要处理的数据量也可能极大,使这些数据得以测试的技巧是,根据一些关键的原则进行等价类的划分,以合理减少测试用例,这些关键的原则是:边界条件,次边界条件、空值和无效数据。
选取正好等于、刚刚大于或刚刚小于边界值作为测试数据
输入要求是1 ~ 100之间的整数,因此自然产生了1和100两个边界,我们在设计测试用例的时,要重点考虑这两个边界问题。
[1 100] 上点1 ,100 离点 0 101所属
(1,100) 上点 2,99 离点 1 ,100
(1,100] 上点 2,100 离点 1 ,101
因果图法比较适合输条件比较多的情况,测试所有的输入条件的排列组合。所谓的原因就是输入,所谓的结果就是输出。
恒等:若原因出现,则结果出现;若原因不出现,则结果不出现。
非(~):若原因出现,则结果不出现;若原因不出现,则结果出现。
或(∨):若几个原因中有一个出现,则结果出现;若几个原因都不出现,则结果不出现。
与(∧):若几个原因都出现,结果才出现;若其中有一个原因不出现,则结果不出现。

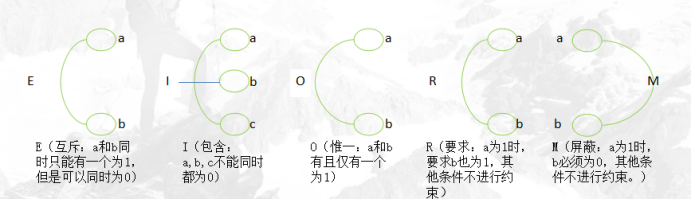
E(互斥):表示两个原因不会同时成立,两个中最多有一个可能成立
I(包含):表示三个原因中至少有一个必须成立
O(惟一):表示两个原因中必须有一个,且仅有一个成立
R(要求):表示两个原因,a出现时,b也必须出现,a出现时,b不可能不出现
M(屏蔽):两个结果,a为1时,b必须是0,当a为0时,b值不定
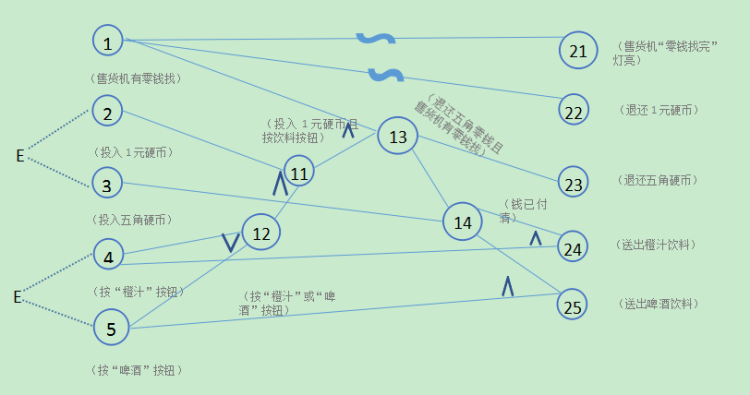
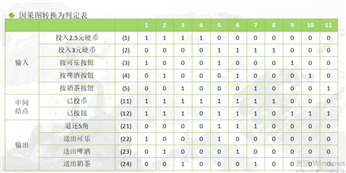
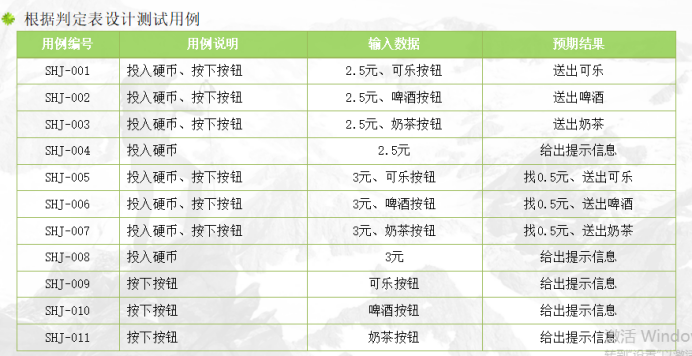
例如:有一个处理单价为2.5元的盒装饮料的自动售货机软件。若投入2.5元硬币,按“可乐”、“啤酒”、或“奶茶”按钮,相应的饮料就送出来。若投入的是3元硬币,在送出饮料的同时退还5角硬币。
分析这一段说明,我们可列出原因和结果
原因(输入):
投入2.5元硬币;
投入3元;
按“可乐”按钮;
按“啤酒”按钮;
按“奶茶”按钮。
中间状态: ① 已投币;②已按钮
结果(输出):
退还5角硬币;
送出“可乐”饮料;
送出“啤酒”饮料;
送出“奶茶”饮料;
现在的软件几乎都是用事件触发来控制流程的,事件触发时的情景便形成了场景,而同一事件不同的触发顺序和处理结果就形成事件流。这种在软件设计方面的思想也可以引入到软件测试中,可以比较生动地描绘出事件触发时的情景,有利于测试设计者设计测试用例,同时使测试用例更容易理解和执行。
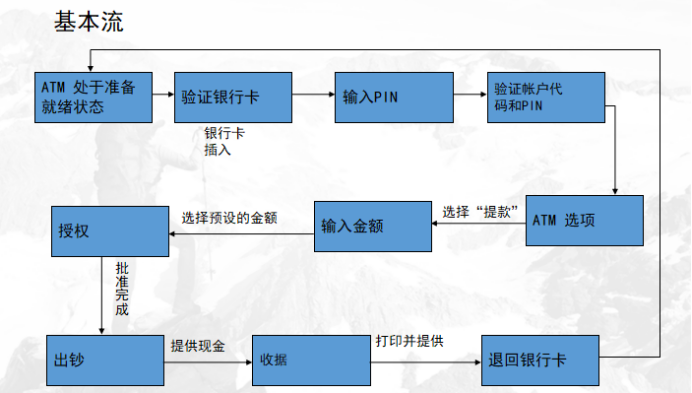
用例场景是通过描述流经用例的路径来确定的过程,
这个流经过程要从用例开始到结束遍历其中所有基本流和备选流。
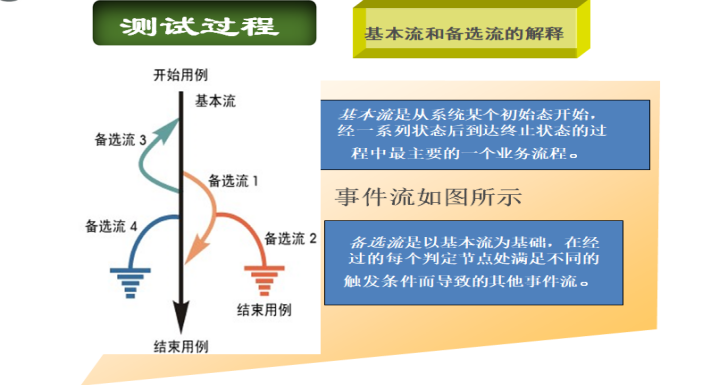
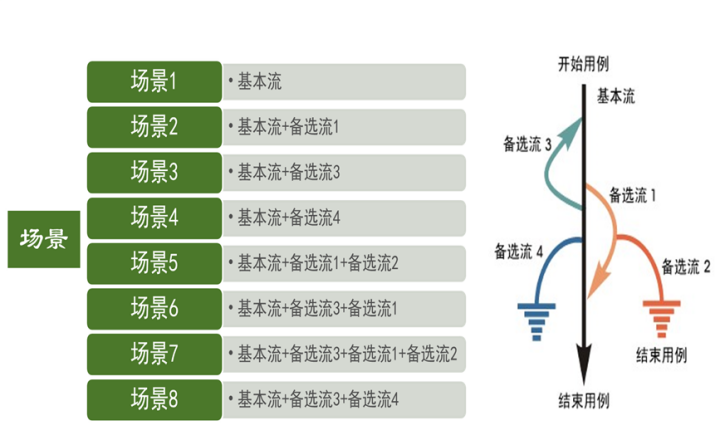
基本流和备选流的区别
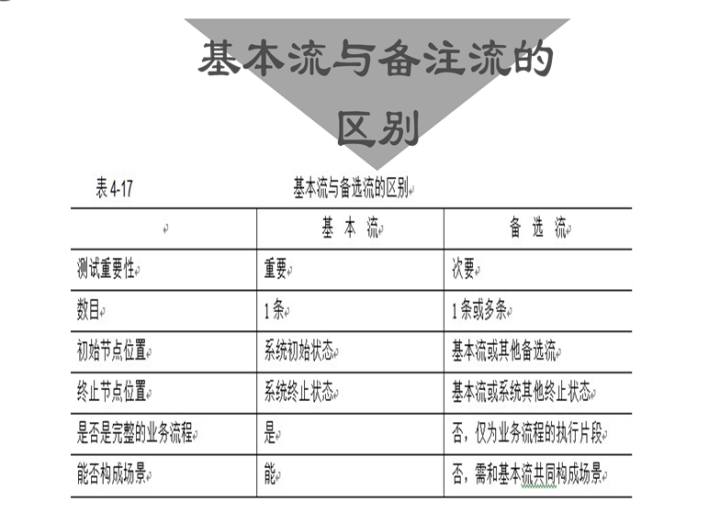
个人标识号 (PIN=personal identification number ),用于保护智能卡免受误用的秘密标识代码。PIN 与密码类似,只有卡的所有者才知道该 PIN。只有拥有该智能卡并知道 PIN 的人才能使用该智能卡
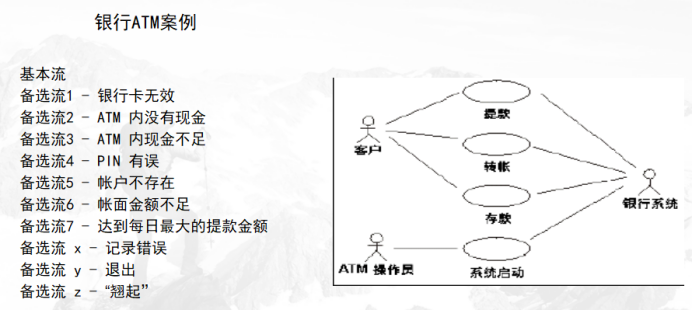
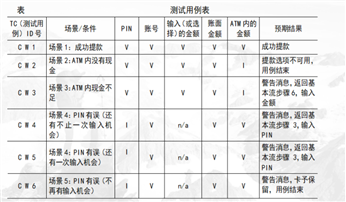
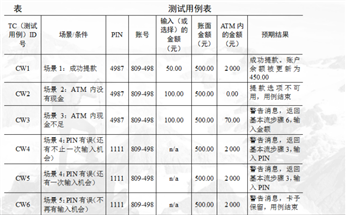
第一次测试中,根据测试计划,我们需要核实提款用例已经正确地实施。此时尚未实施整个用例,只实施了下面的事件流:
基本流-提取预设金额(100 元、200元、500元、1000元)
备选流2 - ATM 内没有现金
备选流3 - ATM 内现金不足
备选流4 - PIN 有误
备选流5 - 帐户不存在/帐户类型有误
备选流6 - 帐面金额不足
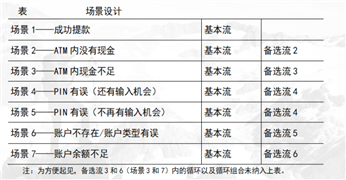
对于这7个场景中的每一个场景都需要确定测试用例。可以采用矩阵或决策表来确定和管理测试用例。
从确定执行用例场景所需的数据元素入手构建矩阵。然后,对于每个场景,至少要确定包含执行场景所需的适当条件的测试用例。
下面显示了一种通用格式,其中各行代表各个测试用例,而各列则代表测试用例的信息。
本示例中,对于每个测试用例,存在一个测试用例ID、条件(或说明)、测试用例中涉及的所有数据元素(作为输入或已经存在于数据库中)以及预期结果。
错误猜测法是测试经验丰富的人喜欢使用的一种测试用例设计方法。
一般这种方法是基于经验和直觉推测程序中可能发送的各种错误,有针对性地设计。只能作为一种补充。
例如,测试手机终端的通话功能,可以设计各种通话失败的情况来补充测试用 例:
1) 无SIM 卡插入时进行呼出(非紧急呼叫)
2) 插入已欠费SIM卡进行呼出
3) 射频器件损坏或无信号区域插入有效SIM卡呼出
4) 网络正常,插入有效SIM卡,呼出无效号码(如1、888、333333、不输入任何号码等)
5) 网络正常,插入有效SIM卡,使用“快速拨号”功能呼出设置无效号码的数字
技巧:最重要的是要思考和分析测试对象的各个方面,多参考以前发现的bug的相关数据,总结的经验,个人多考虑异常的情况、反面的情况、特殊的输入,以一个攻击者的态度对待程序,就能设计出比较完善的测试用例来。
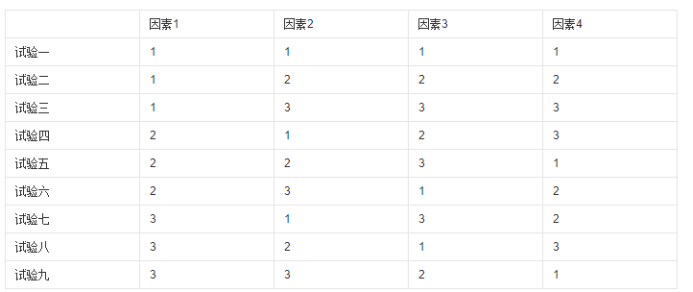
正交实验法就是利用排列整齐的表 -正交表来对试验进行整体设计、综合比较、统计分析,实现通过少数的实验次数找到较好的生产条件,以达到最高生产工艺效果,这种试验设计法是从大量的试验点中挑选适量的具有代表性的点,利用已经造好的表格—正交表来安排试验并进行数据分析的方法。正交表能够在因素变化范围内均衡抽样,使每次试验都具有较强的代表性,由于正交表具备均衡分散的特点,保证了全面实验的某些要求,这些试验往往能够较好或更好的达到实验的目的。正交实验设计包括两部分内容:第一,是怎样安排实验;第二,是怎样分析实验结果。
应用场景:在一个界面中有多个控件,每个控件有多个取值,控件之间可以相互组合,不可能(也没有必要)为每一种组合编写一条用例,如何使用最少最优的组合进行测试。——正交排列法
判定表,因果图也是考虑控件组合,但是组合数量较少(一般不会超过20中)
公式:Ln(mk)
k是表的列数,表示控件的个数(因数个数)
m是每个控件的取值个数(因数水平)
n是表的行数,也就是需要测试组合的次数
正交表查询地址:https://www.york.ac.uk/depts/maths/tables/orthogonal.htm
正交排列法:http://support.sas.com/techsup/technote/ts723_Designs.txt


|
编号 |
字体 |
字符样式
|
颜色 |
字号 |
|
1 |
仿宋 |
粗体 |
红色 |
20 |
|
2 |
仿宋 |
斜体 |
绿色 |
30 |
|
3 |
仿宋 |
下划线 |
蓝色 |
40 |
|
4 |
楷体 |
粗体 |
绿色 |
40 |
|
5 |
楷体 |
斜体 |
蓝色 |
20 |
|
6 |
楷体 |
下划线 |
红色 |
30 |
|
7 |
华文彩云 |
粗体 |
蓝色 |
30 |
|
8 |
华文彩云 |
斜体 |
红色 |
40 |
|
9 |
华文彩云 |
下划线 |
绿色 |
20 |

正交表测试用例设计方法的特点是什么?
1、用最少的实验覆盖最多的操作,测试用例设计很少,效率高,但是很复杂;
2、对于基本的验证功能,以及二次集成引起的缺陷,一般都能找出来;但是更深的缺陷,更复杂的缺陷,还是无能为力的;
3、体的环境下,正交表一般都很难做的。大多数,只在系统测试的时候使用此方法。
测试用例并非一成不变。如果软件修改之后发生变化,或者需求发生变更,那么测试用例便不再满足当前版本软件的测试需求,由此需要进行修改和变更操作。
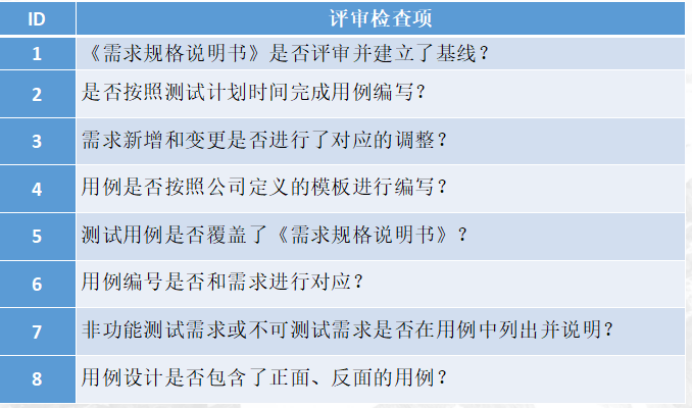
首先要清楚内部评审的定义,是测试组内部的评审,还是项目组内部的评审。评审的定义不同,内容也不会相同。
如果是测试组内部的评审,应该着重于:
1.测试用例本身的描述是否清晰;
2.是否考虑到测试用例的执行效率.往往测试用例中步骤不断重复执行,验证点却不同,而且测试设计的冗(rong)余性,都造成了效率的低下;
3.是否针对需求文档,测试用例是否覆盖了所有的软件需求;
4.是否完全遵守了软件需求的规定。这并不一定的,因为即使再严格的评审,也会出现错误,应具体情况具体对待。
如果是项目组内部的评审,也就需要评审委员会来做了,角度不同,评审的标准也不同。比如收集客户需求的人员注重你的业务逻辑是否正确,分析软件需求规格的人注重你的用例是否跟规格要求一致,开发负责人会注重你的用例中对程序的要求是否合理。
测试用例的评审能够使用例的结构更清晰,覆盖的用户场景更全面对于测试工程师来说也是一个快速提高用例设计能力的过程。
1、需要评审的原因
测试用例是软件测试的准则,但它并不是一经编制完成就成为准则。由于用例开发人员的设计经验和对需求理解的深度各不相同,所以用例的质量难免会有不同程度的差异。
2、进行评审的时机
一般会有两个时间点。第一,是在用例的初步设计完成之后进行评审第二是在整个详细用例全部完成之后进行二次评审。如果项目时间比较紧张,尽可能保证对用例设计进行评审,提前发现其中的不足之处。
3、参与评审人员
这里会分为多个级别进行评审。
1)部门评审,测试部门全体成员参与的评审。
2)公司评审,这里包括了项目经理、需求分析人员、架构设计人员、开发人员和测试人员。
3)客户评审,包括了客户方的开发人员和测试人员。这种情况在外包公司比较常见。
4、评审内容
评审的内容有以下几个方面
1)用例设计的结构安排是否清晰、合理,是否利于高效对需求进行覆盖。
2)优先极安排是否合理。
3)是否覆盖测试需求上的所有功能点。
4)用例是否具有很好可执行性。例如用例的前提条件、执行步骤、输入数据和期待结果是否清晰、正确期待结果是否有明显的验证方法。
5)是否已经删除了冗余的用例。
6)是否包含充分的反面测试用例。充分的定义,如果在这里使用2&8法则,那就是4倍于正面用例的数量,毕竟一个健壮的软件,其中80%的代码都是在"保护"20%的功能实现。
7)是否从用户层面来设计用户使用场景和使用流程的测试用例。
8)是否简洁,复用性强。例如,可将重复度高的步骤或过程抽取出来定义为一些可复用标准步骤。
5、评审的方式
1)召开评审会议。与会者在设计人员讲解之后给出意见和建议,同时进行详细的评审记录。
2)通用邮件与相关人员沟通
3)通用IM(办公通讯)工具直接与相关人员交流
方式只是手段,得到其它人员对于用例的反馈信息才是目的。
无论采用那种方式,都应该在沟通之前把用例设计的相关文档发送给对方进行前期的学习和了解,以节省沟通成本。
6、评审结束标准
在评审活动中会收集到用例的反馈信息,在此基础上进行用例更新,直到通过评审。

原文:https://www.cnblogs.com/daiju123/p/14017251.html