大数据目标检测推理管道部署
本文提供了一个用于对象检测的深度学习推理的概述。
自主车辆软件开发需要大规模的数据、计算和算法创新,这些都是gpu实现的。一组神经网络构成了感知和决策系统的基础。神经网络的性能与数据量成比例地增加,并且需要基础设施来支持大规模的训练和推理。
为了使自动驾驶汽车(AV)达到可接受的安全水平,他们必须接受大量真实驾驶数据的训练,这些数据包括汽车每天可能遇到的各种情况。这些训练场景由安装有多个传感器的车队收集,每天行驶小时,产生数PB的数据。这些数据必须加以标注和处理,以便进行全面的AV开发、测试和验证。
AV软件的很大一部分是perception stack,它使车辆能够检测、跟踪和分类物体并估计距离。perception算法开发人员可以创建高性能和健壮的算法,这些算法能够在任何场景下准确检测车辆、车道、静态和移动对象、行人、交叉口的红绿灯和交叉口。场景包括各种环境条件,包括隧道内,漆黑的高速公路上,或在刺眼的阳光下。为了使这些算法有效工作,它们需要稳定的高质量、带标注或标记的数据流入训练。
检测的目标不仅是确定目标在单个帧中的位置,而且是确定目标在帧内的位置。对象需要在正确的类中进行标识、分类和标记。可以通过一个边界框来实现这些目标,该框不仅可以标识对象,还可以确定对象的位置以及置信度。
传统上,标注或标记大多被认为是一项手动任务。然而,人工智能可以加速数据标记过程。人工智能模型可以生成预标注,然后由人工标注器对其进行审查和扩充,以提高精度并创建高质量的训练数据集。
Object detection inference pipeline components
gpu正在为自主车辆软件开发提供动力,这是由数据量、算力和算法创新驱动的。一组神经网络构成了感知和决策系统的基础。神经网络性能的提高与数据量成正比,并且需要整体架构来支持大规模的训练和推理。
数据集
数据架构
系统配置
Dataset
图1显示了一个包含23个自动驾驶会话的数据集在不同场景中进行推理的详细信息。
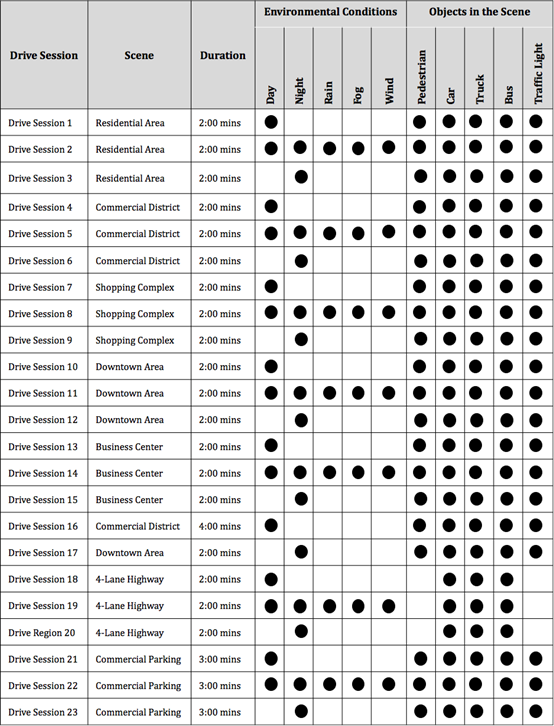
Figure 1. Dataset distribution.
除了环境元素和用于检测的主要目标的变化外,下表显示了在ego本车辆和场景中使用的摄影机的属性集。
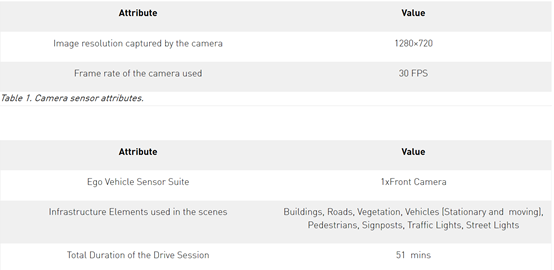
Table 2. Scene attributes.
Data schema
数据集有时间戳,包含来自摄像头传感器的原始数据、校准值、姿态轨迹和groundtruth真实姿态。groundtruth真实数据能够验证目标检测推理输出,并有助于解释和分析收集到的指标。
数据模式提供有关基本groundtruth数据的格式和结构的信息。数据客观地说明有关目标定位和分类的信息。它包含目标的精确坐标,以及给定数据集中每个图像的类别。
本文对检测特定目标感兴趣。
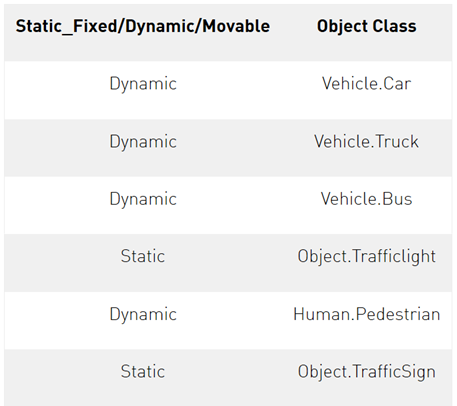
Table 3. Object ontology.
图2显示了groundtruth文件的结构。
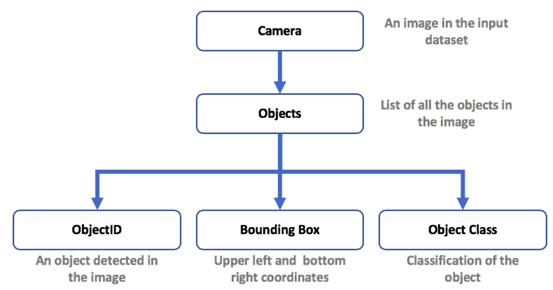
Figure 2. Ground truth structure.

Figure 3. Ground truth JSON for different object types.
System configuration
表4中的配置在单个CPU和一个或多个GPU上运行深度学习推理。
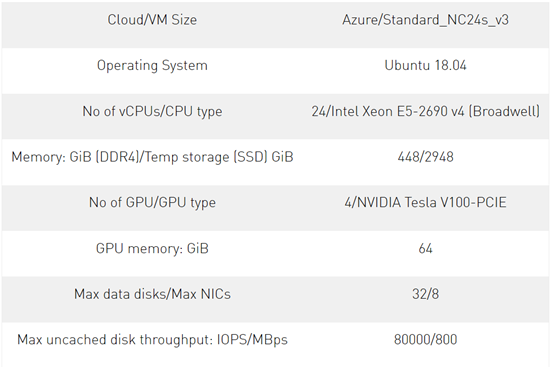


Table 4. System configuration.
Pre-annotation using YOLOv3
深度学习是一种最先进的方法,主要由数据可用性和算力驱动来执行目标检测。许多其他细节,如神经网络架构,也很重要,在过去的几年里有很多创新。
有相当多的模型推动了目标检测的发展,例如更快的基于区域的卷积神经网络(更快的RCNN)、只看一次模型(YOLO)和单次多盒检测器(SSD)。哪种模式是最好的还没有明确的答案。对于标注前的对象检测需要,您可以选择平衡精度和速度。
对于这篇文章,我们选择了YOLOv3算法,它是最有效的目标检测算法之一。它还包含了许多在整个计算机视觉文献中与目标检测相关的最佳思想。Darknet-53作为YOLOv3的主干,YOLOv3以图像为输入,提取特征映射。YOLOv3是一种多类对象检测模型,是一种单级检测器,可减少延迟。
图4描述了YOLOv3算法的体系结构。检测层包含许多回归和分类优化器,boundingbox的数量决定了用于直接检测对象的层数。它是一个单一的神经网络,可以在一次评估中从完整图像中预测边界框和类概率。由于整个检测管道是一个单一的网络,因此可以根据检测性能进行端到端的优化。
图4显示了yolov3在三个尺度上进行预测。13×13层负责检测大对象,26×26层检测中等对象,52×52层检测较小对象。
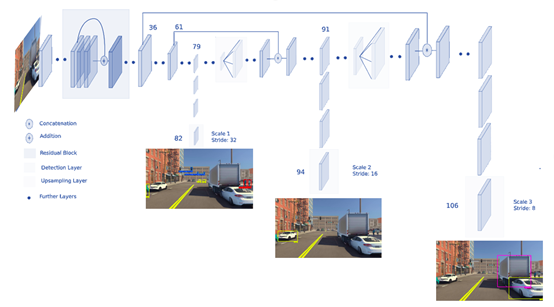
Figure 4. YOLOv3 network architecture.
Object detection inference pipeline overview
预标注模型位于对象检测推理管道的核心。在MS-COCO测试设备上,使用一个mAP(平均精度)为55.3的预训练YOLOv3-416模型,在MS-COCO测试设备上以0.5iou进行测量。从PyTorch-yolov3 github repo下载配置文件和预训练的权重文件。使用Pythorch神经网络框架进行推理。使用Docker容器设置环境,并将其打包以便在不同的环境中运行。
导入后,数据集进入预处理阶段进行必要的转换。数据集中1280×720幅图像的纵横比保持不变。图像大小调整为416×234并填充到416×416,然后插入416×416网络。所有图像的高度和宽度都固定,便于批量处理。批量图像可以由GPU并行处理,从而提高速度。
预标注模型自动覆盖直接的标注,通过降低标注强度简化人工标注者的工作。预标注有助于引导人工标注过程。随后的步骤是迭代的,包括一轮或多轮质量检查。随着时间的推移,基于深度学习的预标注器通过不断地从人工标注者审查过的标注集合中学习而逐渐变得更好。
一个有效的对象检测推理管道在驱动一致性和高质量的标记输出方面有很大的帮助。
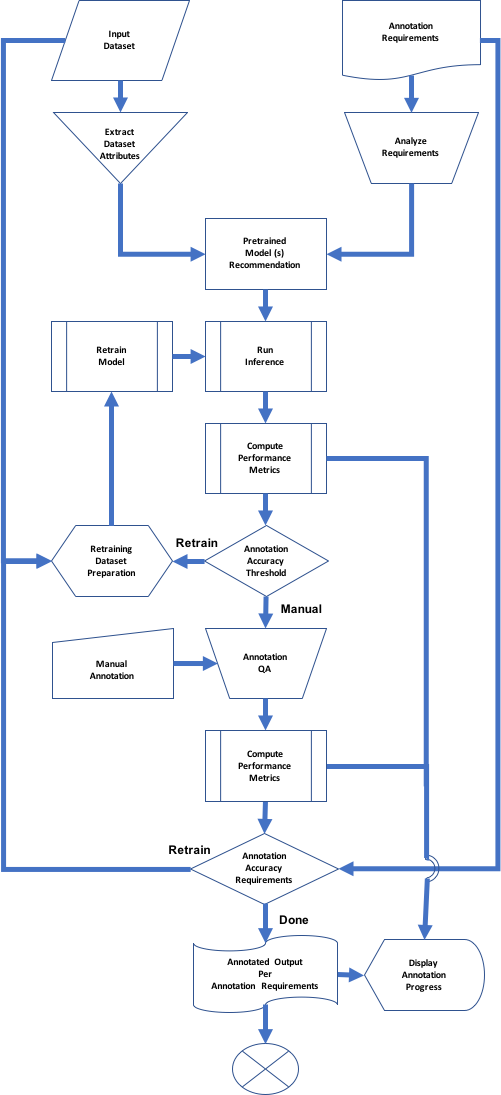
Figure 5. Annotation pipeline template.
Summary
自动驾驶汽车承诺为所有人提供更安全、更高效的交通工具。对物体(包括车辆、行人、交通标志和红绿灯)的精确检测可以帮助自动驾驶汽车像人类一样安全地驾驶。大量数据和各种驾驶交互数据的标注对于训练和构建最先进的检测系统是必要的。
原文:https://www.cnblogs.com/wujianming-110117/p/14022640.html