Tensorflow中的CNN变数很少,而RNN却丰富多彩,不仅在RNN Cell上有很多种、在实现上也有很多种,在用法上更是花样百出。
五个基本的RNN Cell:
RNN Cell的封装和变形:
四种架构:
(static+dynamic)*(单向+双向)=4
四种用法:
(one+many)*(one+many)=4
下面主要讨论一下static_rnn和dynamic_rnn。
static_rnn和dynamic_rnn的区别主要在于实现不同。
static_rnn会把RNN展平,用空间换时间。
dynamic_rnn则是使用while循环。
因为实现上的差异,导致了二者用法差异:
因为实现上的差异,二者的输入输出也略有不同。
static_rnn接受的输入是<帧数,batchSize,帧大小>的输入,也就是“帧数”个形如<batchSize,帧大小>的张量。因此在输出上,需要取其outputs[-1]作为RNN最终的输出。static_rnn需要对普通的输入做一些转换:
x_transposed = tf.transpose(x_place, (1, 0, 2))
x_sequence = tf.unstack(x_transposed)
rnn_cell = tf.nn.rnn_cell.LSTMCell(rnn_units)
initial_state = rnn_cell.zero_state(tf.shape(x_place)[0], dtype=tf.float32)
rnn_out, states = tf.nn.static_rnn(rnn_cell, x_sequence, initial_state=initial_state)dynamic_rnn接受的输入则是普通的<batchSize,帧数,帧大小>张量。输出上需要取其outputs[:,-1,:]作为最终输出。
那么问题来了。static_rnn和dyanmic_rnn的使用场景是什么?二者有何利弊。
从直觉上很容易觉察到,动态RNN在功能上有很多优势(允许样本长度不同),然而天下没有免费的午餐,静态RNN肯定有动态RNN不具备的优势,否则静态RNN早就该废弃了。静态RNN会把RNN展开成多层,这样似乎相当于用空间换时间。动态RNN使用while循环,这样相当于用时间换空间。静态RNN在运行速度上会比动态RNN快。
在MNIST数据集上,在隐层RNN个数相同的情况下,比较静态RNN和动态RNN的运行效率。
实验详情:
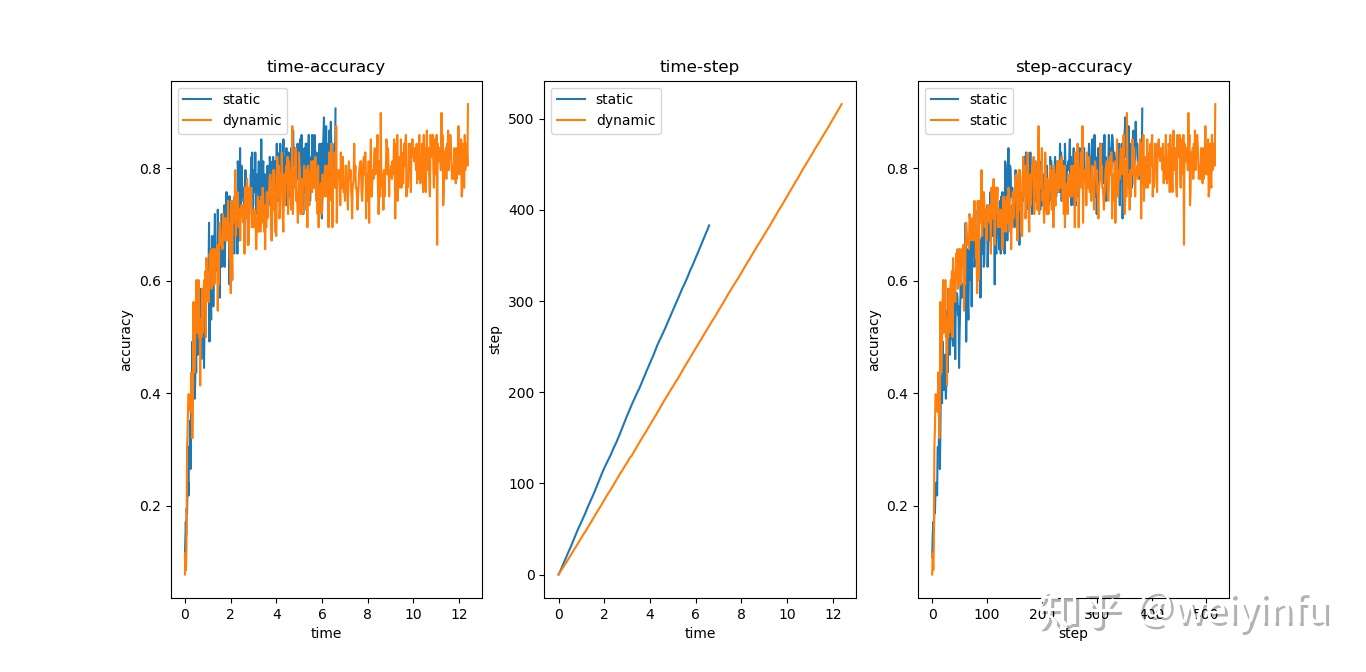
观察此图可以发现:
因此有以下结论:
实验代码如下:
import time
import numpy as np
import pylab as plt
import tensorflow as tf
from keras.datasets import mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data(‘/data/mnist.npz‘)
sz = 28
category_count = 10
rnn_units = 32
class DataIterator:
def __init__(self, batch_size):
self.index = np.arange(len(train_x))
np.random.shuffle(self.index)
self.now = 0
self.batch_size = batch_size
def get_batch(self):
if self.now + self.batch_size > len(self.index):
np.random.shuffle(self.index)
self.now = 0
ind = self.index[self.now:self.now + self.batch_size]
self.now += self.batch_size
return train_x[ind], train_y[ind]
def use_static_rnn(x_place):
x_transposed = tf.transpose(x_place, (1, 0, 2))
x_sequence = tf.unstack(x_transposed)
rnn_cell = tf.nn.rnn_cell.LSTMCell(rnn_units)
initial_state = rnn_cell.zero_state(tf.shape(x_place)[0], dtype=tf.float32)
rnn_out, states = tf.nn.static_rnn(rnn_cell, x_sequence, initial_state=initial_state)
return rnn_out[-1]
def use_dynamic_rnn(x_place):
cell = tf.nn.rnn_cell.LSTMCell(num_units=rnn_units)
init_state = cell.zero_state(tf.shape(x_place)[0], dtype=tf.float32)
outputs, states = tf.nn.dynamic_rnn(cell, x_place, initial_state=init_state)
return outputs[:, -1, :]
def main(rnn):
tf.reset_default_graph()
x_place = tf.placeholder(dtype=tf.float32, shape=(None, sz, sz))
y_place = tf.placeholder(dtype=tf.int32, shape=(None))
rnn_out = rnn(x_place)
y = tf.reshape(rnn_out, (-1, rnn_units))
w = tf.Variable(tf.random_normal((rnn_units, category_count)))
b = tf.Variable(tf.random_normal((category_count,)))
logits = tf.matmul(y, w) + b
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=y_place))
train_op = tf.train.AdamOptimizer(0.01).minimize(loss)
mine = tf.argmax(logits, axis=1, output_type=tf.int32)
right_or_wrong = tf.cast(tf.equal(mine, y_place), tf.float32)
accuracy = tf.reduce_mean(right_or_wrong, axis=0)
right_count = tf.reduce_sum(right_or_wrong, axis=0)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
data_it = DataIterator(128)
beg_time = time.time()
acc_series = []
step_series = []
for i in range(int(1e8)):
batch_x, batch_y = data_it.get_batch()
_, lo, acc = sess.run([train_op, loss, accuracy], feed_dict={
x_place: batch_x,
y_place: batch_y,
})
print(‘method‘, rnn.__name__, ‘global step‘, i, ‘loss‘, lo, ‘accuracy‘, acc, ‘time used‘, time.time() - beg_time)
acc_series.append((acc, time.time() - beg_time))
step_series.append((i, time.time() - beg_time))
if acc > 0.90:
break
batch_size = 128
s = 0
for i in range(0, len(test_y), batch_size):
batch_x, batch_y = test_x[i:i + batch_size], test_y[i:i + batch_size]
cnt, acc = sess.run([right_count, accuracy], feed_dict={
x_place: batch_x,
y_place: batch_y,
})
s += cnt
print(‘test accuracy‘, s / len(test_y))
acc_series = np.array(acc_series)
acc_series[:, 1] -= acc_series[0, 1] # 时间以第一次训练结束时间为准
step_series = np.array(step_series)
step_series[:, 1] -= step_series[0, 1]
return acc_series, step_series
acc_series1, step_series1 = main(use_static_rnn)
acc_series2, step_series2 = main(use_dynamic_rnn)
fig, (one, two) = plt.subplots(1, 2)
one.set_title(‘time-accuracy‘)
one.plot(acc_series1[:, 1], acc_series1[:, 0], label=‘static‘)
one.plot(acc_series2[:, 1], acc_series2[:, 0], label=‘dynamic‘)
one.set_xlabel(‘time‘)
one.set_ylabel(‘accuracy‘)
one.legend()
two.set_title(‘time-step‘)
two.plot(step_series1[:, 1], step_series1[:, 0], label=‘static‘)
two.plot(step_series2[:, 1], step_series2[:, 0], label=‘dynamic‘)
two.set_xlabel(‘time‘)
two.set_ylabel("step")
two.legend()
plt.show()
tf.nn.dynamic_rnn 函数是tensorflow封装的用来实现递归神经网络(RNN)的函数,本文会重点讨论一下tf.nn.dynamic_rnn 函数的参数及返回值。 首先来看一下该函数定义: tf.nn.dynamic_rnn( …
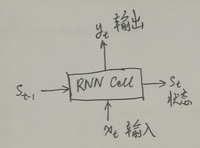

以下内容参考、引用部分书籍、帖子的内容,若侵犯版权,请告知本人删帖。 训练RNN的关键是将其按时序展开,然使用常用的反向传播即可,这种策略被称为时序反向传播( backpropagation throug…
原文:https://www.cnblogs.com/cx2016/p/14035475.html
3 条评论
发自知乎 For Windows 10
rnn是循环的,不管静态动态都要等上一个时间步算完之后,才能用上个时间步的结果计算下个时间步,动态的时间步长不同,那么不用取最长时间步,反而会更快一些,用空间换时间,应该只是在存储上空间变大,在计算顺序上并没有节省时间。