(18 条消息) 自然语言处理(NLP):24 基于文本语义的智能问答系统_aiwen2100-CSDN 博客本文分享主题:Faiss 和 bert 提供的模型实现了一个中文问答系统。旨在提供一个用 Faiss 结合各种 AI 模型实现语义相似度匹配的解决方案。
问答系统是自然语言处理领域一个很经典的问题,它用于回答人们以自然语言形式提出的问题,有着广泛的应用。
经典应用场景包括:智能语音交互、在线客服、知识获取、情感类聊天等。
常见的分类有:生成型、检索型问答系统;单轮问答、多轮问答系统;面向开放领域、特定领域的问答系统。
本文涉及的主要是在检索型、面向特定领域的问答系统 **——智能客服机器人。**
传统客服机器人的搭建流程
通常需要将相关领域的知识(Domain Knowledge),转化为一系列的规则和知识图谱。构建过程中重度依赖 “人工” 智能,换个场景,换个用户都需要大量的重复劳动。

深度学习 - 智能问答机器人
深度语言模型会将问题和文档转化为语义向量,从而找到最后的匹配答案。本文借助 Google 开源的 Bert 模型结合 Faiss 开源向量搜索引擎,快速搭建基于语义理解的对话机器人。
案例分享:FAQ 问答机器人
FAQ 是 Frequently Asked Questions 的简称。假定我们有一个常见问题和答案的数据库,现在用户提出了一个新问题,能不能自动从常见问题库中抽取出最相关的问题和答案来作答呢?在这个项目中,我们会探索如何构建这样问答机器人。
项目核心技术点:
结合 Faiss 和 bert 提供的模型实现了一个中文问答系统。旨在提供一个用 Faiss 结合各种 AI 模型实现语义相似度匹配的解决方案。最后通过项目案例实现:文本语义相似度文本检索系统和 FAQ 问答机器人。
项目实现以一种平台化思路建议系统,是一个通用的解决方案。开发者只需要按照数据规范即可,不需要修改代码就可以运行系统了
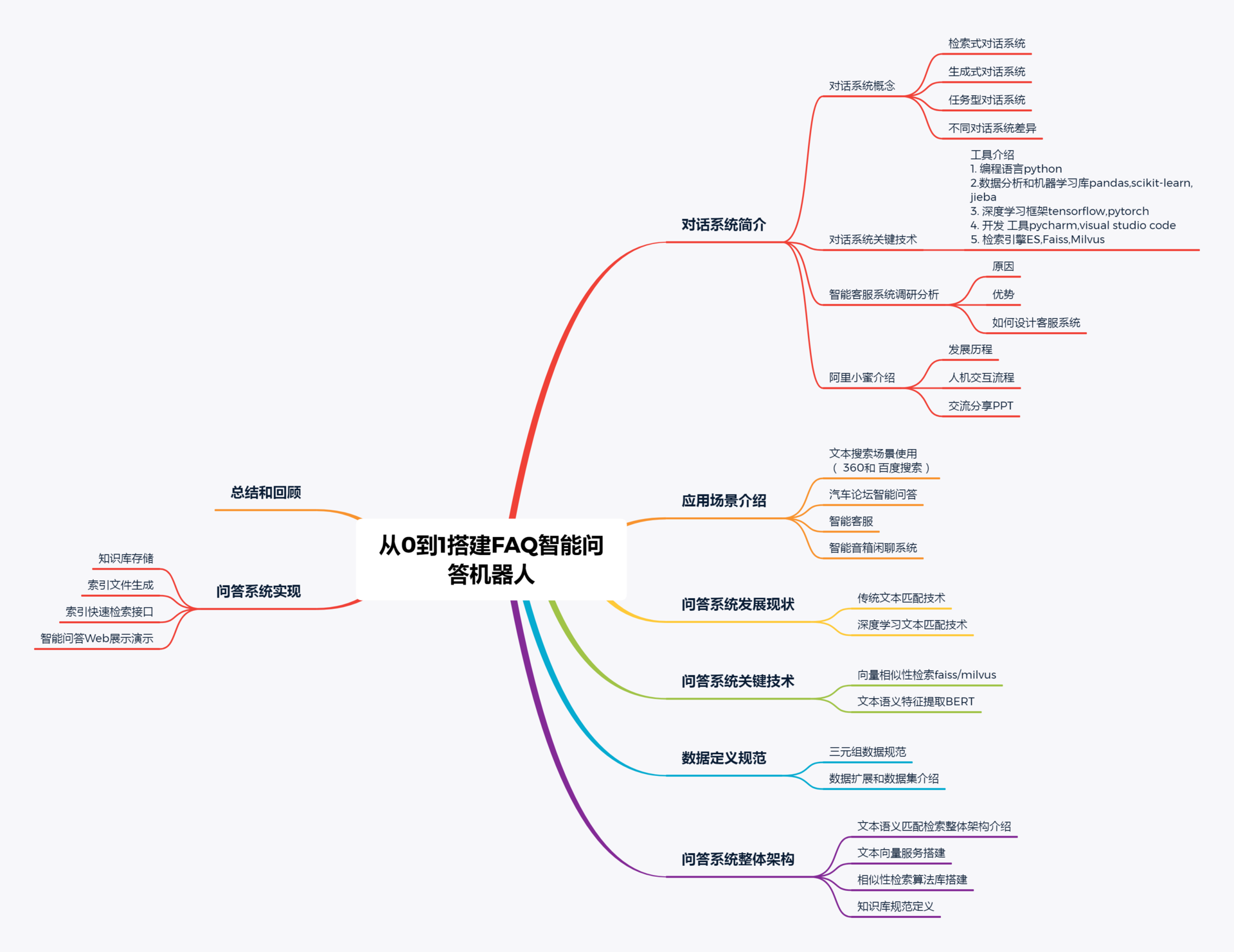
对话系统可以根据人的输入自动选择或者生成出相应的回复,来达到帮助人们在特定领域或者开放域解决一定的问题。(最后,通过医疗数据提供 FAQ 智能问答: aiwen2100)
用户希望得到某个问题的答案,机器人回复来自于特定知识库,以特定的回复回答用户
用户希望完成特定任务,机器人通过语义执行后台已对接能力,帮用户完成指定任务
用户没有明确目的,机器人回复也没有标准答案,以趣味性的回复回答用户

基于检索的模型不会产生新的文字,只能从预先定义的 “回答集” 中挑选出一个较为合适的回答。
检索式对话系统不会产生新的回复,其能够回复类型与内容都由语料库所决定。一旦用户的问话超脱了语料库的范围,那么对话系统将无法准确回答用户。
相对严谨可靠,可控性强,不会回复令人厌恶或违法法规的文本。
一般处理流程:
1. 问答对数据集的清洗
2.Embedding(tfidf,word2ec,doc2vec,elmo,bert…)
3. 模型训练
4. 计算文本相似度
5. 在问答库中选出与输入问题相似度最高的问题
6. 返回相似度最高的问题所对应的答案
基于自然语言理解生成式对话策略:即通过机器学习算法构建深层语义模型,结合句词分析
等统计规律提取特征,让模型从大量的已有对话中学习对话规则,利用训练好的模型预测结果。
评估问题,需要依赖人工评定;生成内容,控制不好会回复令人厌恶或违反法规的文本。
智能对话,回复内容丰富。
任务型对话的最终目标是完成指定任务,比如小度智能音箱,需要在每一轮对话都采取合适的决策,保证自己执行正确的指令(即识别出用户的正确意图)
[外链图片转存失败, 源站可能有防盗链机制, 建议将图片保存下来直接上传 (img-r5W9MrmV-1606198473806)(https://uploader.shimo.im/f/iOwhzmol8N1oJdI5.png!thumbnail)]
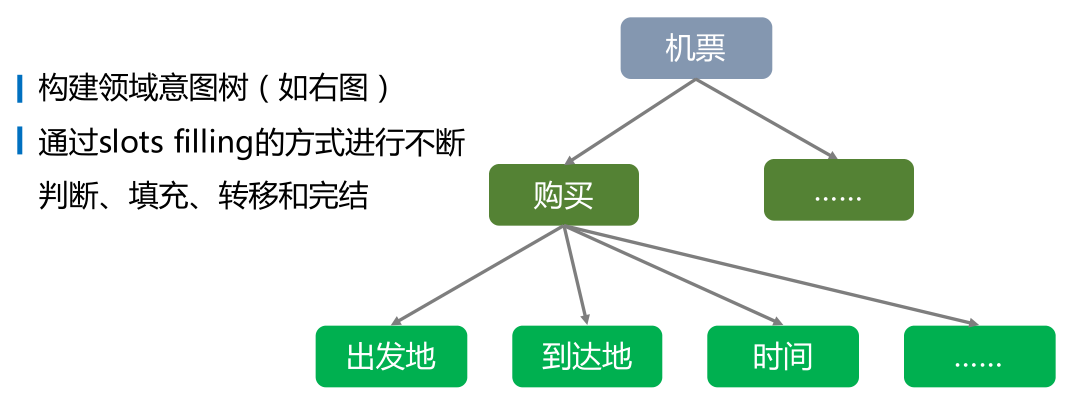
多轮对话是一种在人机对话中初步明确用户意图之后,获取必要信息以最终得到明确用户指令的方式。
这里介绍一种对话管理的一种方式:Frame-Based Dialogue Control,预先指定了一张表格 (Frame),聊天机器人的目标就是把这张表格填满。

通过一个实际场景的案例来解释上述实现具体执行过程:
我:『去北京大兴机场多少钱』
意图:行程花费计算
槽位:【起始地:当前位置;目的地:北京大兴机场;使用货币:???】)
智能客服:『您好,请问是使用人民币吗』
我:『是的』
意图:行程花费计算
槽位:【起始地:当前位置;目的地:萧山机场;使用货币:人民币】)
智能客服:『200 元』
1. 编程语言:python(模型 或者服务) ,C++,Java,go 在线服务
2. 数据处理及机器学习相关库:pandas、scikit-learn、jieba
3. 深度学习框架:tensorflow、pytorch
4. 开发工具:pycharm、visual studio code
5. 其它工具:ElasticSearch 搜索引擎、向量检索引擎 Faiss/Milvus
1、分词算法
2、文本向量化表示
OneHot 、N-Gram 、TFIDF 等词袋模型、Word2Vec、Doc2Vec、Glove
Bert(本案例文本向量化表示选择 bert) 、XLNet 等神经网络模型
3、文本相似度计算(项目中:我们采用余弦相似度,计算得分)
余弦相似度、欧式距离
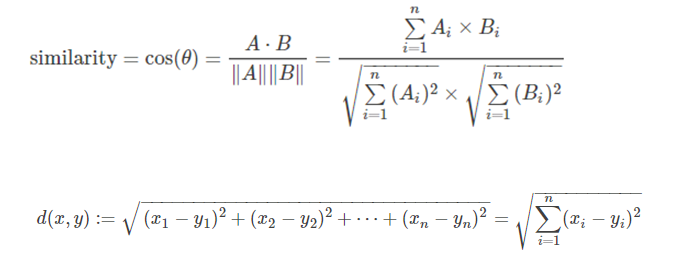
4、检索方法
闲聊系统
1、Seq2Seq 模型
2、Seq2Seq + Attention 模型
3、Transformer
4、Bert 模型
重要,在我们实际工作中,很多场景都会用到
1、意图识别
2、填槽、对话管理
3、多轮对话

分类
NER 识别
多伦对话(模型,规则。。。。)
客服机器人指帮助客服回答问题提高人工客服效率的机器人。客服机器人可以用于回答客户的常规、重复性的问题,但不是替代,而是辅助人工服务,改变客服工作的模式,进一步提高客服工作效率。

纯机器人完全替代客服的并不多,人机结合模式使用广泛。分析一下主要有以下几个原因:
1、机器人响应速度快,且可同时接待多位客户,而且客户不需要等待;
2、机器人替代人工处理咨询中的重复问题,人工客服不易陷入烦躁情绪,客户体验好;
3、遇到复杂问题,人机结合模式可以无缝切换人工来处理,顾客体验不会中断。
1、机器人可以 7 X 24 小时在线服务,解答客户的问题。
2、常问的问题,重复的问题都可以交给机器人来自动回复,省去很多重复的输入及复制粘贴。
3、可以辅助人工客服,在人工服务的时候,推荐回复内容,并学习人工客服的回复内容。
1、时间特性要求。系统极限相应时间到底是多少
2、灵活性。系统的各个模块应该在可控的状态内,每一个模块可插拔,保证线上质量。
3、安全性。内外网隔离,注意网络完全,系统安全,用户安全,数据安全。
4、可扩展性:系统的各个模块支持扩展,支持跨平台,支持多种语言,算法模型可以灵活切换。
5、可靠性:系统和集群稳定运行,主要的集群实现双机热备;实现灾备;当单个节点发生故障可以迅速切换。
6、可用性:系统的各项功能可用,系统上线必须符合一定的正确率
https://blog.csdn.net/qq_40027052/article/details/78672907


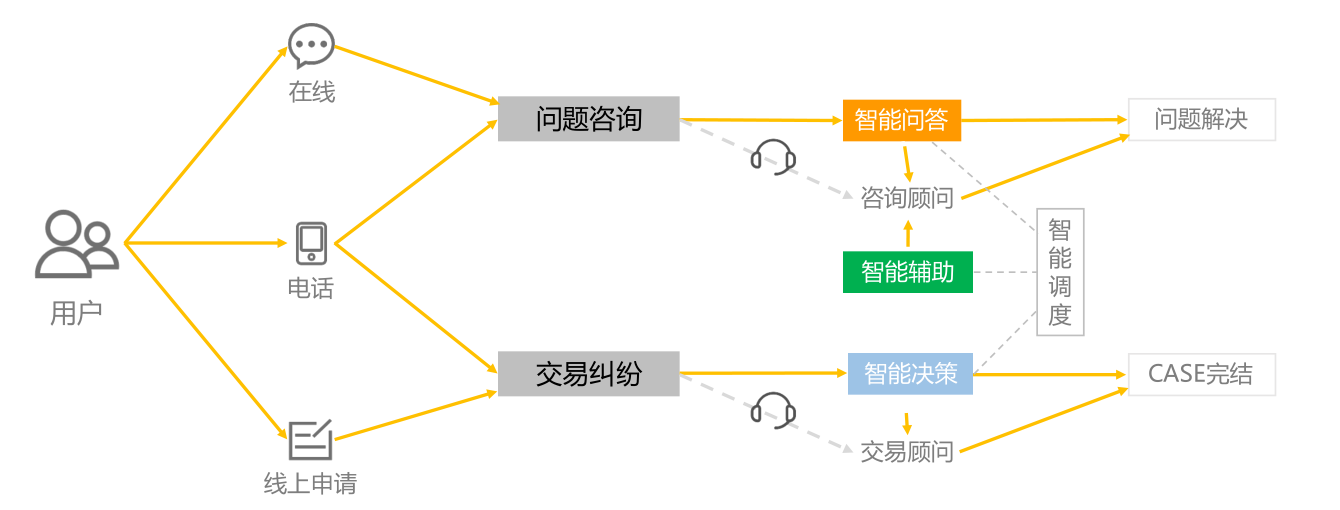
阿里巴巴于 2015 年 7 月推出了阿里小蜜产品,在面世的仅仅几年中,阿里小蜜发展之迅速令人难以想象。阿里小蜜给出了一个典型的智能对话系统的架构。
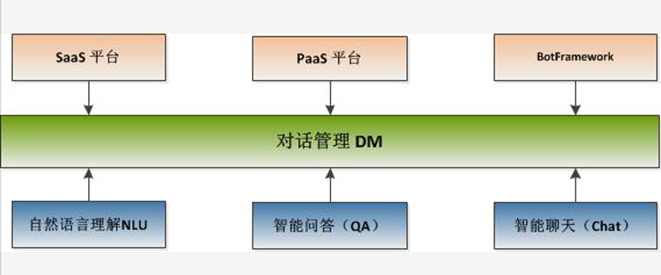
自然语言处理(NLP)是对话系统的核心部分
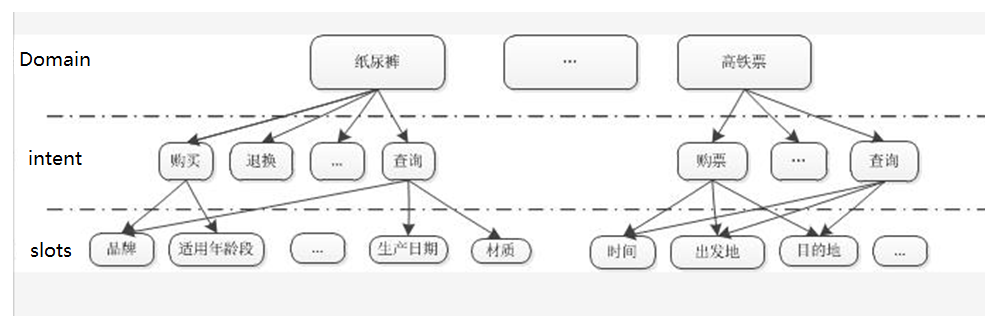
CSDN 问答系统:https://ask.csdn.net/
百度知道:https://zhidao.baidu.com/
360 问答:https://wenda.so.com/search/

汽车之家拥有全球最大的汽车社区论坛。积累了丰富的用户问答数据,能够解决用户在看车、买车、用车等方面遇到的各种问题。针对用户在平台上提出的各种问题,从海量的高质量问答库中匹配语义最相似的问题和答案
文本数据具有表达多样化、用语不规范(如:车型车系用语存在大量缩写、简写、语序颠倒等现象)、歧义性强(如:“北京” 可能指汽车品牌,也可能指城市)等特点,这给传统基于关键词匹配的搜索方法带来了很大挑战。因此,在传统关键词匹配的基础上,进一步引入语义搜索技术,将精华问答库的问题映射为多维向量,进行语义匹配,提升问题匹配准确性。
数据格式: query-answer 对如下
不要骂人 好的,听你的就行了
不要骂人严重的直接禁言 好的,听你的就行了
不要骂人了吧 好的,听你的就行了
不要骂人哦 好的,听你的就行了
不要骂人小心封号啊 好的,听你的就行了
不认识你不记得你 你当我傻逼啊
不认识你昂 你当我傻逼啊
不认识你老哥了 你当我傻逼啊
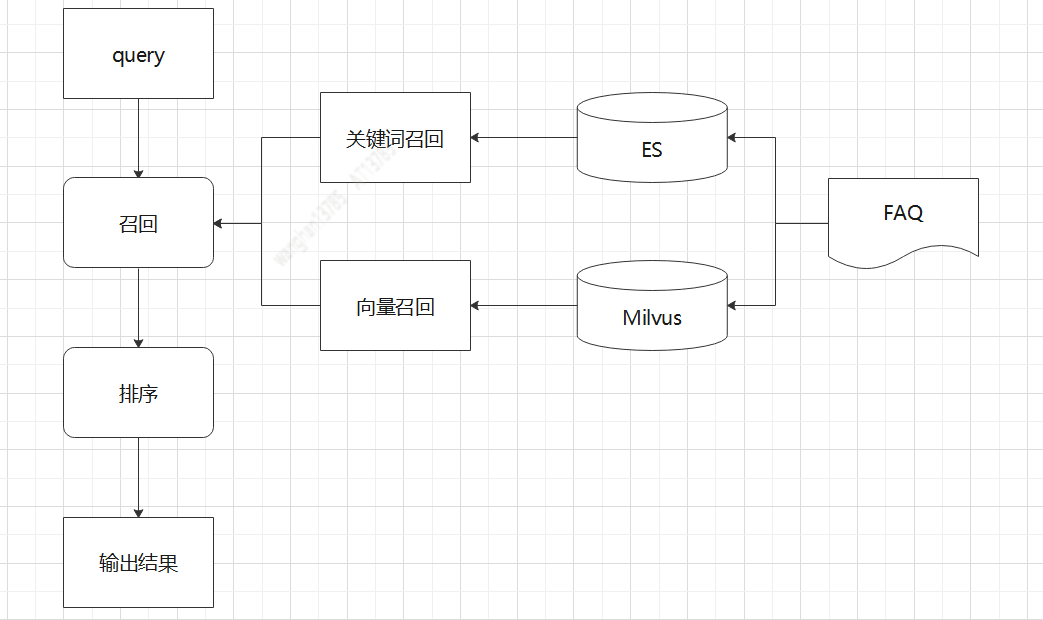
FAQ 检索型问答流程是根据用户的新 Query 去 FAQ 知识库找到最合适的答案并反馈给用户。
检索过程如图所示
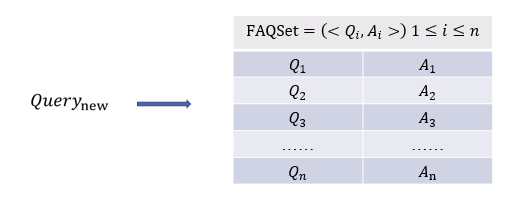
其中,Qi 是知识库里的标准问,Ai 是标准问对应的答案。
具体处理流程为:
针对 FAQ 检索式问答系统,一般处理流程
搭建一个 FAQ 问答系统一般实现方法
(通过关键词匹配获取答案,类似电商、新闻搜索领域关键词召回)
(计算每个单词的 tfidf 数值,分词后换算句子表示。 TF-IDF 方式也在用在关键词提取)
方案可以扩展到的业务需求(本文介绍的是一种文本语义匹配通用解决方案)
(对话系统检索式智能问答系统,答案在知识库中且返回唯一的数据记录)
针对这类问题,重点文本等通过某种方式进行向量化表示(word2vec、doc2vec、elmo、bert 等),然后把这种特征向量进行索引(faiss/Milus) , 最终实现在线服务系统的检索,然后再通过一定的规则进行过滤,获取最终的数据内容。
传统的文本匹配技术有 BoW、VSM、TF-IDF、BM25、Jaccord、SimHash 等算法,主要解决字面相似度问题。
面临的困难:
由 于中文含义的丰富性,通常很难直接根据关键字匹配或者基于机器学习的浅层模型来确定两个句子之间的语义相似度。
深度学习模型文本做语义表示逐渐应用于检索式问答系统。
相比传统的模型优点:
本文采用相似问题匹配来实现一个 FAQ 问答系统。
问题:什么是相似问题匹配?
答案:即对比用户问题与现有 FAQ 知识库中问题的相似度,返回用户问题对应的最准确的答案
深度语义匹配模型可以分为两大类,分别是 representation-based method 和 interaction-based method,这里我们针对 Represention-based Method 这种方法进行探索。
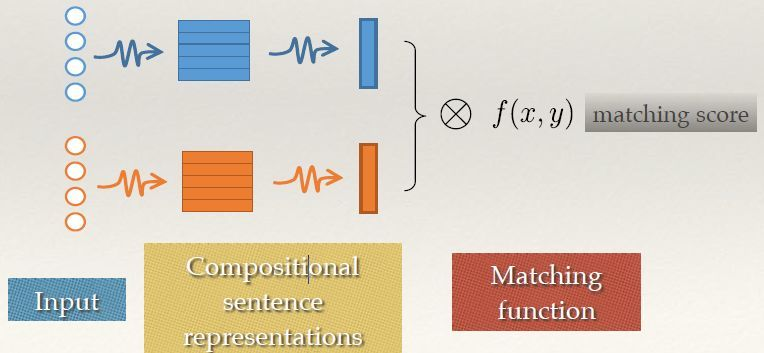
这类算法首先将待匹配的两个对象通过深度学习模型进行表示,之后计算这两个表示之间的相似度便可输出两个对象的匹配度。针对匹配度函数 f(x,y) 的计算通常有两种方法: cosine 函数 和 多层感知器网络(MLP)

对比两种匹配方法的优缺点
* cosine 函数:通过相似度度量函数进行计算,实际使用过程中最常用的就是 cosine 函数,这种方式简单高效,并且得分区间可控意义明确
* 多层感知器网络(MLP):将两个向量再接一个多层感知器网络(MLP),通过数据去训练拟合出一个匹配度得分,更加灵活拟合能力更强,但对训练的要求也更高
Google 的 BERT 模型在 NLP 领域中具有巨大的影响力。它是一个通用的语言表示模型,可以应用于诸多领域。本文的项目是将 Faiss 与 BERT 模型结合搭建文本语义匹配检索系统,使用 BERT 模型将文本数据转成向量,结合 Faiss 特征向量相似度搜索引擎可以快速搜索相似文本,最终获取想要的结果
Faiss 是 Facebook AI 团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前最为成熟的近似近邻搜索库。它包含多种搜索任意大小向量集(备注:向量集大小由 RAM 内存决定)的算法,以及用于算法评估和参数调整的支持代码。Faiss 用 C++ 编写,并提供与 Numpy 完美衔接的 Python 接口。除此以外,对一些核心算法提供了 GPU 实现。相关介绍参考《Faiss:Facebook 开源的相似性搜索类库》
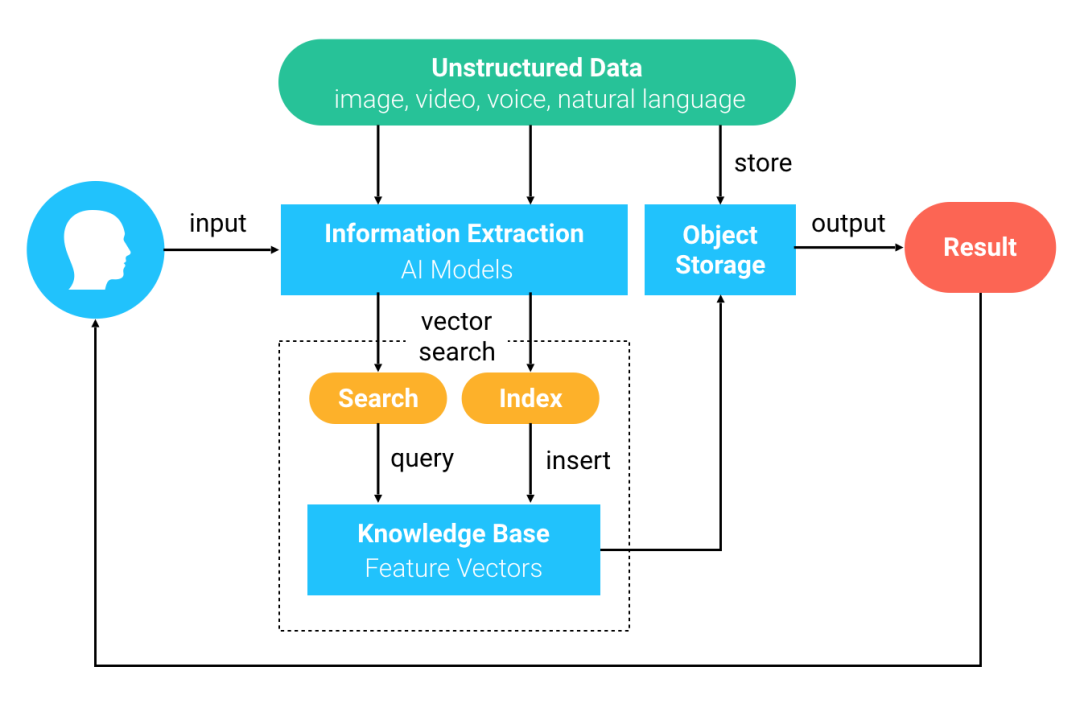
BERT 模型是 Google 发布的一个新的语言表达模型(Language Representation Model),全称是 Bidirectional Encoder Representations from Transformers,即双向编码表征模型。BERT 模型的优势体现在两方面。
Google 提供了一些预先训练的模型,其中最基本的两个模型是 BERT-base 模型和 BERT-large 模型。具体参数如下表所示:
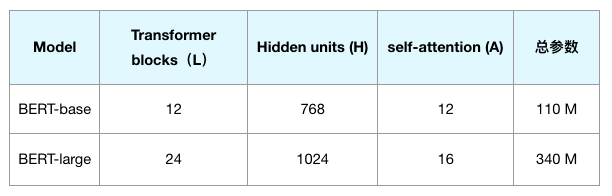
BERT-base 模型和 BERT-large 模型的参数总量大小和网络层数不同,BERT-large 模型所占计算机内存较多,所以本文项目选用 BERT-base 模型对文本数据进行向量转化。(注:其中,层数(即 Transformer 块个数)表示为 L,隐藏尺寸表示为 H ,自注意力头数表示为 A 。)
关于 main.py 主要参数
$ python main.py --help
usage: main.py [-h] --task TASK [–load] [–index] [–n_total N_TOTAL]
[–search] [–sentence SENTENCE] [–topK TOPK]
optional arguments:
-h, --help show this help message and exit
–task TASK project task name
–load load data into db
–index load data text vector into faiss
–n_total N_TOTAL take data n_sample ,generate it into faiss
–search search matched text from faiss
–sentence SENTENCE query text data
–topK TOPK take matched data in topK
第一步:知识库存储 <id,answer>
$ python main.py --taskmedical–load
第二步:索引构建 <id,question>
$ python main.py --taskmedical–index --n_total 120000
第三步:文本语义相似度匹配检索
$ python main.py --taskmedical_120000–search --sentence 得了乙肝怎么治疗
备注:medical_120000 中 task_${索引记录数} 组合
完成上述功能后,我们可以在此基础上,根据业务不同搭建一些相关应用,例如:
第四步:基于文本语义检索服务实现 FAQ 问答
$ python main.py --taskmedical_120000–search --sentence 身上出现 --topK 10
第五步:基于文本语义检索服务 Web 服务
启动服务 python app.py --taskmedical_120000,然后访问地址 http://xx.xx.xx.xx:5000/
我们这里呢,使用上述基础服务完成一个 FAQ 问答机器人
项目数据集包含三个部分:问题数据集 + 答案数据集 + 问题 - 答案唯一标识,数据是一一对应的。

针对不同的业务系统,我们只需要提供这种数据格式,通过本文的模板就可以快速搭建一个 demo 了,祝大家学习愉快。
本文的文本语义匹配搜索项目使用的 Faiss 和 BERT 的整体架构如图所示:
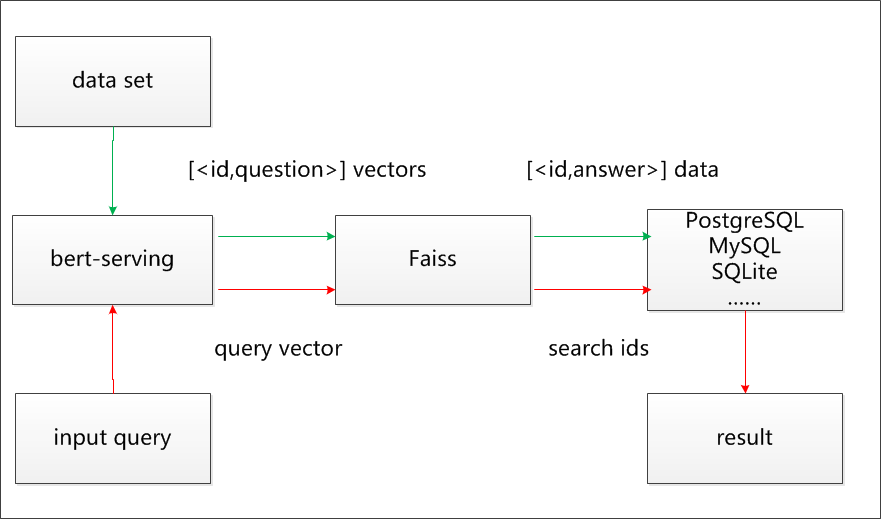
(注:深蓝色线为数据导入过程,橘黄色线为用户查询过程。)
使用 bert as service 服务
第一步:安装 tensorflow
Python >= 3.5
Tensorflow >= 1.10 (one-point-ten)
ubuntu 系统 - gpu 下载离线安装文件并 pip 安装
tensorboard-1.15.0-py3-none-any.whl
tensorflow_estimator-1.15.1-py2.py3-none-any.whl
tensorflow_gpu-1.15.3-cp37-cp37m-manylinux2010_x86_64.whl
也可以通过下面的方式快速下载(这里下载 cpu 版本)
pip install tensorflow==1.15.0 --user -ihttps://pypi.tuna.tsinghua.edu.cn/simple
验证是否安装
import tensorflow as tf
print(tf.version)
第二步:bert-serving 服务搭建
( 我们在 ubuntu 系统搭建完成 bert-serving ,目录:/home/ubuntu/teacher/ )
通过 bert-serving 服务,帮助我们解决:文本 -> 向量的转换
1、参考 github 提供的代码
git clonehttps://github.com/hanxiao/bert-as-service.git
2、安装 server 和 client
pip install bert-serving-server # server
pip install bert-serving-client # client, independent of bert-serving-server
3、下载 pretrained BERT models
Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
解压模型:
chinese_L-12_H-768_A-12
├── bert_config.json
├── bert_model.ckpt.data-00000-of-00001
├── bert_model.ckpt.index
├── bert_model.ckpt.meta
└── vocab.txt
bert_config.json: bert 模型配置参数
vocab.txt: 字典
bert_model: 预训练的模型
4、启动 bert-service
nohup bert-serving-start -model_dir chinese_L-12_H-768_A-12 -num_worker 1 -max_seq_len 64 >start_bert_serving.log 2>&1 &
(CPU 和 GPU 模式都可以)
针对每个字段进行说明
workers = 4 表示同时并发处理请求数
model_dir 预训练的模型
max_seq_len 业务分析句子的长度
关闭服务
bert-serving-terminate -port 5555
5、测试文本 -> 向量表示结果
from bert_serving.client import BertClient
bc = BertClient()
result = bc.encode([‘First do it‘])
print(result)
知识库:可以存储 mongo/PostgreSQL/mysql 根据数据量进行选择
本文给大家分享的内容,数据存储在 mysql 上。
备注:关于 mysql 的具体安装,大家去上网查找一下。(root,12345678)
大家在学习过程中,如果有任何的问题:可以网站留言(或者 weixin: aiwen2100)
create database faiss_qa;
use faiss_qa;
CREATE TABLE answer_info (
id int(11) NOT NULL AUTO_INCREMENT,
answer mediumtext COLLATE utf8mb4_bin,
PRIMARY KEY (id),
KEY answer_info_index_id (id)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
$ python main.py --taskmedical–index --n_total 120000
$ python main.py --task medical --search --sentence 小安信贷
完成上述功能后,我们可以在此基础上,根据业务不同搭建一些相关应用,例如:
对输入数据微小的差别看看有什么不同?

首先,我们启动服务:python app.py
然后,请求 API 服务地址查看检索检索
$ curl -H “Content-Type:application/json” -X POST --data ‘{“query”: “乙肝怎么治疗”}‘http://localhost:5000/api/v1/search| jq
启动服务 python app.py,然后访问地址 http://xx.xx.xx.xx:5000/
用户表达的细微差别,通过文本语义匹配总之能找到最佳的答案,最终反馈给用户。
例如: 两种语言表达看看效果
第一句: 小孩子感冒吃什么
第二句: 小孩子感冒不能吃什么
上述明显表达的是两个含义,而通过文本语义的方式也很好得识别出来了,效果还不错。
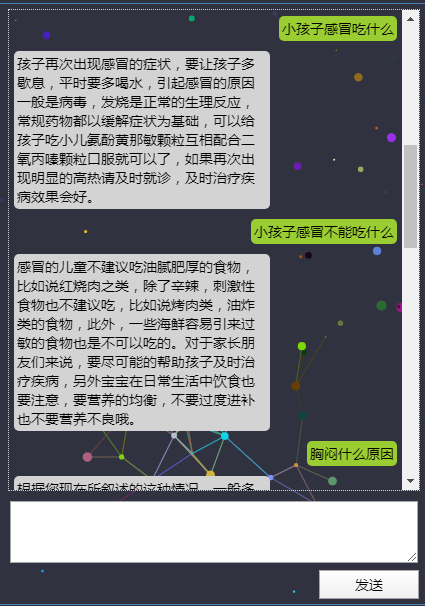
我们看看后端服务地址数据

注意:FAQ 系统依赖 bert-serving 服务,请确认正常工作。
[http://xx.xx.xx.xx:5000/status
正常情况下的返回结果格式如下:
{
“status”:“success”,
“ip”:“127.0.0.1”,
“port”:5555,
“identity”:“cbc94483-1cd6-406d-b170-0cb04e77725bb”
}
在 AI 高速发展的时代,我们可以使用深度学习模型去处理各种类型的非结构化数据,例如图片、文本、视频和语音等。本文项目通过 BERT 模型可以将这些非结构化数据提取为特征向量,然后通过 Faiss 对这些特征向量进行计算,实现对非结构化数据的分析与检索。
本文利用 Faiss 搭建的 FAQ 问答系统也只是其中一个场景,展示了 Faiss 在非结构化数据处理中的应用。欢迎大家导入自己的数据建立自己的 FAQ 问答系统(或者文本搜索、智能客服等新系统)。Faiss 向量相似度检索引擎搜索十亿向量仅需毫秒响应时间。你可以使用 Faiss 探索更多 AI 用法!
最后,大家有任何问题,欢迎留言交流(WX:aiwen2100),大家一起交流经验。
全文完
0-1 学什么0-2 在线系统 DEMO1-1 对话系统概念1-1-1 不同对话任务对比1-1-2 检索式对话系统1-1-3 生成式对话系统1-1-4 任务型对话系统1-2 对话系统关键技术1-2-1 相关工具1-2-2 检索式相关技术介绍1-2-3 生成式相关技术介绍1-2-4 任务型相关技术介绍1-3 智能客服调研分析1-3-1 调研分析1-3-2 智能客服的优势1-3-3 如何设计智能客服系统1-4 阿里小蜜介绍1-4-1 智能客服发展阶段1-4-2 人机交互基本流程2-2 文本搜索场景2-3 论坛相似问答系统2-4 智能对话闲聊系统3-1 智能问答常用解决方案3-2 传统文本匹配方法存在问题3-3 深度学习文本匹配4-1 Faiss4-2 BERT5-1 数据规范5-2 系统整体架构6-3 文本向量服务 bert-serving5-4 向量相似度搜索引擎5-5 知识库存储5-6 索引构建5-7 文本语义相似度匹配搜索5-8 文本语义 FAQ 问答机器人 - API 接口5-9 文本语义 FAQ 问答机器人 - Web 界面
Faiss 和 bert 提供的模型实现了一个中文问答系统。旨在提供一个用 Faiss 结合各种 AI 模型实现语义相似度匹配的解决方案。
原文:https://www.cnblogs.com/cx2016/p/14040857.html