现状问题:业务发展过程中遇到的峰值瓶颈
集群就是使用网络将若干台计算机联通起来,并提供统一的管理方式,使其对外呈现单机的服务效果
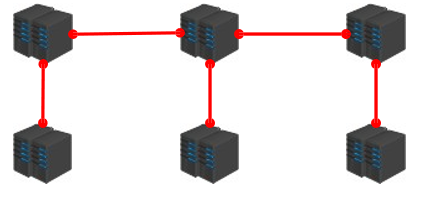
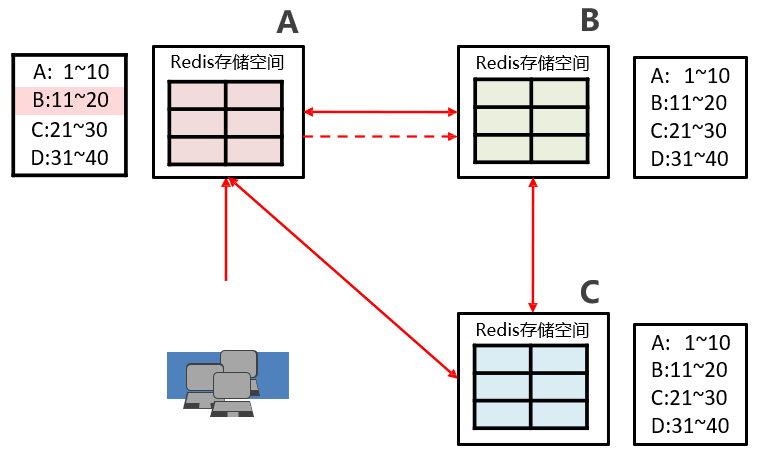
集群作用:
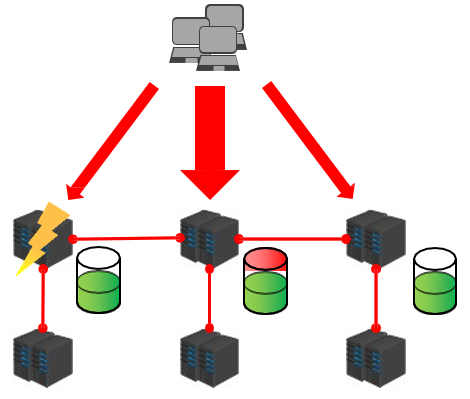
数据存储设计:
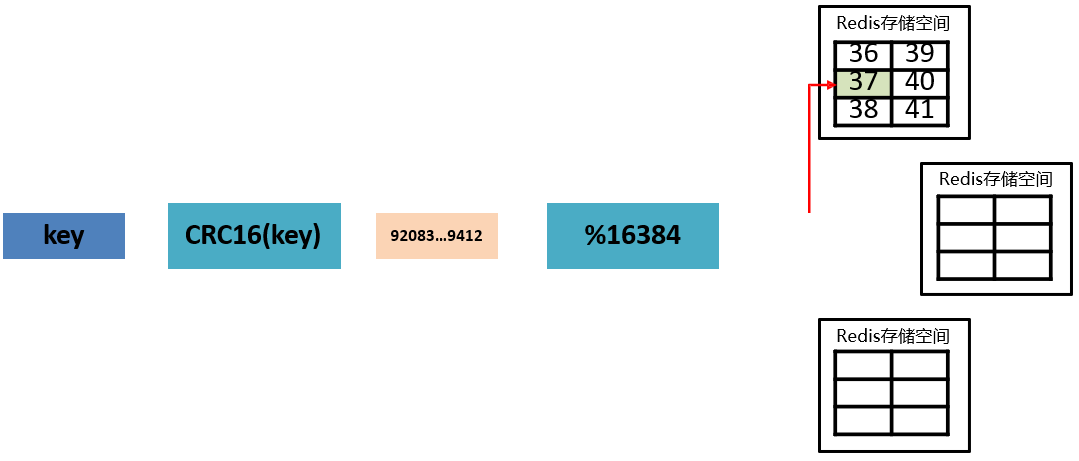
通过算法设计,计算出key应该保存的位置
将所有的存储空间计划切割成16384份,每台主机保存一部分
注意:每份代表的是一个存储空间,不是一个key的保存空间
将key按照计算出的结果放到对应的存储空间
那redis的集群是如何增强可扩展性的呢?譬如我们要增加一个集群节点
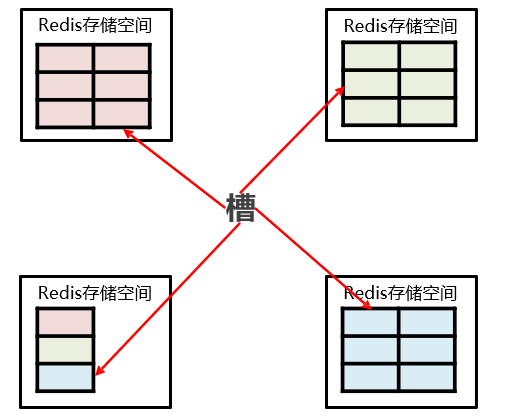
当我们查找数据时,集群是如何操作的呢?
首先要明确的几个要点:
Cluster配置
cluster-enabled yes|no
cluster-config-file filename
cluster-node-timeout milliseconds
cluster-migration-barrier min_slave_number
Cluster节点操作命令
cluster nodes
cluster replicate master-id
cluster meet ip:port
cluster forget server_id
cluster failover
集群操作命令:
redis-cli –-cluster create masterhost1:masterport1 masterhost2:masterport2 masterhost3:masterport3 [masterhostn:masterportn …] slavehost1:slaveport1 slavehost2:slaveport2 slavehost3:slaveport3 -–cluster-replicas n
注意:master与slave的数量要匹配,一个master对应n个slave,由最后的参数n决定
master与slave的匹配顺序为第一个master与前n个slave分为一组,形成主从结构
redis-cli --cluster add-node new-master-host:new-master-port now-host:now-port
redis-cli --cluster add-node new-slave-host:new-slave-port master-host:master-port --cluster-slave --cluster-master-id masterid
redis-cli --cluster del-node del-slave-host:del-slave-port del-slave-id
redis-cli --cluster reshard new-master-host:new-master:port --cluster-from src- master-id1, src-master-id2, src-master-idn --cluster-to target-master-id -- cluster-slots slots
注意:将需要参与分槽的所有masterid不分先后顺序添加到参数中,使用,分隔
指定目标得到的槽的数量,所有的槽将平均从每个来源的master处获取
redis-cli --cluster reshard src-master-host:src-master-port --cluster-from src- master-id --cluster-to target-master-id --cluster-slots slots --cluster-yes
原文:https://www.cnblogs.com/60kmph/p/14047068.html