如何创建流式数据流和流式数据集?先从了解输入源入手。流数据集可以通过SparkSession.readStream()返回的DataStreamReader接口创建。具体定义数据源时,可以指定源数据的格式、模式和选项等详细信息。
以下是几个内置的数据输入源:
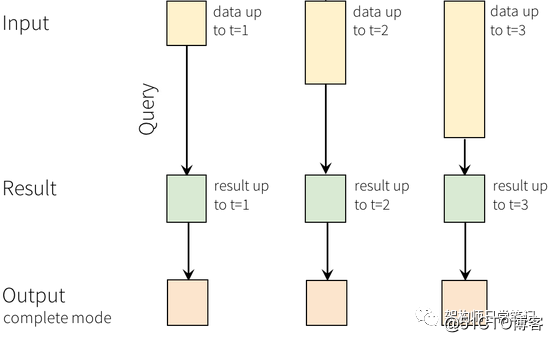
图1:Structured Streaming结构化流编程模型
以下是从不同源读取数据的示例,简单看一下大致能了解其脉络:
例1:从Socket源读取数据
// 构建SparkSession作为操作数据集的入口
SparkSession spark = SparkSession.builder()
.appName("SocketProcessor").getOrCreate();
// 从Socket中读取数据
Dataset<Row> socketDF = spark
.readStream()
.format("socket") //此处定义输入源格式
.option("host", "localhost")
.option("port", 9999)
.load();
// 如有流式输入源则返回True
socketDF.isStreaming();
// 输入当前数据集中的Schema源信息
socketDF.printSchema();// 构建SparkSession作为操作数据集的入口
SparkSession spark =SparkSession.builder()
.appName("KafkaProcessor").getOrCreate();
// 定义StructType用于描述自定义类型
StructType reportMsgSchema = newStructType()
.add("token", "string")
.add("content", "string");
// 定义主机端口与Topic,从Kafka流式读取数据
Dataset<Row> dataset =spark.readStream().format("kafka")
.option("kafka.bootstrap.servers",
"node1:9092,node2:9092,node3:9092")
.option("subscribe", "sysalert").load();
// 对Dataset类型进行转换
// 通过预定义from_json函数与Schema将读取到的字符串转化为JSON
Dataset<Row> untypedDs = dataset
.select(functions.from_json(functions.col("value")
.cast("string"),reportMsgSchema).alias("msg"))
.select("msg.token", "msg.content");spark.read().json("/demo/msg.json").show();一般默认情况下,比如例子2中读取Kafka流数据,需要通过StructType对输入源指定模式(避免Spark自动推断)。只有在某些特殊情况下,才通过设置spark.sql.streaming=true来启用模式推理。
编写作业时,可以在数据流上进行各种操作,比如无类型的SQL操作(select/where/groupBy)、类型化的RDD操作(map/filter/flatMap)。下面例子中介绍了几个使用频率比较高的操作。
// 定义数据模型
public class DeviceData {
private String device;
private String deviceType;
private Double signal;
private java.sql.Date time;
...
// Getter/setter方法
}从输入源中读取数据集(具体代码省略,可参考例2)
Dataset<Row> df = ...;对数据集的类型进行转换,从Row转换为具体自定义类型
Dataset<DeviceData> ds =
df.as(ExpressionEncoder.javaBean(DeviceData.class));Select操作示例:选择signal大于10的数据集(注:针对df和ds结果相同)
df.select("device").where("signal> 10"); // 针对Row类型数据集操作
ds.filter((FilterFunction<DeviceData>)value -> value.getSignal() > 10)
.map((MapFunction<DeviceData, String>) value ->value.getDevice(), Encoders.STRING());针对deviceType字段实现分组计数
df.groupBy("deviceType").count();// 针对Row类型数据集操作根据deviceType字段分组并求signal字段的平均值
ds.groupByKey((MapFunction<DeviceData,String>) value
-> value.getDeviceType(), Encoders.STRING())
.agg(typed.avg((MapFunction<DeviceData, Double>) value
->value.getSignal()));以上是关于StructuredStreaming结构化流中对于如何读取输入源,并对读取的流式数据集进行简单操作的示例。后续文章我们将继续探讨更深入的内容。
参考资料:
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Spark Structured Streaming如何操作数据集?10分钟案例入门
原文:https://blog.51cto.com/15015181/2556378