本文是在康博的博文的基础上再整理的。
基本上都是使用 Open Street Map (OSM) 的路网数据。下载 OSM 数据的方法有很多,这里就不再赘述。
我个人是使用 OpenStreetMap Data Extracts 下载了整个中国的数据,然后用研究区的边界数据进行了裁剪。具体是使用了 ArcGIS 的 (ArcToolbox - Analysis Tools - Extract - Clip) 工具进行的裁剪。
使用 Ian Broad 开发的 Create Points on Polylines with ArcPy 工具箱进行采点。可以去工具箱的链接下载 tbx 文件,然后把文件复制到
C:\Users\Ivy\AppData\Roaming\ESRI\Desktop10.5\ArcToolbox\My Toolboxes
文件夹即可,在 Catalog 看到新下载的工具箱(上面的路径需要自己改一下,特别是用户名!)。
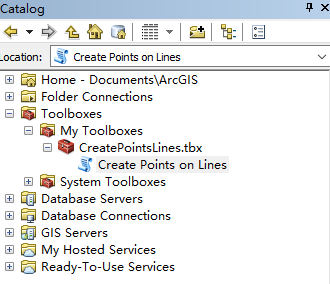
运行 CreatePointsLines 工具,设置参数,类型可以选“INTERVAL BY DISTANCE",然后 Distance 字段填 0.00001。这样大概就是每条路间隔 1 米取一个点。
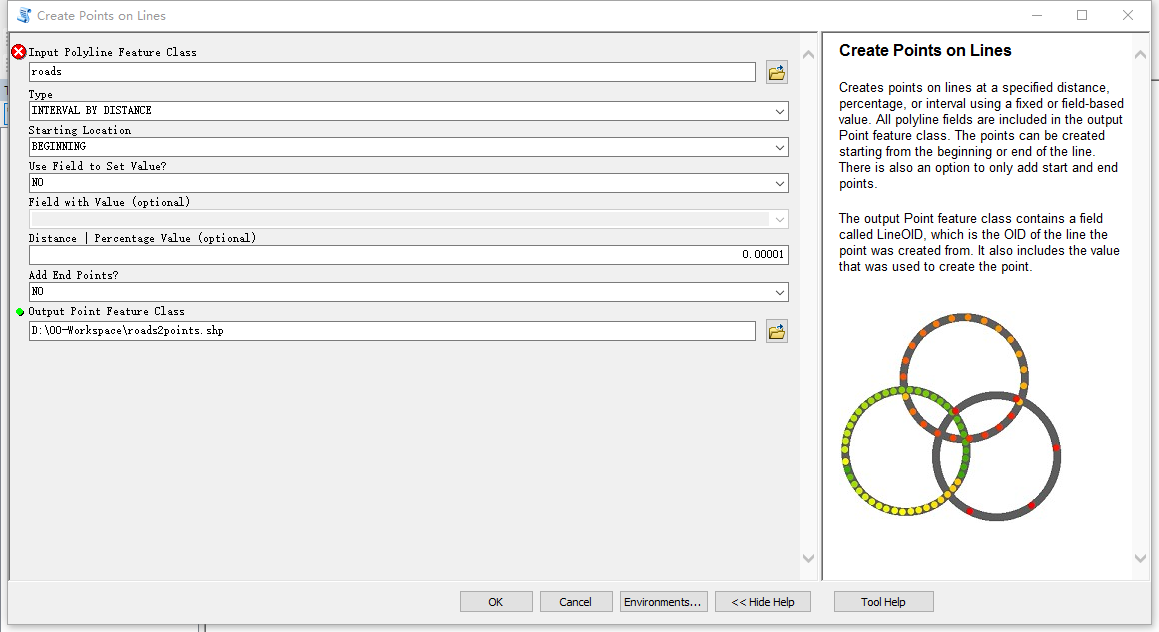
然后在属性表里新建经纬度的字段
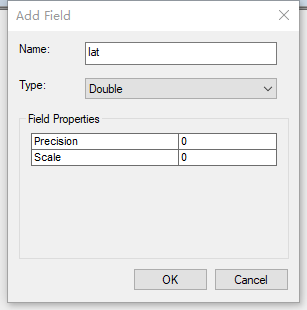
然后对字段进行【计算几何】的操作,把经纬度给算出来。
(康博的博文是把坐标系转换为了 wgs84 的 web 墨卡托坐标,但是我验证了一下,这个墨卡托坐标和百度使用的平面墨卡托坐标不是一致的,所以这里还是先输出 wgs84 的坐标,后面使用百度的 api 转换为 bd09mc。)
然后把属性表导出为 txt 文件。(不要导出为 dbf 文件,转换还挺麻烦的,用 python 的话需要额外的库,用 excel 的话数据量太大会打不开(excel 有行数限制))
接着把导出的点使用下面的代码存入数据库,我使用的是 mongodb。
import pandas as pd
import pymongo
df = pd.read_csv("../maps/points.txt")
new_df = df[["lon", "lat"]] # 只要坐标列
new_df = new_df[(new_df["lon"] != 0) & (new_df["lat"] != 0)] # 删除计算错误的点
new_df["wgs84"] = new_df["lon"].map(str)+","+new_df["lat"].map(str)
new_df["ok"] = 0
del new_df["lon"], new_df["lat"]
print(new_df.shape)
# 把读出来的 dataframe 转化为 dict,形式为[{"wgs84": "x,y", "ok": 0}, ...]
data = new_df.to_dict(orient = ‘records‘)
# 存入数据库
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["rpoints_wgs84"]
col.insert_many(data)
数据库内的形式大概是如下所示。ok 字段是记录状态的。因为当点很多的时候,可能由于意外导致程序崩溃或者打断,而不知道程序的进度来重新启动。
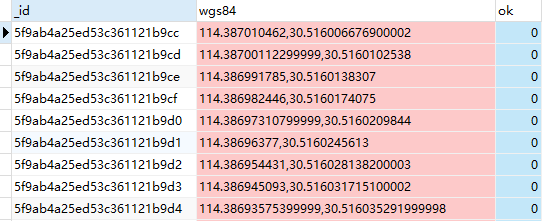
使用百度官方的 api 把 wgs84 坐标系转换为百度墨卡托坐标。
需要使用百度的开发者 ak,我是创建了一个形如下面这样的 json 文件来存储可用的 ak,方便程序调用。
{
"ak": [
"ak1",
"ak2"
]
}
转换坐标的代码如下。因为 api 一次可以接收 100 个点,所以用到了均分列表的函数。
import requests, json
import pymongo
import sys, traceback
import random, time
from tqdm import tqdm
def convert_points(point):
# 每次 100 个点
coords = ";".join(point)
url = "http://api.map.baidu.com/geoconv/v1/?coords={}&from=1&to=6&ak={}".format(coords, random.choice(aks))
while True:
try:
res = requests.get(url)
data = res.json()
if data["status"] == 0:
return data["result"]
else:
print(data)
except (requests.exceptions.ConnectionError, json.decoder.JSONDecodeError) as e:
print("\n Error: ", repr(e))
except:
print("\n ************************ Alert!! ********************************")
traceback.print_exc()
return False
def write_data(mc_point):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["rpoints_mc"]
data = []
for point in mc_point:
data.append({"bd09mc": "{},{}".format(point["x"], point["y"]), "ok": 0})
now = time.time()
print("Ready to insert data")
while True:
try:
if len(data) <= 1000:
col.insert_many(data)
else:
groups = split_list(data, n=1000)
for group in groups:
col.insert_many(group)
print("Inserting data used", time.time()-now,"s")
break
except:
traceback.print_exc()
sys.exit(1)
def split_list(l, n=100):
# 均分列表
new_l = []
for i in range(0,len(l),n):
new_l.append(l[i:i+n])
return new_l
def get_points():
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["rpoints_wgs84"]
docs = col.find({"ok": 0})
points = [doc["wgs84"] for doc in docs]
return points
if __name__=="__main__":
## 读取出点坐标
wgs_points = get_points()
points_groups = split_list(wgs_points)
print("There‘re", len(points_groups), "groups")
## 读取出备用的 ak
with open("ak.json", ‘r‘, encoding=‘utf8‘) as f:
j = json.load(f)
aks = j["ak"]
valid_points = []
for wgs_point in tqdm(points_groups, ncols=80):
while True:
mc_point = convert_points(wgs_point)
if mc_point:
valid_points += mc_point
break
write_data(valid_points)
这时,使用的是一个非官方的链接来访问这个坐标点是否存在全景图(不同坐标点可能存在同一全景图)。
https://mapsv0.bdimg.com/?qt=qsdata&x={}&y={}
返回的是 json 数据,含有全景图的 id。
使用下面的代码多线程爬取全景图 id,并存入数据库,这里仍然使用的是 mongdb。
import pymongo
import threading
from queue import Queue
from threading import Thread
import requests, urllib3
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
import sys, traceback
from fake_useragent import UserAgent # 构造假的 Headers
from ippool.ippool_fast import * # 自己写的代理池的包
import time
import random
class Spider():
def __init__(self):
self.thread_num = 10
self.start = time.time()
self.all_panoids = self.get_panoids()
# 各种队列
self.point_q = self.get_points() # 待确认的点的队列
self.all_lenth = self.point_q.qsize() # 队列总长度
self.finish_q = Queue(100000) # 已经确认的点的队列
self.panoid_q = Queue() # 全景图id队列
self.ippool_q = Queue() # 代理池队列
def get_points(self):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["rpoints_mc"]
docs = col.find({"ok": 0})
point_q = Queue()
for doc in docs:
point_q.put(doc["bd09mc"])
return point_q
def get_panoids(self):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
docs = col.find()
if docs:
print(len(list(docs)))
panoids = [doc["panoid"] for doc in docs]
return panoids
return []
def writeData(self, panoids):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
docs = []
for panoid in panoids:
docs.append({"panoid": panoid,
"bd09mc": "",
"bd09ll": "",
"wgs84": "",
"date": "",
"ok": 0,
"info": {}})
col.insert_many(docs)
def req(self, url):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"DNT": "1",
"Host": "mapsv0.bdimg.com",
"Connection": "close"
}
# 访问 url 直到得到正确的访问结果
while True:
time.sleep(random.random()*2)
try:
# 获取 fake_UA
headers["User-Agent"] = UserAgent(path="fake_useragent.json").random
# 获取代理
while True:
if self.ippool_q.empty() is False:
proxy_ip = self.ippool_q.get()
break
else:
time.sleep(5)
with requests.Session() as s:
retry = Retry(connect=3, backoff_factor=0.5)
adapter = HTTPAdapter(max_retries=retry)
s.mount("https://", adapter)
s.keep_alive = False
res = s.get(url, headers=headers, proxies=proxy_ip, timeout=10)
data = res.json()
# 把可用的代理再放回代理池
self.ippool_q.put(proxy_ip)
if data["result"]["error"] == 0:
return data["content"]["id"]
elif data["result"] == {"action":0, "error": 404}:
return False
else:
print(data)
print(url)
sys.exit(1)
except (requests.exceptions.ConnectTimeout, urllib3.exceptions.ReadTimeoutError, requests.exceptions.ProxyError, urllib3.exceptions.MaxRetryError, requests.exceptions.ReadTimeout) as e:
# print("************************ Alert!! ********************************")
# print("Error:", repr(e))
pass
except:
print("************************ Alert!! ********************************")
traceback.print_exc()
print("url: ", url)
# 线程1: 访问 url 获取结果
def producer(self):
print("producer thread started.")
while self.point_q.empty() is False:
point = self.point_q.get()
point_ls = point.split(",")
url = "https://mapsv0.bdimg.com/?qt=qsdata&x={}&y={}".format(point_ls[0], point_ls[1])
panoid = self.req(url)
if (panoid) and (panoid not in self.all_panoids):
self.panoid_q.put(panoid)
while True:
if self.finish_q.full():
print("finish_q is full")
time.sleep(10)
else:
self.finish_q.put(point)
break
print("Processing: {}/{}, panoid got: {}, time elapse: {:.0f}s, points waiting for update: {}".format(self.all_lenth-self.point_q.qsize(), self.all_lenth, len(self.all_panoids), time.time()-self.start, self.finish_q.qsize()))
# 线程2: 线程1返回的结果存入数据库
def consumer(self):
print("consumer thread started.")
while (self.point_q.empty() is False) or (self.panoid_q.empty() is False):
if (self.point_q.empty() is True):
lenth = self.panoid_q.qsize()
tmp_panoids = []
for _ in range(lenth):
tmp_panoids.append(self.panoid_q.get())
valid_panoids = list(set(tmp_panoids) - set(self.all_panoids))
if len(valid_panoids) > 0:
self.all_panoids += valid_panoids
self.writeData(valid_panoids)
else:
pass
# 线程3: 更新爬过的点的数据库
def update(self):
print("update thread started.")
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["rpoints_mc"]
while (self.point_q.empty() is False) or (self.finish_q.empty() is False):
if self.finish_q.qsize() >= 100:
tmp_points = []
for _ in range(100):
tmp_points.append(self.finish_q.get())
result = col.update_many(
{"bd09mc": {"$in": tmp_points}},
{"$set": {"ok": 1}}
)
print("update result: ", result.matched_count, result.modified_count, result.raw_result)
elif self.point_q.empty() is True:
lenth = self.finish_q.qsize()
tmp_points = []
for _ in range(lenth):
tmp_points.append(self.finish_q.get())
result = col.update_many(
{"bd09mc": {"$in": tmp_points}},
{"$set": {"ok": 1}}
)
print("update result: ", result.matched_count, result.modified_count, result.raw_result)
else:
pass
print("All data updated")
# 线程4: 爬取代理
def get_ips(self):
self.ippool_q.put({"https": ""})
print("ippool thread started. There‘re {} proxies.".format(self.ippool_q.qsize()))
while (self.point_q.empty() is False) or (self.finish_q.empty() is False):
if self.ippool_q.empty() is True:
while True:
tmp_ippool = buildippool()
if len(tmp_ippool) > 5:
for ip in tmp_ippool:
self.ippool_q.put(ip)
break
def run(self):
ths =[]
ippool_thread = Thread(target=self.get_ips)
ippool_thread.start()
ths.append(ippool_thread)
for _ in range(self.thread_num):
producer_thread = Thread(target=self.producer)
producer_thread.start()
ths.append(producer_thread)
consumer_thread = Thread(target=self.consumer)
consumer_thread.start()
ths.append(consumer_thread)
update_thread = Thread(target=self.update)
update_thread.start()
ths.append(update_thread)
# 阻塞主线程
for th in ths:
th.join()
print("Time consume:", time.time()-self.start)
if __name__ == ‘__main__‘:
Spider().run()
得到的数据大概是这样的
如果只需要下载所有的图片,可以跳过这一步。
访问的仍然是一个非官方 api 的链接。一次可以获取 50 个点的数据,但是有时候可能会因为太多了而崩溃返回 404,所以代码里设置了如果出错就拆分为 25 个点一组的机制。
import pymongo
from queue import Queue
from threading import Thread
import requests, urllib3
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
import sys, traceback
from fake_useragent import UserAgent # 构造假的 Headers
from ippool.ippool_fast import *
import time
import random
class Spider():
def __init__(self):
self.thread_num = 5
self.start = time.time()
# 各种队列
self.panoid_q = self.get_panoid_groups()# 待确认的全景图id队列
self.all_lenth = self.panoid_q.qsize() # 队列总长度
self.process_q = Queue()
self.finish_q = Queue() # 已经确认的队列
self.ippool_q = Queue() # 代理池队列
# 设置一个 flag 控制线程结束
# flag=0,所有线程运行;flag=1,线程1结束,爬完了所有的点,此时线程5也可以结束;
# flag=2,线程2结束,处理完了所有的点;
self.flag = 0
def split_list(self, l, n=100):
# 均分列表
new_l = []
for i in range(0,len(l),n):
new_l.append(l[i:i+n])
return new_l
def get_panoid_groups(self):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
docs = col.find({"ok": 0})
if docs:
panoids = [doc["panoid"] for doc in docs]
groups = self.split_list(panoids, 50)
panoid_q = Queue()
for group in groups:
panoid_q.put(group)
return panoid_q
return []
def req(self, url):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"DNT": "1",
"Host": "mapsv0.bdimg.com",
"Connection": "close"
}
# 访问 url 直到得到正确的访问结果
while True:
time.sleep(random.random()*2)
try:
# 获取 fake_UA
headers["User-Agent"] = UserAgent(path="fake_useragent.json").random
# 获取代理
while True:
if self.ippool_q.empty() is False:
proxy_ip = self.ippool_q.get()
break
else:
time.sleep(5)
# with requests.Session() as s:
# retry = Retry(connect=3, backoff_factor=0.5)
# adapter = HTTPAdapter(max_retries=retry)
# s.mount("https://", adapter)
# s.keep_alive = False
res = requests.get(url, headers=headers, proxies=proxy_ip, timeout=10)
data = res.json()
# 把可用的代理再放回代理池
self.ippool_q.put(proxy_ip)
if data["result"]["error"] == 0:
return data["content"]
elif data["result"]["error"] == 400:
return False
else:
print(data)
print(url)
sys.exit(1)
except (requests.exceptions.ConnectTimeout, urllib3.exceptions.ReadTimeoutError, requests.exceptions.ProxyError, urllib3.exceptions.MaxRetryError, requests.exceptions.ReadTimeout) as e:
print("************************ Alert!! ********************************")
print("Error: TimeoutError or proxyError")
except:
print("************************ Alert!! ********************************")
traceback.print_exc()
print("url: ", url)
# 线程1: 访问 url 获取结果
def producer(self):
print("producer thread started.")
while self.panoid_q.empty() is False:
group = self.panoid_q.get()
part = 1 # 因为有时传入太多panoid会导致返回400的错误,所以可能需要分两组
while True:
if part == 1:
url = "https://mapsv0.bdimg.com/?qt=sdata&sid={}".format(";".join(group))
data = self.req(url)
if data:
self.process_q.put(data)
break
else:
print("split to part 2")
part = 2
continue
else:
url = "https://mapsv0.bdimg.com/?qt=sdata&sid={}".format(";".join(group[:25]))
data1 = self.req(url)
url = "https://mapsv0.bdimg.com/?qt=sdata&sid={}".format(";".join(group[25:]))
data2 = self.req(url)
data = data1 + data2
self.process_q.put(data)
self.flag = 1
print("producer thread done")
# 线程2: 线程1返回的结果进行处理
def processor(self):
print("processor thread stared")
while self.flag < 2:
if self.process_q.empty() is False:
data = self.process_q.get()
for row in data:
self.finish_q.put({
"id": row["ID"],
"info": {
"date": row["Date"],
"bd09mc": "{},{}".format(row["X"],row["Y"]),
"info": row
}
})
elif self.flag == 1:
# 此时线程1爬取完毕,线程2也处理完毕了
time.sleep(5) # 休息 5s 等待是否还有数据
if self.process_q.empty() is True:
self.flag = 2
else:
pass
print("processor thread done")
# 线程3: 线程2解析的结果存入数据库
def consumer(self):
print("consumer thread started.")
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
while self.flag < 4:
if self.finish_q.empty() is False:
data = self.finish_q.get()
while True:
result = col.update_one({
"panoid": data["id"]
},
{
"$set": {
"bd09mc": data["info"]["bd09mc"],
"date": data["info"]["date"],
"ok": 1,
"info": data["info"]["info"]
}
})
# print("update result: ", result.matched_count, result.modified_count, result.raw_result)
if result.modified_count == 1:
# print("update success.")
break
else:
print(result.raw_result)
elif self.flag == 3:
self.flag += 1
else:
pass
print("consumer thread done")
# 线程4: 爬取代理
def get_ips(self):
print("ippool thread start")
self.ippool_q.put({"https": ""})
while self.flag < 1:
if self.ippool_q.empty() is True:
while True:
tmp_ippool = buildippool()
if len(tmp_ippool) > 5:
for ip in tmp_ippool:
self.ippool_q.put(ip)
break
print("ippool thread done")
# 线程5: 进度条显示
def pbar(self):
state = [0, 0, 0, 0]
while self.flag < 4:
if [self.panoid_q.qsize(), self.process_q.qsize(), self.finish_q.qsize()] != state:
state = [self.panoid_q.qsize(), self.process_q.qsize(), self.finish_q.qsize()]
print("Processing: {}/{}, time elapse: {:.0f}s, waiting for process: {}, waiting for update: {}".format(self.all_lenth-self.panoid_q.qsize(), self.all_lenth, time.time()-self.start, self.process_q.qsize(), self.finish_q.qsize()))
time.sleep(1)
def run(self):
print("There‘re {} groups.".format(self.all_lenth))
ths =[]
pbar_thread = Thread(target=self.pbar)
pbar_thread.start()
ths.append(pbar_thread)
ippool_thread = Thread(target=self.get_ips)
ippool_thread.start()
ths.append(ippool_thread)
for _ in range(self.thread_num):
producer_thread = Thread(target=self.producer)
producer_thread.start()
ths.append(producer_thread)
processor_thread = Thread(target=self.processor)
processor_thread.start()
ths.append(processor_thread)
consumer_thread = Thread(target=self.consumer)
consumer_thread.start()
ths.append(consumer_thread)
# 阻塞主线程
for th in ths:
th.join()
print("Time consume:", time.time()-self.start, "s")
if __name__ == ‘__main__‘:
Spider().run()
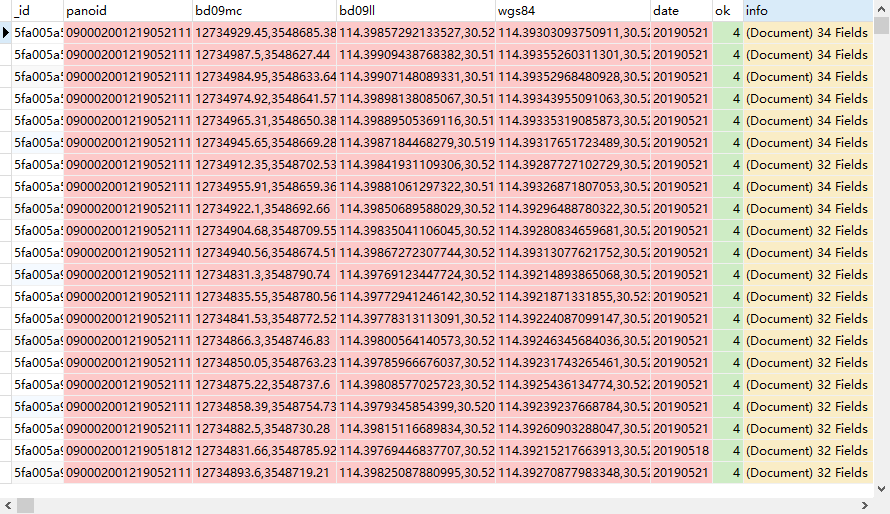
这样就得到了全景图的一些诸如具体坐标点,采集时间等详细元数据。
访问的仍然是一个非官方 api 的链接。(官方 api 一天免费下载的次数太少了!
https://mapsv0.bdimg.com/?qt=pr3d&fovy={}&quality={}&panoid={}&heading={}&pitch={}&width={}&height={}
其中一些参数的含义如下:
import pymongo
import threading
from queue import Queue
from threading import Thread
import requests, urllib3
import sys, traceback
from fake_useragent import UserAgent # 构造假的 Headers
from ippool.ippool_fast import *
import time, os
import random
class Spider():
def __init__(self):
self.thread_num = 1
self.start = time.time()
# 各种队列
self.panoid_q = self.get_panoids()# 待下载的全景图id队列
self.all_lenth = self.panoid_q.qsize() # 队列总长度
self.finish_q = Queue() # 已经确认的队列
self.ippool_q = Queue() # 代理池队列
def get_panoids(self):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
docs = col.find({"ok": 1})
if docs:
panoid_q = Queue()
for doc in docs:
panoid_q.put(doc["panoid"] )
return panoid_q
return []
def req(self, panoid, heading):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "en-US,en;q=0.9",
"DNT": "1",
"Host": "mapsv0.bdimg.com"
# "Connection": "close"
}
url = "https://mapsv0.bdimg.com/?qt=pr3d&fovy=75&quality=100&panoid={}&heading={}&pitch=0&width=1024&height=512".format(panoid, heading)
# 访问 url 直到得到正确的访问结果
while True:
time.sleep(random.random()*2)
try:
# 获取 fake_UA
headers["User-Agent"] = UserAgent(path="fake_useragent.json").random
# 获取代理
while True:
if self.ippool_q.empty() is False:
proxy_ip = self.ippool_q.get()
break
else:
time.sleep(5)
img_path = "../imgs/{}-{}.jpg".format(panoid,heading)
res = requests.get(url, stream=True, timeout=20)
if res.status_code == 200:
with open(img_path, "wb") as f:
f.write(res.content)
# print(img_path, "saved")
# 检查文件是否完整
file_size = int(res.headers["content-length"])
if os.path.getsize(img_path) != file_size:
os.remove(img_path)
continue
# 把可用的代理再放回代理池
self.ippool_q.put(proxy_ip)
return
else:
print(res.status_code)
print(url)
except (requests.exceptions.ConnectTimeout, urllib3.exceptions.ReadTimeoutError, requests.exceptions.ProxyError, urllib3.exceptions.MaxRetryError, requests.exceptions.ReadTimeout, requests.exceptions.ConnectionError) as e:
print("************************ Alert!! ********************************")
print("Error:", repr(e))
except:
print("************************ Alert!! ********************************")
traceback.print_exc()
print("url: ", url)
# 线程1: 访问 url 下载图片
def producer(self):
print("producer thread started.")
while self.panoid_q.empty() is False:
panoid = self.panoid_q.get()
headings = [0, 90, 180, 270]
for heading in headings:
self.req(panoid, heading)
self.finish_q.put(panoid)
print("producer thread done")
# 线程2: 更新数据库
def consumer(self):
print("processor thread stared")
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
while (self.panoid_q.empty() is False) or (self.finish_q.empty() is False):
if self.finish_q.empty() is False:
panoid = self.finish_q.get()
col.update_one({
"panoid": panoid
},
{
"$set":{
"ok": 2
}
})
print("processor thread done")
# 线程3: 爬取代理
def get_ips(self):
print("ippool thread start")
self.ippool_q.put({"https": ""})
while self.panoid_q.empty() is False:
if self.ippool_q.empty() is True:
while True:
tmp_ippool = buildippool()
if len(tmp_ippool) > 5:
for ip in tmp_ippool:
self.ippool_q.put(ip)
break
print("ippool thread done")
# 线程4: 进度条显示
def pbar(self):
while (self.panoid_q.empty() is False) or (self.finish_q.empty() is False):
print("Processing: {}/{}, time elapse: {:.0f}s, waiting for update: {}".format(self.all_lenth-self.panoid_q.qsize(), self.all_lenth, time.time()-self.start, self.finish_q.qsize()))
time.sleep(1)
def run(self):
ths =[]
pbar_thread = Thread(target=self.pbar)
pbar_thread.start()
ths.append(pbar_thread)
ippool_thread = Thread(target=self.get_ips)
ippool_thread.start()
ths.append(ippool_thread)
for _ in range(self.thread_num):
producer_thread = Thread(target=self.producer)
producer_thread.start()
ths.append(producer_thread)
consumer_thread = Thread(target=self.consumer)
consumer_thread.start()
ths.append(consumer_thread)
# 阻塞主线程
for th in ths:
th.join()
print("Time consume:", time.time()-self.start, "s")
if __name__ == ‘__main__‘:
Spider().run()
后面这些步骤都是丰富元数据的,如不需要元数据可跳过。
这里使用的是官方 api
import requests, json
import pymongo
from queue import Queue
from threading import Thread
import numpy as np
import time, random
import traceback
class Spider():
def __init__(self):
self.thread_num = 1
self.start = time.time()
self.groups_q = self.get_points()
self.lenth = self.groups_q.qsize()
self.aks_q = self.get_aks()
self.valid_q = Queue()
def get_aks(self):
with open("ak.json", ‘r‘, encoding=‘utf8‘) as f:
j = json.load(f)
aks = j["ak"]
aks_q = Queue()
for ak in aks:
aks_q.put(ak)
return aks_q
def split_list(self, l, n=100):
# 均分列表
new_l = []
for i in range(0,len(l),n):
new_l.append(l[i:i+n])
return new_l
def get_points(self):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
docs = col.find({"ok": 2})
groups_q = Queue()
if docs:
points = [[doc["panoid"], doc["bd09mc"]] for doc in docs]
point_groups = self.split_list(points)
for group in point_groups:
groups_q.put(group)
return groups_q
return groups_q
def req(self, group):
base = "http://api.map.baidu.com/geoconv/v1/?coords={}&from=6&to=5&ak={}"
panoids = []
bd09mc = []
for point in group:
panoids.append(point[0])
lon, lat = point[1].split(",")
# 之前返回的结果里的 XY 坐标是*100的,所以这里要缩放一下
bd09mc.append("{},{}".format(int(lon)/100, int(lat)/100))
# 访问 url 直到得到正确的访问结果
while True:
time.sleep(random.random()*2)
try:
ak = self.aks_q.get()
url = base.format(";".join(bd09mc), ak)
res = requests.get(url)
data = res.json()
if data["status"] == 0:
# 把有用的 ak 放回队列
self.aks_q.put(ak)
for i in range(len(data["result"])):
self.valid_q.put({
"panoid": panoids[i],
"bd09mc": bd09mc[i],
"bd09ll": "{},{}".format(data["result"][i]["x"],data["result"][i]["y"])
})
break
else:
print(data)
except Exception as e:
# print("\n Error: ", repr(e))
traceback.print_exc()
# 线程1: 访问 url 获取结果
def producer(self):
while self.groups_q.empty() is False:
group = self.groups_q.get()
self.req(group)
# 线程2:将线程1的结果存入数据库
def write(self):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
while (self.groups_q.empty() is False) or (self.valid_q.empty() is False):
if self.valid_q.empty() is False:
data = self.valid_q.get()
col.update_one({
"panoid": data["panoid"]
},
{
"$set":{
"bd09mc": data["bd09mc"],
"bd09ll": data["bd09ll"],
"ok": 3
}
})
# 线程3: 进度条显示
def pbar(self):
state = [0, 0]
while (self.groups_q.empty() is False) or (self.valid_q.empty() is False):
if [self.lenth-self.groups_q.qsize(), self.valid_q.qsize()] != state:
state = [self.lenth-self.groups_q.qsize(), self.valid_q.qsize()]
print("Processing: {}/{}, time elapse: {:.0f}s, waiting for update: {}".format(self.lenth-self.groups_q.qsize(), self.lenth, time.time()-self.start, self.valid_q.qsize()))
time.sleep(1)
def run(self):
ths =[]
pbar_thread = Thread(target=self.pbar)
pbar_thread.start()
ths.append(pbar_thread)
for _ in range(self.thread_num):
producer_thread = Thread(target=self.producer)
producer_thread.start()
ths.append(producer_thread)
write_thread = Thread(target=self.write)
write_thread.start()
ths.append(write_thread)
# 阻塞主线程
for th in ths:
th.join()
print("Time consume:", time.time()-self.start, "s")
if __name__ == ‘__main__‘:
Spider().run()
使用的是别人写好的代码作为基础(忘记出处了~
import math
PI = math.pi
PIX = math.pi * 3000 / 180
EE = 0.00669342162296594323
A = 6378245.0
def bd09_to_gcj02(lng, lat):
"""BD09 -> GCJ02"""
x, y = lng - 0.0065, lat - 0.006
z = math.sqrt(x * x + y * y) - 0.00002 * math.sin(y * PIX)
theta = math.atan2(y, x) - 0.000003 * math.cos(x * PIX)
lng, lat = z * math.cos(theta), z * math.sin(theta)
return lng, lat
def gcj02_to_bd09(lng, lat):
"""GCJ02 -> BD09"""
z = math.sqrt(lng * lng + lat * lat) + 0.00002 * math.sin(lat * PIX)
theta = math.atan2(lat, lng) + 0.000003 * math.cos(lng * PIX)
lng, lat = z * math.cos(theta) + 0.0065, z * math.sin(theta) + 0.006
return lng, lat
def gcj02_to_wgs84(lng, lat):
"""GCJ02 -> WGS84"""
if out_of_china(lng, lat):
return lng, lat
dlat = transform_lat(lng - 105.0, lat - 35.0)
dlng = transform_lng(lng - 105.0, lat - 35.0)
radlat = lat / 180.0 * PI
magic = math.sin(radlat)
magic = 1 - EE * magic * magic
sqrtmagic = math.sqrt(magic)
dlat = (dlat * 180.0) / ((A * (1 - EE)) / (magic * sqrtmagic) * PI)
dlng = (dlng * 180.0) / (A / sqrtmagic * math.cos(radlat) * PI)
lng, lat = lng - dlng, lat - dlat
return lng, lat
def wgs84_to_gcj02(lng, lat):
"""WGS84 -> GCJ02"""
if out_of_china(lng, lat):
return lng, lat
dlat = transform_lat(lng - 105.0, lat - 35.0)
dlng = transform_lng(lng - 105.0, lat - 35.0)
radlat = lat / 180.0 * PI
magic = math.sin(radlat)
magic = 1 - EE * magic * magic
sqrtmagic = math.sqrt(magic)
dlat = (dlat * 180.0) / ((A * (1 - EE)) / (magic * sqrtmagic) * PI)
dlng = (dlng * 180.0) / (A / sqrtmagic * math.cos(radlat) * PI)
lng, lat = lng + dlng, lat + dlat
return lng, lat
def mapbar_to_wgs84(lng, lat):
"""MapBar -> WGS84"""
lng = lng * 100000.0 % 36000000
lat = lat * 100000.0 % 36000000
lng1 = int(lng - math.cos(lat / 100000.0) * lng / 18000.0 - math.sin(lng / 100000.0) * lat / 9000.0)
lat1 = int(lat - math.sin(lat / 100000.0) * lng / 18000.0 - math.cos(lng / 100000.0) * lat / 9000.0)
lng2 = int(lng - math.cos(lat1 / 100000.0) * lng1 / 18000.0 - math.sin(lng1 / 100000.0) * lat1 / 9000.0 + (1 if lng > 0 else -1))
lat2 = int(lat - math.sin(lat1 / 100000.0) * lng1 / 18000.0 - math.cos(lng1 / 100000.0) * lat1 / 9000.0 + (1 if lat > 0 else -1))
lng, lat = lng2 / 100000.0, lat2 / 100000.0
return lng, lat
def transform_lat(lng, lat):
"""GCJ02 latitude transformation"""
ret = -100 + 2.0 * lng + 3.0 * lat + 0.2 * lat * lat + 0.1 * lng * lat + 0.2 * math.sqrt(math.fabs(lng))
ret += (20.0 * math.sin(6.0 * lng * PI) + 20.0 * math.sin(2.0 * lng * PI)) * 2.0 / 3.0
ret += (20.0 * math.sin(lat * PI) + 40.0 * math.sin(lat / 3.0 * PI)) * 2.0 / 3.0
ret += (160.0 * math.sin(lat / 12.0 * PI) + 320.0 * math.sin(lat * PI / 30.0)) * 2.0 / 3.0
return ret
def transform_lng(lng, lat):
"""GCJ02 longtitude transformation"""
ret = 300.0 + lng + 2.0 * lat + 0.1 * lng * lng + 0.1 * lng * lat + 0.1 * math.sqrt(math.fabs(lng))
ret += (20.0 * math.sin(6.0 * lng * PI) + 20.0 * math.sin(2.0 * lng * PI)) * 2.0 / 3.0
ret += (20.0 * math.sin(lng * PI) + 40.0 * math.sin(lng / 3.0 * PI)) * 2.0 / 3.0
ret += (150.0 * math.sin(lng / 12.0 * PI) + 300.0 * math.sin(lng / 30.0 * PI)) * 2.0 / 3.0
return ret
def out_of_china(lng, lat):
"""No offset when coordinate out of China."""
if lng < 72.004 or lng > 137.8437:
return True
if lat < 0.8293 or lat > 55.8271:
return True
return False
def bd09_to_wgs84(lng, lat):
"""BD09 -> WGS84"""
lng, lat = bd09_to_gcj02(lng, lat)
lng, lat = gcj02_to_wgs84(lng, lat)
return lng, lat
def wgs84_to_bd09(lng, lat):
"""WGS84 -> BD09"""
lng, lat = wgs84_to_gcj02(lng, lat)
lng, lat = gcj02_to_bd09(lng, lat)
return lng, lat
def mapbar_to_gcj02(lng, lat):
"""MapBar -> GCJ02"""
lng, lat = mapbar_to_wgs84(lng, lat)
lng, lat = wgs84_to_gcj02(lng, lat)
return lng, lat
def mapbar_to_bd09(lng, lat):
"""MapBar -> BD09"""
lng, lat = mapbar_to_wgs84(lng, lat)
lng, lat = wgs84_to_bd09(lng, lat)
return lng, lat
if __name__ == ‘__main__‘:
blng, blat = 121.4681891220,31.1526609317
print(‘BD09:‘, (blng, blat))
print(‘BD09 -> GCJ02:‘, bd09_to_gcj02(blng, blat))
print(‘BD09 -> WGS84:‘,bd09_to_wgs84(blng, blat))
wlng, wlat = 121.45718237717077, 31.14846209914084
print(‘WGS84:‘, (wlng, wlat))
print(‘WGS84 -> GCJ02:‘, wgs84_to_gcj02(wlng, wlat))
print(‘WGS84 -> BD09:‘, wgs84_to_bd09(wlng, wlat))
mblng, mblat = 121.4667323772, 31.1450420991
print(‘MapBar:‘, (mblng, mblat))
print(‘MapBar -> WGS84:‘, mapbar_to_wgs84(mblng, mblat))
print(‘MapBar -> GCJ02:‘, mapbar_to_gcj02(mblng, mblat))
print(‘MapBar -> BD09:‘, mapbar_to_bd09(mblng, mblat))
然后在自己的代码里引入converter.py
import pymongo
from queue import Queue
from threading import Thread
import math
import time, random
import traceback
from converter import *
class Spider():
def __init__(self):
self.thread_num = 5
self.start = time.time()
self.points_q = self.get_points()
self.lenth = self.points_q.qsize()
self.valid_q = Queue()
def get_points(self):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
docs = col.find({"ok": 3})
points_q = Queue()
if docs:
points = [[doc["panoid"], doc["bd09ll"]] for doc in docs]
for point in points:
points_q.put(point)
return points_q
return points_q
# 线程1: 转换坐标
def producer(self):
while self.points_q.empty() is False:
panoid, point = self.points_q.get()
lon, lat = point.split(",")
lon, lat = float(lon), float(lat)
nlon, nlat = gcj02_to_wgs84(lon, lat)
self.valid_q.put({
"panoid": panoid,
"wgs84": "{},{}".format(nlon, nlat)
})
# 线程2:将线程1的结果存入数据库
def write(self):
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["area"]
col = db["streetview"]
while (self.points_q.empty() is False) or (self.valid_q.empty() is False):
if self.valid_q.empty() is False:
data = self.valid_q.get()
col.update_one({
"panoid": data["panoid"]
},
{
"$set":{
"wgs84": data["wgs84"],
"ok": 4
}
})
# 线程3: 进度条显示
def pbar(self):
state = [0, 0]
while (self.points_q.empty() is False) or (self.valid_q.empty() is False):
if [self.lenth-self.points_q.qsize(), self.valid_q.qsize()] != state:
state = [self.lenth-self.points_q.qsize(), self.valid_q.qsize()]
print("Processing: {}/{}, time elapse: {:.0f}s, waiting for update: {}".format(self.lenth-self.points_q.qsize(), self.lenth, time.time()-self.start, self.valid_q.qsize()))
time.sleep(1)
def run(self):
ths =[]
pbar_thread = Thread(target=self.pbar)
pbar_thread.start()
ths.append(pbar_thread)
for _ in range(self.thread_num):
producer_thread = Thread(target=self.producer)
producer_thread.start()
ths.append(producer_thread)
write_thread = Thread(target=self.write)
write_thread.start()
ths.append(write_thread)
# 阻塞主线程
for th in ths:
th.join()
print("Time consume:", time.time()-self.start, "s")
if __name__ == ‘__main__‘:
Spider().run()
原文:https://www.cnblogs.com/IvyWong/p/14057711.html