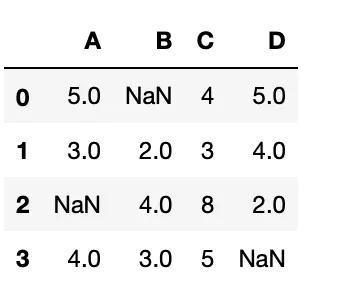
构建数据如下:
import pandas as pd df=pd.DataFrame({"A":[5,3,None,4], "B":[None,2,4,3], "C":[4,3,8,5], "D":[5,4,2,None]}) df
输出
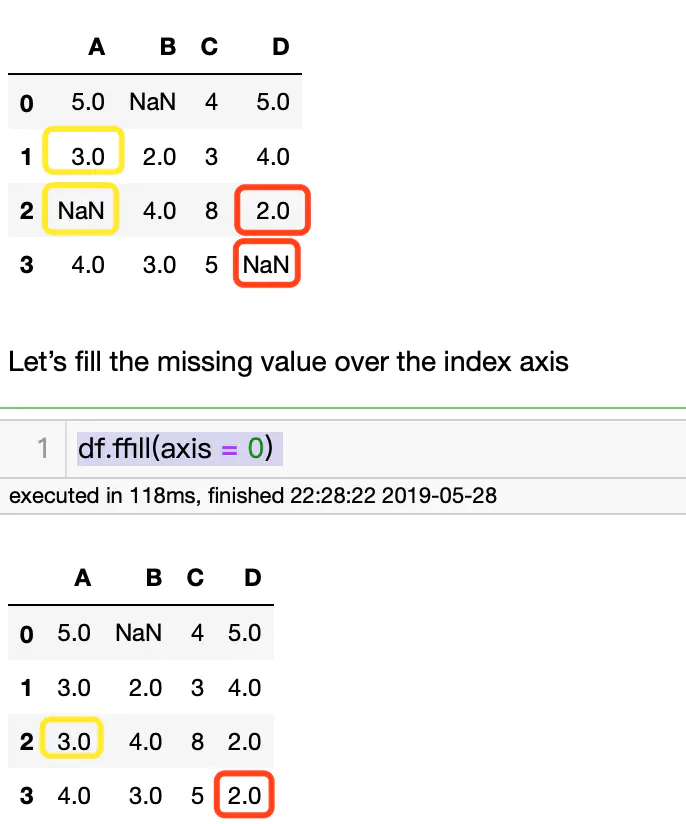
分别使用前一行/前一列数据填充后面的Nan
df.ffill(axis = 0)
df.ffill(axis = 1)

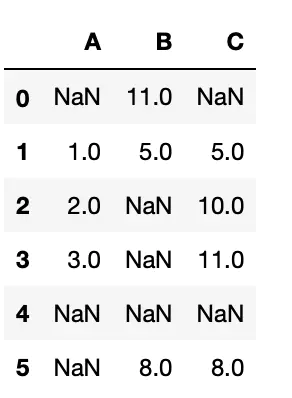
构建数据如下:
# importing pandas as pd import pandas as pd df = pd.DataFrame({"A":[None, 1, 2, 3, None, None], "B":[11, 5, None, None, None, 8], "C":[None, 5, 10, 11, None, 8]}) df
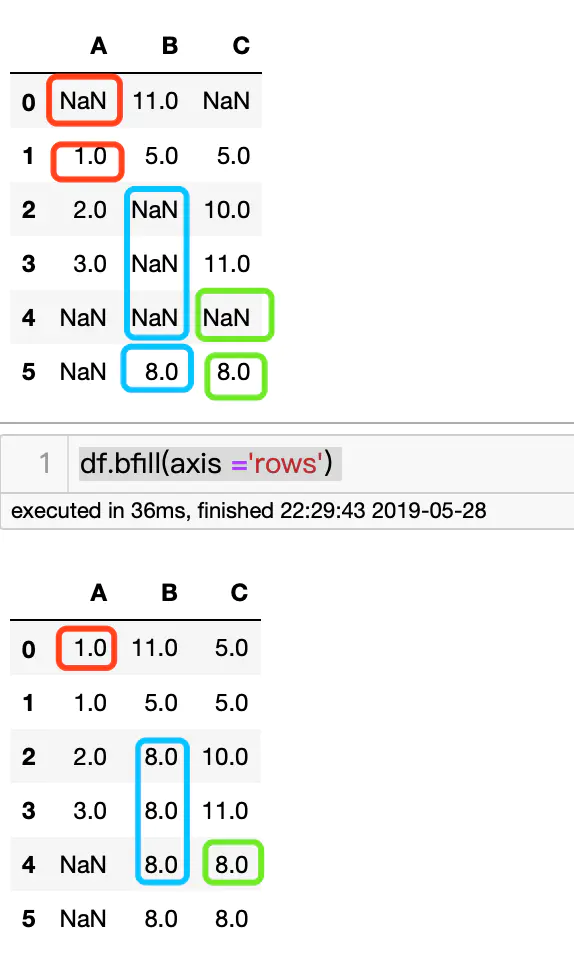
分别使用后一行/后一列数据填充前面的Nan
df.bfill(axis =‘rows‘) #df.bfill(axis =0) 等价
df.bfill(axis =‘columns‘) #df.bfill(axis =1) 等价


import pandas as pd df = pd.read_csv("apple.csv", parse_dates =["date"], index_col ="date") #parse_dates:boolean or list of ints or names or list of lists or dict, default False. 这个参数指定对CSV文件中日期序列的处理方式: #默认为False,原样加载,不解析日期时间, #可以为True,尝试解析日期索引, #可以为数字或 names 的列表,解析指定的列为时间序列, #可以为以列表为元素的列表,解析每个子列表中的字段组合为时间序列, #可以为值为列表的字典,解析每个列表中的字段组合为时间序列,并命名为字典中对应的键值; # Printing the first 10 rows of dataframe df[:10]
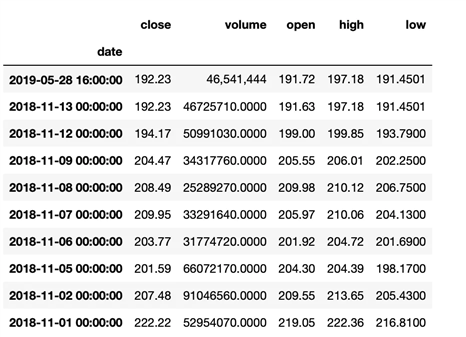
要求按月统计苹果股票的close价格的平均值
解决方法如下:
monthly_resampled_data = df.close.resample(‘M‘).mean() monthly_resampled_data
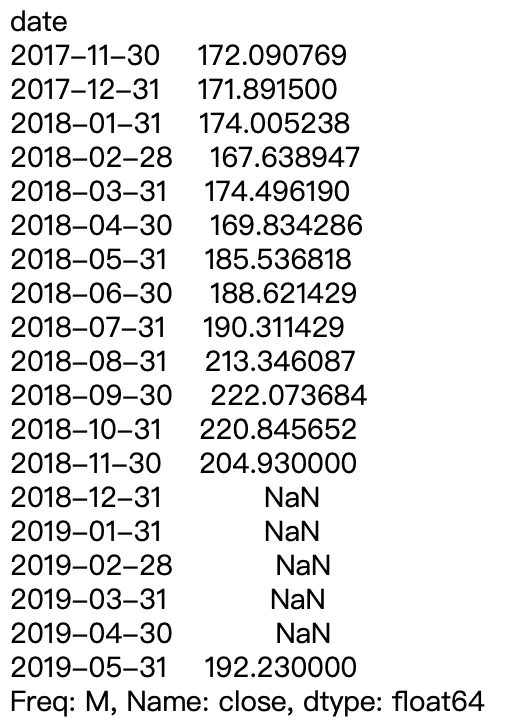
要求按季度统计苹果股票的open价格的平均值
解决方法如下:
Quarterly_resampled_data = df.open.resample(‘Q‘).mean() Quarterly_resampled_data

现有Series序列如下:
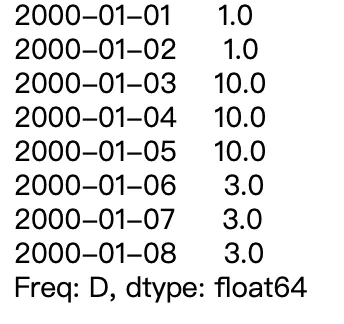
ser = pd.Series([1,10,3, np.nan], index=pd.to_datetime([‘2000-01-01‘, ‘2000-01-03‘, ‘2000-01-06‘, ‘2000-01-08‘])) ser

要求,重新按照天来resample,并填充控制与Nan值,产生如下输出
解决方法如下:
ser.resample(‘D‘).ffill().ffill()
原文:https://www.cnblogs.com/tracydzf/p/14081494.html