现有数据如下:
df = pd.read_csv(‘https://raw.githubusercontent.com/selva86/datasets/master/Cars93_miss.csv‘)
数据如下:
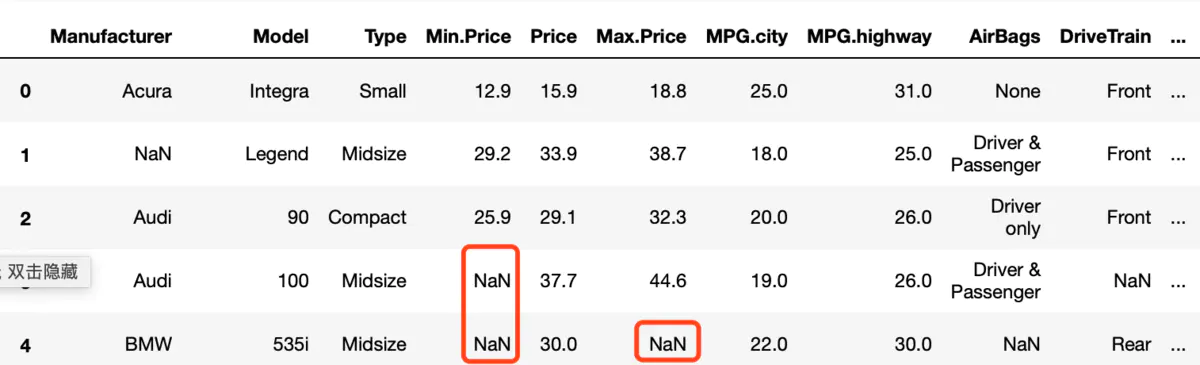
把‘Min.Price‘, ‘Max.Price‘缺失的值用该列的均值填充
解决方法如下:
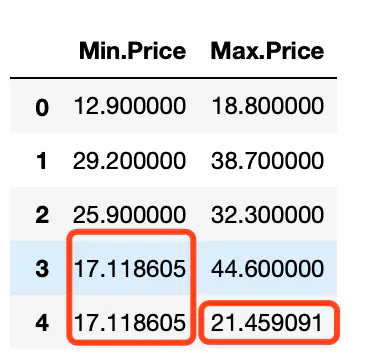
df_out = df[[‘Min.Price‘, ‘Max.Price‘]] = df[[‘Min.Price‘, ‘Max.Price‘]].apply(lambda x: x.fillna(x.mean())) df_out
现有数据如下:
df = pd.read_csv(‘https://raw.githubusercontent.com/selva86/datasets/master/Cars93_miss.csv‘)
数据如下:
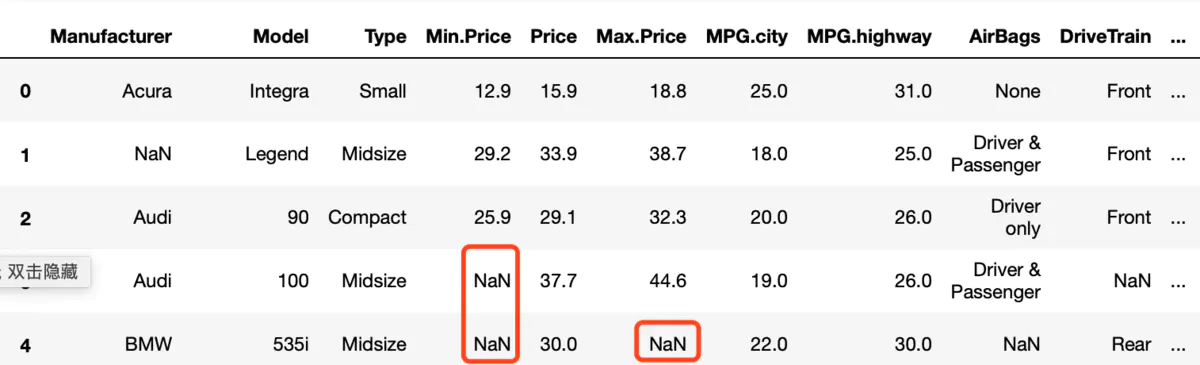
把‘Min.Price‘, ‘Max.Price‘缺失的值用该列的均值,中位数填充
解决方法如下
d = {‘Min.Price‘: np.nanmean, ‘Max.Price‘: np.nanmedian}
df[[‘Min.Price‘, ‘Max.Price‘]] = df[[‘Min.Price‘, ‘Max.Price‘]].apply(lambda x, d : x.fillna(d[x.name](x)), args=(d, ))
df
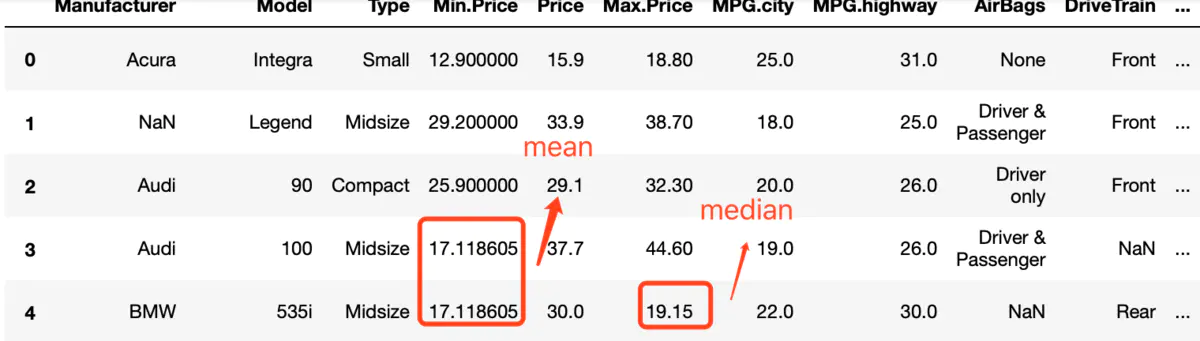
重点解读: df[[‘Min.Price‘, ‘Max.Price‘]].apply(lambda x, d : x.fillna(d[x.name]), args=(d, ))appley中,可以通过args参数传递全局变量,本例中传递的是d,注意传递是元组,所以别忘了后面的“,”。
原文:https://www.cnblogs.com/tracydzf/p/14085141.html