Docker利用Linux中的核心分离机制,例如Cgroups,以及Linux的核心Namespace(名字空间)来创建独立的容器。一句话概括起来Docker就是利用Namespace做资源隔离,用Cgroup做资源限制,利用Union FS做容器文件系统的轻量级虚拟化技术。Docker容器的本质还是一个直接运行在宿主机上面的特殊进程,看到的文件系统是隔离后的,但是操作系统内核是共享宿主机OS,所以说Docker是轻量级的虚拟化技术。

命名空间(namespaces)是 Linux 为我们提供的用于分离进程树、网络接口、挂载点以及进程间通信等资源的方法。在日常使用 Linux 或者 macOS 时,我们并没有运行多个完全分离的服务器的需要,但是如果我们在服务器上启动了多个服务,这些服务其实会相互影响的,每一个服务都能看到其他服务的进程,也可以访问宿主机器上的任意文件,这是很多时候我们都不愿意看到的,我们更希望运行在同一台机器上的不同服务能做到完全隔离,就像运行在多台不同的机器上一样。
在这种情况下,一旦服务器上的某一个服务被入侵,那么入侵者就能够访问当前机器上的所有服务和文件,这也是我们不想看到的,而 Docker 其实就通过 Linux 的 Namespaces 对不同的容器实现了隔离。
Linux 的命名空间机制提供了以下七种不同的命名空间,包括 CLONE_NEWCGROUP、CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID、CLONE_NEWUSER 和 CLONE_NEWUTS,通过这七个选项我们能在创建新的进程时设置新进程应该在哪些资源上与宿主机器进行隔离。
进程是 Linux 以及现在操作系统中非常重要的概念,它表示一个正在执行的程序,也是在现代分时系统中的一个任务单元。在每一个 *nix 的操作系统上,我们都能够通过 ps 命令打印出当前操作系统中正在执行的进程,比如在 Ubuntu 上,使用该命令就能得到以下的结果:
$ ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 0 Apr08 ? 00:00:09 /sbin/init root 2 0 0 Apr08 ? 00:00:00 [kthreadd] root 3 2 0 Apr08 ? 00:00:05 [ksoftirqd/0] root 5 2 0 Apr08 ? 00:00:00 [kworker/0:0H] root 7 2 0 Apr08 ? 00:07:10 [rcu_sched] root 39 2 0 Apr08 ? 00:00:00 [migration/0] root 40 2 0 Apr08 ? 00:01:54 [watchdog/0] ...
当前机器上有很多的进程正在执行,在上述进程中有两个非常特殊,一个是 pid 为 1 的 /sbin/init 进程,另一个是 pid 为 2 的 kthreadd 进程,这两个进程都是被 Linux 中的上帝进程 idle 创建出来的,其中前者负责执行内核的一部分初始化工作和系统配置,也会创建一些类似 getty 的注册进程,而后者负责管理和调度其他的内核进程。
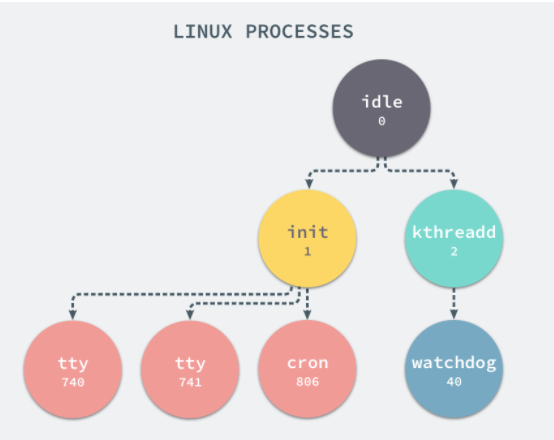
如果我们在当前的 Linux 操作系统下运行一个新的 Docker 容器,并通过 exec 进入其内部的 bash 并打印其中的全部进程,我们会得到以下的结果:
root@iZ255w13cy6Z:~# docker run -it -d ubuntu b809a2eb3630e64c581561b08ac46154878ff1c61c6519848b4a29d412215e79 root@iZ255w13cy6Z:~# docker exec -it b809a2eb3630 /bin/bash root@b809a2eb3630:/# ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 0 15:42 pts/0 00:00:00 /bin/bash root 9 0 0 15:42 pts/1 00:00:00 /bin/bash root 17 9 0 15:43 pts/1 00:00:00 ps -ef
在新的容器内部执行 ps 命令打印出了非常干净的进程列表,只有包含当前 ps -ef 在内的三个进程,在宿主机器上的几十个进程都已经消失不见了。
当前的 Docker 容器成功将容器内的进程与宿主机器中的进程隔离,如果我们在宿主机器上打印当前的全部进程时,会得到下面三条与 Docker 相关的结果:
UID PID PPID C STIME TTY TIME CMD root 29407 1 0 Nov16 ? 00:08:38 /usr/bin/dockerd --raw-logs root 1554 29407 0 Nov19 ? 00:03:28 docker-containerd -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --metrics-interval=0 --start-timeout 2m --state-dir /var/run/docker/libcontainerd/containerd --shim docker-containerd-shim --runtime docker-runc root 5006 1554 0 08:38 ? 00:00:00 docker-containerd-shim b809a2eb3630e64c58
在当前的宿主机器上,可能就存在由上述的不同进程构成的进程树:
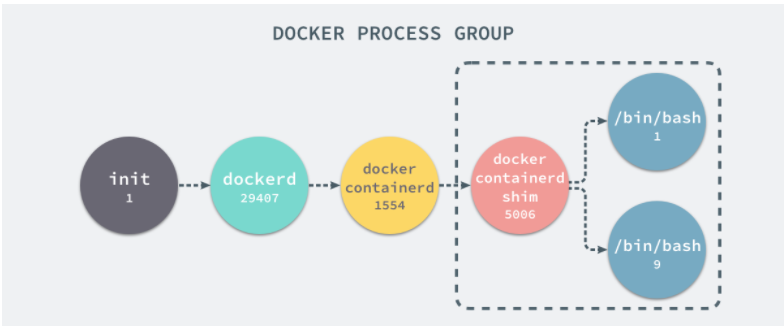
这就是在使用 clone(2) 创建新进程时传入 CLONE_NEWPID 实现的,也就是使用 Linux 的命名空间实现进程的隔离,Docker 容器内部的任意进程都对宿主机器的进程一无所知。
containerRouter.postContainersStart
└── daemon.ContainerStart
└── daemon.createSpec
└── setNamespaces
└── setNamespace
Docker 的容器就是使用上述技术实现与宿主机器的进程隔离,当我们每次运行 docker run 或者 docker start 时,都会在下面的方法中创建一个用于设置进程间隔离的 Spec:
func (daemon *Daemon) createSpec(c *container.Container) (*specs.Spec, error) { s := oci.DefaultSpec() // ... if err := setNamespaces(daemon, &s, c); err != nil { return nil, fmt.Errorf("linux spec namespaces: %v", err) } return &s, nil }
在 setNamespaces 方法中不仅会设置进程相关的命名空间,还会设置与用户、网络、IPC 以及 UTS 相关的命名空间:
func setNamespaces(daemon *Daemon, s *specs.Spec, c *container.Container) error { // user // network // ipc // uts // pid if c.HostConfig.PidMode.IsContainer() { ns := specs.LinuxNamespace{Type: "pid"} pc, err := daemon.getPidContainer(c) if err != nil { return err } ns.Path = fmt.Sprintf("/proc/%d/ns/pid", pc.State.GetPID()) setNamespace(s, ns) } else if c.HostConfig.PidMode.IsHost() { oci.RemoveNamespace(s, specs.LinuxNamespaceType("pid")) } else { ns := specs.LinuxNamespace{Type: "pid"} setNamespace(s, ns) } return nil }
所有命名空间相关的设置 Spec 最后都会作为 Create 函数的入参在创建新的容器时进行设置:
daemon.containerd.Create(context.Background(), container.ID, spec, createOptions)
所有与命名空间的相关的设置都是在上述的两个函数中完成的,Docker 通过命名空间成功完成了与宿主机进程和网络的隔离。
原文:https://www.cnblogs.com/peteremperor/p/14110582.html