awk 选项 条件 语句 文件
-f 从文件中读取处理命令
-F 指明行的段分隔符;分割针对输入时的数据。支持模式匹配。扩展的正则表达式,目的是将行分割成为多个对象.或确定每次循环时待处理的对象(最小待处理单位)是什么.默认的
-v 自定义变量
awk -v
awk是一门语言,请以编程的视角去看待条件。
条件为执行条件后的语句的要求。符合条件才可执行语句,条件即为对语句的判断,可以使用正则匹配,基于正则的模式定界,字符串比较,可以使用算数条件表达式,也可以是BEGIN,END特殊条件。
算数条件表达式,最终返回运算结果,当运算结果为0时,语句不执行。
在进行条件验证时行已经被分割成最小的单位,并已经对最小单位的小数量,内容,行号等信息进行了统计。当条件为空时执行每一行
例:
awk ‘/^UUID/{print $1}‘ /etc/fstab #匹配以UUID为开始的行,并执行{}中的语句。print $1
awk ‘!/^UUID/{print $1}‘ /etc/fstab #匹配以非UUID为开始的行,执行{}中的语句 。print $1
例:算数计算_条件为真该行才会被处理 ,条件 为假则不处理 。
awp -F: ‘$3>=1000{print $1,$3}‘ /etc/passwd
awp -F: ‘!$3>=1000{print $1,$3}‘ /etc/passwd
awk -F: ‘(NR>=2&&NR<=10){print $1}‘
例:字符串比较_比较结果为真进入循环
awk -F:‘$NF="/bin/bash"{print $1,$NF}‘ /bin/passwd
awk -F:‘$NF~/bash$/{print $1,$NF}‘ /bin/passwd
awk -F: ‘! ($NF=="/bin/bash")‘ /etc/passwd
例:行范围_范围内的行做处理 ,好像只支持模式定界
awk -F:‘10,20{print $1}‘ #----失败了
awk -F:‘/^root/,/^myuser/{print $1}‘
例:特殊条件_BEGIN/END
awk ‘BEGIN{print " username ID \n------------"}{printf "%10s:%-s" $1,$3}END{print "=========\n"}‘
# BEGIN:在开始之前显示一次
# END:在文本处理完成 ,命令未完成时,执行一次
例:特殊条件_0,空
awk -v aa="" ‘aa‘ /etc/passwd #变量aa的值为空 ,(语句为空执行默认语句)。但是条件为空,不执行默认语句。
awk -v aa=" " ‘aa‘ /etc/passwd #变量aa的值为‘ ’空格不为空执行默认语句
awk -v aa="0" ‘aa‘ /etc/passwd #变量aa的值为0,条件为最终值为0,默认语句不执行。
awk -v aa="1" ‘aa‘ /etc/passwd #变量aa的值为1 ,条件返回值为1,默认语句执行。
awk -v aa=0 ‘aa++‘ /etc/passwd #aa初始值为0,第一条语句条件为a++,首先返回a的值在进行自加运算。所以打印第一行外所有行。
echo "123"| awk -v a=1 ‘a=0{print $1}‘ #a的初始值为1.第一条语句条件为a=0,对a进行了重新赋值。此时返回a赋值后的值,条件为0,语句不执行。
符合条件执行的动作,awk是一门语言,所以以编程的思维去思考。只是awk的变量大多数是awk自动赋值的。并在内部根据自己的规则自动变化(比如行计数器NR,又比如$1等)
当{}中存在多条语句时使用;进行分隔。当语句为空时,默认执行{print $0} awk ‘!0‘ /etc/passwd
打印 打印的类型需要进行设定
“” 定义字符串
数值直接为数值
$为最小元素引用
变量直接引用
在不指定打印内容时,打印整个行(我就这么一写)
#在没有指定条件,以及没有指定print输出的内容时,默认输出整行
例: >>echo "hello" |awk ‘{print}‘
hello
#在指定了多个输出内容时,对象的格式不同,使用的定义也不同
例:
echo "hello word" |awk ‘{print $1"\t"$2}‘
hello word
echo "hello word" |awk -F‘ ‘ ‘{print $1"---"$2}‘
hello---word
echo "hello word" |awk -F‘ ‘ ‘{nu=10;print $1"---"$2"---"nu}‘
hello---word---10
#在没有使用,分割字段时,默认字段是连续的,定义了输出的字段,分割的是每个输出的字段
例:
echo "hello word" |awk -F‘ ‘ ‘{print $1$2}‘
helloword
echo "hello:word:haha:asd" |awk -v FS=‘:‘ -v OFS=‘---‘ ‘{print $1$2}‘
helloword
echo "hello:word:haha:asd" |awk -v FS=‘:‘ -v OFS=‘---‘ ‘{print $1,$2}‘
hello---word
echo "hello:word:haha:asd" |awk -v FS=‘:‘ -v OFS=‘---‘ ‘{print $1,$2,$1$2}‘
hello---word---helloword
格式化输出字符串
格式符:
%c ascii
echo "asd"| awk ‘{printf "%c\n",$1}‘
%d i 十进制 整数
echo "123"| awk ‘{printf "%-d\n",$1}‘
%e %E 科学记数法
%f 显示 浮点数
%s 显示 字符串
echo "123"| awk ‘{printf "%s\n",$1}‘
123
echo "123"| awk ‘{printf "%s\n","asd"}‘
asd
%% 显示%自身
%g %G 以科学技术法显示
%u 无符号的 整数
修饰符 :
# 显示宽度
#。#;第二个 # 表示 小数点 后的精度
- : 左对齐,默认右对齐。
+ :显示数字的正负符号
格式:条件?条件为真的语句:条件为假的语句
awk ‘{$3>=1000?usertype="......":usertype="::::::";printf "%15s:%-s\n",$1,usertype}’
if:
格式:
if(条件){语句}
if(条件){语句} else {语句}
例:
awk -F: ‘{if($3>1000) print $1,$3}‘ /etc/passwd #打印非系统用户
awk -F: ‘{if($3>1000){printf "普通用户:%s",$1} else {printf "系统用户:%s",$1}}‘ #对系统的用户进行判断,输出结果。
df -h |awk -F% ‘/\/dev\/sd/{print $1}‘|awk ‘{if($NF>=16)print $1}‘
df -h |awk -F% ‘/\/dev\/sd/{print $1}‘|awk ‘$NF>=16{print $1}‘
while:
while (条件) {语句}
条件为真进入循环 ,条件为假退出循环。
awk ‘/^[[:space:]]*linux/{i=1;while(i<NF){print $i,length($i);i++}}‘ /etc/grub2.cfg
awk ‘/^[[:space:]]*linux/{i=1;while(i<NF){if(length($i)>7){print $i,length($i)};i++}}‘ /etc/grub2.cfg
awk ‘/^[[:space:]]*linux16/{i=1;while(i<=NF) {if(length($i)>=10){print $i,length($i)}; i++}}‘ /etc/grub2.cfg
do:
do{语句} while(条件)
首先执行do后面的语句。然后对while中的条件进行判断。条件符合继续执行do后的语句。
awk ‘BEGIN{total=0;i=0;do{total+=i;i++;}while(i<=100);print total}‘
awk ‘BEGIN{total=0;i=0;while(i<=100){total+=i;i++};print total}‘
for:
for (i=1;i<10;i++){语句}
awk /[[:space:]]*linux/{for(i=1;i<=NF;i++){print $i,length($i)}} /etc/grub2.cfg
for可以实现遍历数组元素 :
格式 :for (i in 数组名称)遍历时 i被赋值的是每个索引,
循环跳转
break
跳出当前循环,break # :跳出#层循环
contiune
结束本次次循环, continue # :结束啊 #层的本次循环。
next :结束 当前行的处理,读取下一行。gawk 的自带循环 ,结束行的处理,进入下一行
awk -F: ‘{if($3%2!=0) next;print $0 }‘ /etc/passwd
打印奇数行
delete
exit
内置函数
lrngth
统计指定字符串的长度,并返回。
例: echo "asdd"|awk ‘{print length($1)}‘ #统计字符串出现的次数。
rand,srand
rand,与srand 组合使用返回一个随机数
例: awk ‘BEGIN{srand();for(i=1;i<=10;i++){print int(rand()*100)}}‘
sub
格式sub(r,s,[t])
处理字符串t(可以是单纯的字符串,变量,位置引用),对t进行模式匹配,模式定义在r中,将模式r所匹配的内容替换成s中的内容,但是只进行1次替换
例: echo "2008:08:08:08 08:08:08:08" |awk ‘sub(/:/,"-",$0)‘
gsub
格式 gsub (r,s,[t])
处理字符串t(可以是单纯的字符串,变量,位置引用),对t进行模式匹配,模式定义在r中,将模式r所匹配的内容替换成s中的内容,对于待处理的字符串t进行全局替换。
例: echo "Yd$C@M05MB%9&Bdh7dq+YVixp3vpw"|awk ‘{gsub(/[^0-9]/,"",$0);print $0}‘
echo "Yd$C@M05MB%9&Bdh7dq+YVixp3vpw"|awk ‘gsub(/[^0-9]/,"",$0)‘
split
格式 split(a,array,[r])
以r为分隔符,分割字符串a,并将分割后的字符串分别存入数组,数组的下标从1开始,第一个索引为1,第二个索引为2.
netstat -tan |awk ‘/^tcp/{split($4,ip,":");a[ip[1]]++}END{for(i in a){print i,a[ip[1]]}}‘
int
格式 int(需要转换的小数,或字符串)
将指定的内容转换为整数类型。
system
格式: system("系统命令")
将传入的字符串以系统命令方式执行。命令先经过bash解释传入,所有传入时到awk解释时,必须保证是需求的字符,在经过awk解释时,必须符合awk的语法。也就是保证经bash解释后成为符合awk语法格式切符合需求的字符。或者确保传入的函数的值,为需要的值。
例:awk ‘BEGIN{system("hostname")}‘
awk ‘system("hostname"){i=0}‘
自定义函数
格式:
function 函数名称 (参数1 ,参数2 。。。){
语句1
语句2
return 数值
}
将语句与函数定义在文件中,使用awk运行。
#cat fun.awk
function max(v1,v2) {
v1>v2?var=v1:var=v2
return var
}
BEGIN{a=3;b=2;print max(a,b)}
#awk –f fun.awk
将语句与函数定义在脚本中,使用shebang,直接运行脚本。
将awk程序写成脚本,直接调用或执行
#cat f1.awk
{if($3>=1000)print $1,$3}
#awk -F: -f f1.awk /etc/passwd
#cat f2.awk
#!/bin/awk –f
#this is a awk script
{if($3>=1000)print $1,$3}
#chmod +x f2.awk
#f2.awk –F: /etc/passwd
awk脚本中传递参数:
格式:
awkfile var=value var2=value2... Inputfile
注意:在BEGIN过程中不可用。直到首行输入完成以后,变
量才可用。可以通过-v 参数,让awk在执行BEGIN之前得到
变量的值。命令行中每一个指定的变量都需要一个-v参数
#cat test.awk
#!/bin/awk –f
{if($3 >=min && $3<=max)print $1,$3}
#chmod +x test.awk
#test.awk -F: min=100 max=200 /etc/passwd
行的分段引用
每个分段之间使用,进行分割,当不使用,进行分割时默认为一个字段,
$1 :该行的第一个元素
$2 :该行的第二个元素
换行符有必要写一下,换个行而已没什么神圣的,解释了是换行不解释就是\n,awk,看到的文本是连续的,或者说是一串,只是到了换行被截断。
内建的变量。
内建变量的赋值 -v FS=" " 每一个-v用来定义一个变量,
FS:输入的字段分割符,默认为空白字符
OFS:输出的字段分隔符,默认也为空白字符。
RS:输入时指明的行分割符,默认就是换行符,
ORS:输出时的行分隔符,默认为换行符
NF :行中的字段数量
NR :行计数器 ,如果跟了多个 文件 ,编号会连续
FNR : 基于文件的 行计数器 。
FILENAME : 当前的文件名
ARGC :命令行中的参数个数
ARGV :命令行中的参数 ,ARGV为数组,参数为命令自身及后跟随的文件 ,语句不计入参数
自定义的变量
-v var=value
在 与语句中 直接 定义
多条与语句之间 使用 ;分隔
算数操作符 :
双目运算符 :
x+y x-y x*y x/y x^y x%y
单目运算符 :
-x :将x 转化为负数
+x :将字符串x 转化为 数值
字符串的 操作符 :连接符什么 鬼
赋值操作符 :
+ += -= *= /= ^= %=
++ --
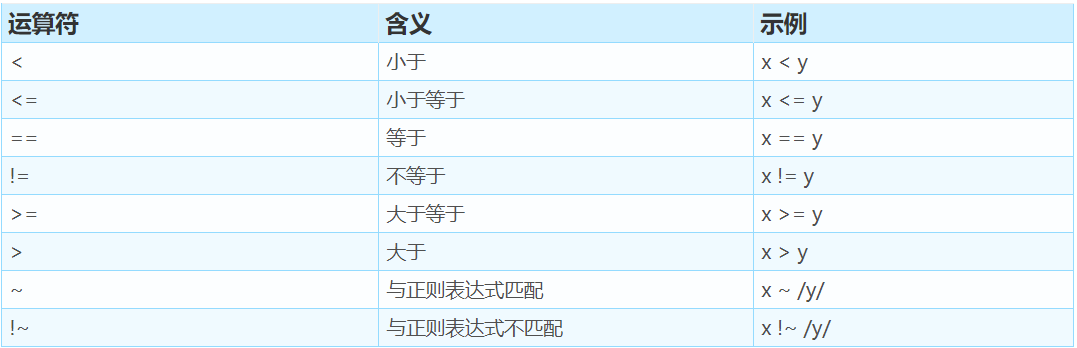
> >= < <= != ==
~ : 是否匹配
!~: 是否 不匹配
下表列出了所有关系运算符。关系表达式的计算结果为真时,表达式的值为1;反之,则为0。
数组:
awk的数组为关联数组,就是Python中的字典。
数组索引可以使用任意的字符串索引,字符串使用引号
如果某数组元素不存在,引用时会创建初始值为none,在进行数学运算时 none会自动转化为0进行计算。
数组赋值
array[\$1]=aa
array[\$1]++
awk ‘!arr[\$0]++‘ /etc/fstab
排除重复的行,取出第一行是对应的数组的内容为空,将none返回然后进行自加后值为1,返回的值经过!取反为真执行默认语句,同样的语句第二次出现时,返回的值为1,经过!取反,值为假,反而不执行.
awk ‘{arr[$0]++;print $0,arr[$0]}‘
打印并统计重复行出现的次数.
遍历数组
netstat -tan | awk ‘/tcp\>/{stat{$NF}++}END{for(i in stat){print i,stat[i]}}
原文:https://www.cnblogs.com/change5/p/14116504.html