本讲将介绍Java代码是如何一步步运行起来的,其中涉及的编译器,类加载器,字节码校验器,解释器和JIT编译器在整个过程中是发挥着怎样的作用。此外还会介绍Java程序所占用的内存是被如何管理的:堆、栈和方法区都各自负责存储哪些内容。最后用一小块代码示例来帮助理解Java程序运行时内存的变化。
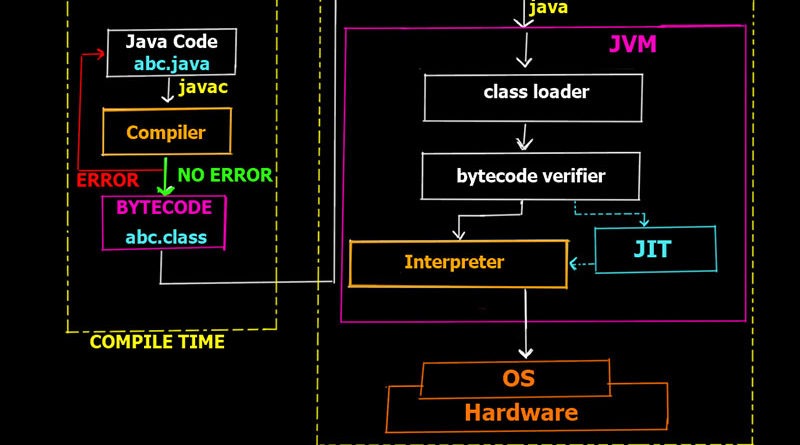
细心的读者可能注意到了,在流程图中还涉及到一个叫JIT的东西在步骤中没有被解释。那么JIT编译器(Just-In-Time Compiler)是如果参与进程序的执行过程中呢?让我们来看以下两个例子。
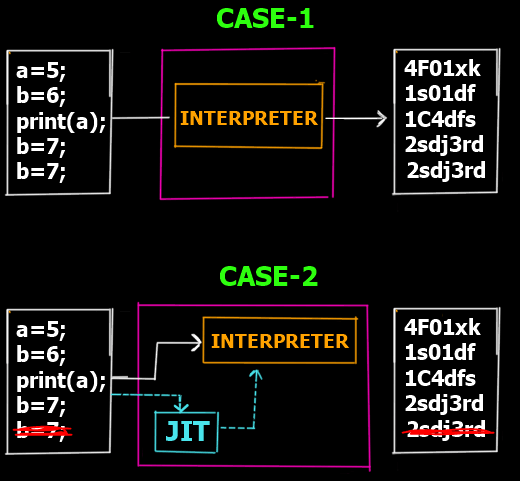
当然,这只是JIT编译器的优化手段之一,不同公司设计的JIT编译器对Java程序的运行会有不同的优化方式。此外需要知道的是,JIT编译器并不是每次都会参与到执行过程中来。
在步骤3中我们谈到字节码会被类加载器载入到内存,那么载入之后JVM是如何对其进行内存管理的呢?
通常,在载入内存后,一个Java程序所占用的内存会被大致分为3块区域:堆(heap),栈(stack)和方法区(method area)。
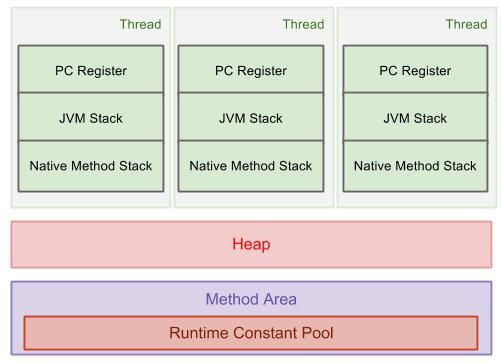
堆:存放new出来的东西。
栈:存放局部变量。
方法区:类型信息,字段信息,常量池(constant pool),静态变量,方法信息等。
public final class Student extends Object implements Serializable { // 1.类信息
// 2.对象字段信息
private String name;
private int score;
// 3.常量池
public final int id = 0;
public final String gender = "male";
// 4.静态变量
public static int a = 0;
// 5.方法信息
public int getid() {
return id;
}
}
PC寄存器:存放将要执行的指令的地址。(因为机器的脑子不灵活,所以需要一块专门的区域帮他记住执行到哪一步,不然它会忘记)
本地方法栈:与JVM栈所发挥的作用是非常相似的,其区别不过是JVM栈为Java方法服务,而本地方法栈则是为使用到的Native方法服务。有的虚拟机(例如Sun HotSpot虚拟机)甚至直接就把本地方法栈和虚拟机栈合二为一。
每个线程拥有各自独立的(虚拟机)栈、PC寄存器和本地方法栈。而堆和方法区则是所有线程共享的。
最后让我们通过一个小例子来理解Java程序执行时内存的变化。
public class Person {
int id;
int age;
Person(int id1, int age1) {
id = id1;
age = age1;
}
public static void main(String[] args) {
Person Tom = new Person(1, 25);
}
}
首先,在stack中申请了一块内存,这块内存区域名字叫Tom,此时区域里存储的内容为null。
接着,调用Person的构造方法,方法的参数属于局部变量,因此在stack中有两块区域分别存放id1和age1。
通过构造方法,可以new出来一个Person的对象,这个对象连带着其成员变量会被存放在heap中。成员变量id和age的值由存放在stack中的局部变量id1和age1赋予。
最后,将这个对象的引用值(类似于地址)传递给Tom,通过引用值我们就可以找到这个对象。
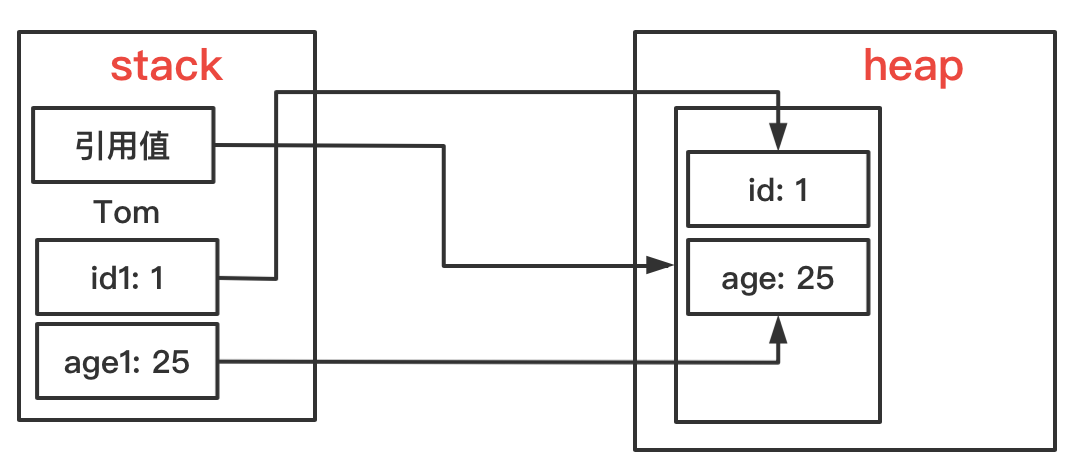
(注意:位于stack中的id1和age1会随着构造方法调用的结束而消失,这里为了更好地表现全过程,因此保留在图中。)
有问题欢迎大家在评论区留言,转载请注明出处。
原文:https://www.cnblogs.com/linj7/p/14122919.html