一、前言
本文基于作者的工程实践课题——基于机器学习的模糊测试框架改进,结合高级软件工程课程中所学知识,进行用例建模、业务建模、数据建模和形成概念模型。
二、项目简介
模糊测试能够检测软件或计算机系统的安全漏洞,近年来比较流行的模糊测试主要是基于反馈的智能化模糊测试引擎比如AFL、libFuzzer等,在AFL中通过遗传算法来生成新的测试用例,本课题主要探究能否在现有模糊测试引擎的基础上通过其他机器学习算法来提升模糊测试的性能和效率,以便在同等算力的情况下发现更多安全问题。
AFL(american fuzzy lop)在前 Google 安全研究员 lcamtuf 耗时数年心血的努力下已经日臻完善,俨然成了 fuzz 工具中独树一帜的存在,相关项目可谓竞相学习与借鉴。目前其更新时间停留于 17 年末,即本文所分析的 2.52b 版本,这之后 lcamtuf 大佬的爱好似乎更热衷摆弄工艺品了; 源码的阅读需要具备基本的 C 语言和 shell 脚本编程功底,因其代码量适当且编程风格良好,亦不失作为 C 语言开源项目学习的好选择。众多安全会议白帽演讲中都介绍过这款工具,以及2016年defcon大会的CGC(Cyber Grand Challenge,形式为机器自动挖掘并修补漏洞)大赛中多支队伍利用AFL fuzzing技术与符号执行(Symbolic Execution)来实现漏洞挖掘,其中参赛队伍shellphish便是采用AFL(Fuzzing) + angr(Symbolic Execution)技术。
本课题所做的就是安全相关的模糊测试工作,通过使用AFL工具,记录输入样本的代码覆盖率,从而调整输入样本以提高覆盖率,增加发现漏洞的概率。
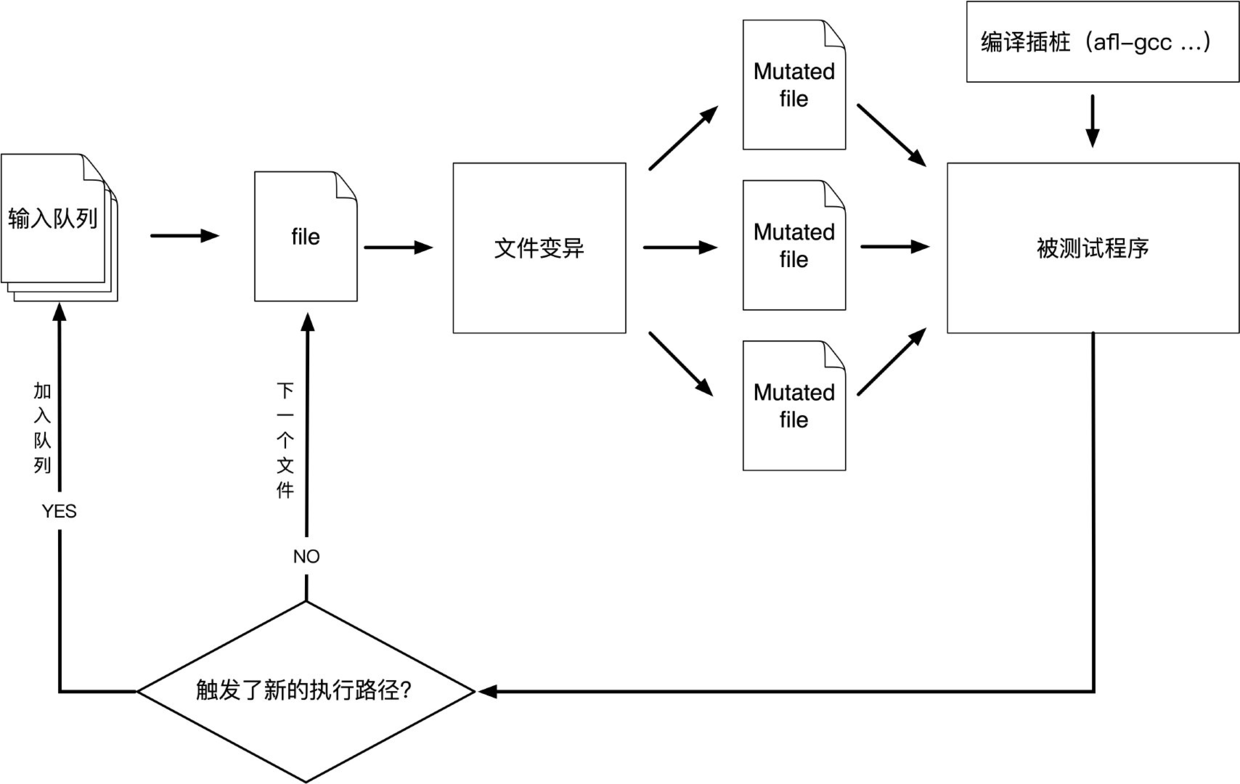
最主要的目的就是使代码覆盖率达到最大,其工作流程大致如下:
①从源码编译程序时进行插桩,以记录代码覆盖率(Code Coverage);
②选择一些输入文件,作为初始测试集加入输入队列(queue);
③将队列中的文件按一定的策略进行变异;
④如果经过变异文件更新了覆盖范围,则将其保留添加到队列中;
⑤上述过程会一直循环进行,期间触发了crash的文件会被记录下来。
大致工作流程如下图所示:
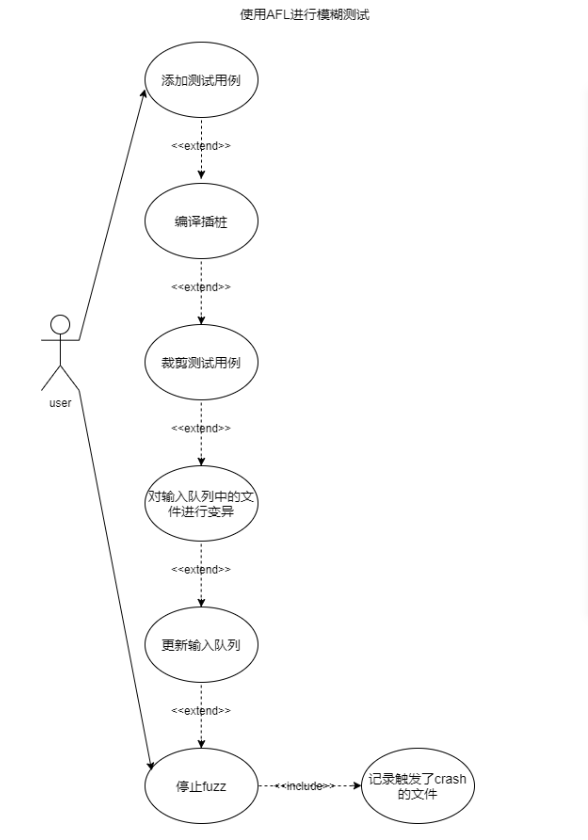
三、项目的完整用例图
用例图用来描述用例与参与者之间的关系。用例图包含了谁是系统的参与者,系统需要提供什么样的服务。用例(Use Case)的核心概念中首先它是一个业务过程(business process),经过逻辑整理抽象出来的一个业务过程,这是用例的实质。而什么是业务过程?在待开发软件所处的业务领域内完成特定业务任务(business task)的一系列活动就是业务过程。用例的三个要素分别是:(1)A use case is initiated by (or begins with) an actor. 一个用例应该由业务领域内的某个参与者(Actor)所触发。(2)A use case must accomplish a business task (for the actor).用例必须能为特定的参与者完成一个特定的业务任务。(3)A use case must end with an actor. 一个用例必须终止于某个特定参与者,也就是特定参与者明确地或者隐含地得到了业务任务完成的结果。
在准确理解用例概念的基础上,我们可以进一步将用例划分为三个抽象层级: 1.抽象用例(Abstract use case)。只要用一个干什么、做什么或完成什么业务任务的动名词短语,就可以非常精简地指明一个用例; 2.高层用例(High level use case)。需要给用例的范围划定一个边界,也就是用例在什么时候什么地方开始,以及在什么时候什么地方结束; 3.扩展用例(Expanded use case)。需要将参与者和待开发软件系统为了完成用例所规定的业务任务的交互过程一步一步详细地描述出来,一般我们使用一个两列的表格将参与者和待开发软件系统之间从用例开始到用例结束的所有交互步骤都列举出来。
第一步,从需求表述中找出用例,往往是动名词短语表示的抽象用例;
第二步,描述用例开始和结束的状态,用TUCBW和TUCEW表示的高层用例;
第三步,对用例按照子系统或不同的方面进行分类,描述用例与用例、用例与参与者之间的上下文关系,并画出用例图;
第四步,进一步逐一分析用例与参与者的详细交互过程,完成一个两列的表格将参与者和待开发软件系统之间从用例开始到用例结束的所有交互步骤都列举出来扩展用例。
其中第一步到第三步是计划阶段,第四步是增量实现阶段。
提取用例得到:
Actor:用户
Use Case:添加测试用例、对测试用例进行编译插桩、裁剪测试用例并加入输入队列、将队列中的文件进行变异、保留有效的变异并加入队列、停止fuzz(记录触发了crash的文件)
用例图
业务领域建模是开发团队用于获取业务领域知识的过程。因为软件工程师往往需要工作在不同的业务领域或者不同项目中,他们需要业务领域知识来开发软件系统。软件工程师往往来自不同的专业背景,这可能会影响他们对业务领域的认知。因此业务领域建模有助于开发团队获取业务领域知识形成统一的业务认知。
业务领域建模的基本步骤
在本课题中,我们并没有具体的类,所以这里选取一些数据结构来进行建模
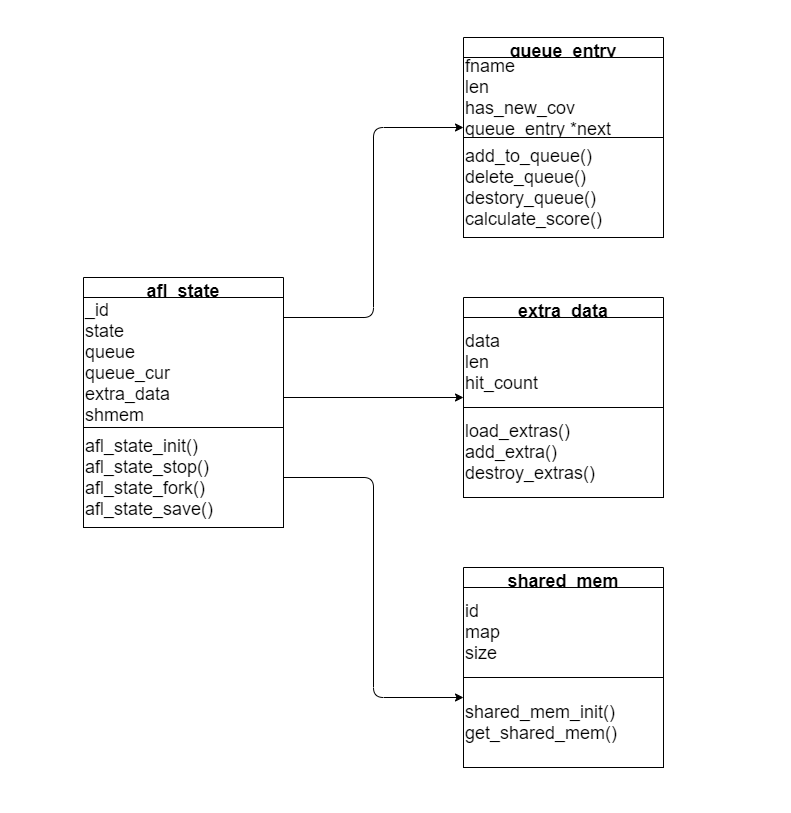
结构体 afl-state:
属性:_id, state,queue,queue_cur, extra_data, shmem
方法:
afl_state_init(): 初始化
afl_state_stop(): 停止fuzz,杀死所有子进程
afl_state_fork(): 分支一个子进程,运行测试
afl_state_save() : 保存输出文件
queue_entry:
属性:fname, len, has_new_cov, queue_entry *next
方法:
extra_data:
属性:data , len, hit_count
方法:
shared_mem:
属性:id,map, size
方法:
shared_mem_init():初始化
get_shared_mem():获取
由此可以画出的UML图如下
五、关系数据建模
根据业务领域建模中的关联关系和关联类,我们可以进一步对项目进行关系数据建模。
afl_state
| 字段 | 类型 | 描述 |
|---|---|---|
| state | int | 测试进行到的阶段状态 |
| queue | *queue_entry | 输入队列 |
| queue_cur | *queue_entry | 当前的执行队列 |
| extra_data | *extra_data | 用户提供的tokens |
| shmem | share_mem | 共享内存 |
queue_entry
| 字段 | 类型 | 描述 |
|---|---|---|
| fname | string | 测试文件的名称 |
| len | int | 队列长度 |
| has_new_cov | bool | 判断是否有新的路径出现 |
| next | queue_entry * | 下一个文件 |
| 字段 | 类型 | 描述 |
| data | string | 用户提供的测试tokens |
| len | int | token长度 |
| hit_count | int | 统计命中次数 |
| 字段 | 类型 | 描述 |
|---|---|---|
| id | int | 共享内存结构的id |
| map | *int | 共享内存指针 |
| size | int | 共享内存大小 |
概念是人对能代表某种事物或发展过程的特点及意义所形成的思维结论。
概念原型是一种虚拟的、理想化的软件产品形式。
经过前面对项目进行的用例建模、业务领域建模和数据建模,我们可以总结出项目的概念原型,其工作流程大致如下:
①从源码编译程序时进行插桩,以记录代码覆盖率(Code Coverage);
②选择一些输入文件,作为初始测试集加入输入队列(queue);
③将队列中的文件按一定的策略进行变异;
④如果经过变异文件更新了覆盖范围,则将其保留添加到队列中;
⑤上述过程会一直循环进行,期间触发了crash的文件会被记录下来。
对一个工程来讲,明确的高效的需求分析是十分重要的,只有明确的需求分析,才能为我们程序的编写提供正确方向,才能对系统建模起到帮助作用。本文是对本人的工程实践课题——基于机器学习的模糊测试框架改进的用例、业务、数据等方面进行分析,完成简单软件项目需求分析到概念原型的基本过程。这将对我之后完成该课题有着巨大的帮助。
基于工程实践的需求分析和概念原型(基于机器学习的模糊测试框架改进)
原文:https://www.cnblogs.com/syli/p/14123450.html