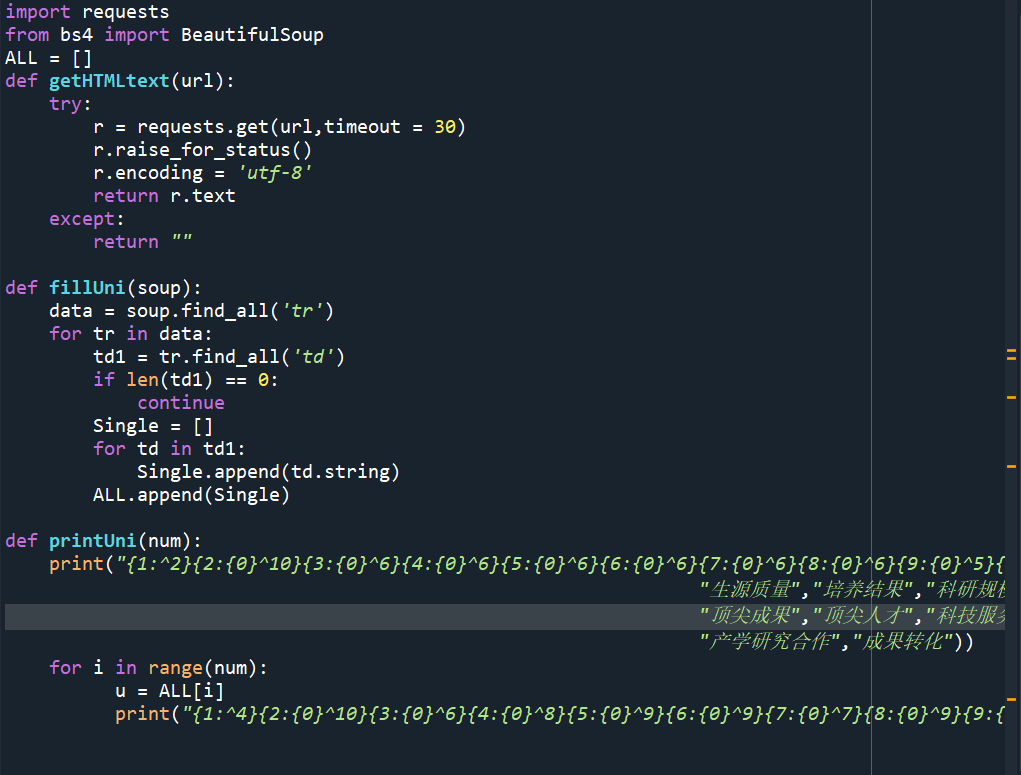
import requests from bs4 import BeautifulSoup ALL = [] def getHTMLtext(url): try: r = requests.get(url,timeout = 30) r.raise_for_status() r.encoding = ‘utf-8‘ return r.text except: return "" def fillUni(soup): data = soup.find_all(‘tr‘) for tr in data: td1 = tr.find_all(‘td‘) if len(td1) == 0: continue Single = [] for td in td1: Single.append(td.string) ALL.append(Single) def printUni(num): print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^6}{5:{0}^6}{6:{0}^6}{7:{0}^6}{8:{0}^6}{9:{0}^5}{10:{0}^6}{11:{0}^6}{12:{0}^6}{13:{0}^6}".format(chr(12288),"排名","学校名称","省市","总分", "生源质量","培养结果","科研规模","科研质量", "顶尖成果","顶尖人才","科技服务", "产学研究合作","成果转化")) for i in range(num): u = ALL[i] print("{1:^4}{2:{0}^10}{3:{0}^6}{4:{0}^8}{5:{0}^9}{6:{0}^9}{7:{0}^7}{8:{0}^9}{9:{0}^7}{10:{0}^9}{11:{0}^8}{12:{0}^9}{13:{0}^9}".format(chr(12288),u[0], u[1],u[2],eval(u[3]), u[4],u[5],u[6],u[7],u[8], u[9],u[10],u[11],u[12])) def main(num): url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html" html = getHTMLtext(url) soup = BeautifulSoup(html,"html.parser") fillUni(soup) printUni(num) import requests from bs4 import BeautifulSoup import csv import os ALL = [] def getHTMLtext(url): try: r = requests.get(url,timeout = 30) r.raise_for_status() r.encoding = ‘utf-8‘ return r.text except: return "" def fillUni(soup): data = soup.find_all(‘tr‘) for tr in data: td1 = tr.find_all(‘td‘) if len(td1) == 0: continue Single = [] for td in td1: Single.append(td.string) ALL.append(Single) def writercsv(save_road,num,title): if os.path.isfile(save_road): with open(save_road,‘a‘,newline=‘‘)as f: csv_write=csv.writer(f,dialect=‘excel‘) for i in range(num): u=ALL[i] csv_write.writerow(u) else: with open(save_road,‘w‘,newline=‘‘)as f: csv_write=csv.writer(f,dialect=‘excel‘) csv_write.writerow(title) for i in range(num): u=ALL[i] csv_write.writerow(u) title=["排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研究合作","成果转化"] save_road="C:\\Users\\86138\\Desktop\\html.csv" def main(num): url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html" html = getHTMLtext(url) soup = BeautifulSoup(html,"html.parser") fillUni(soup) writercsv(save_road,num,title) main(10)
原文:https://www.cnblogs.com/leisure-yee/p/14128515.html