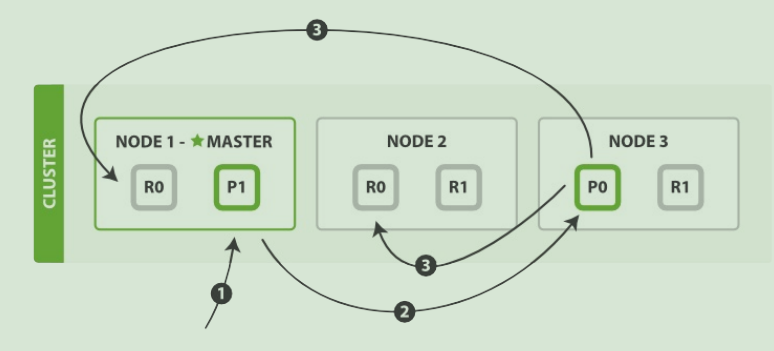
es 写数据过程
1)客户端选择一个 node 发送请求过去,这个 node 就是 coordinating node(协调节点)。
2)coordinating node 对 document 进行路由,将请求转发给对应的 node(有 primary shard)。
3)node 上的 主分片(primary shard )处理请求,然后将数据同步到 复制分片(replica node)。
4)node报告成功到协调节点,协调节点再报告给客户端。
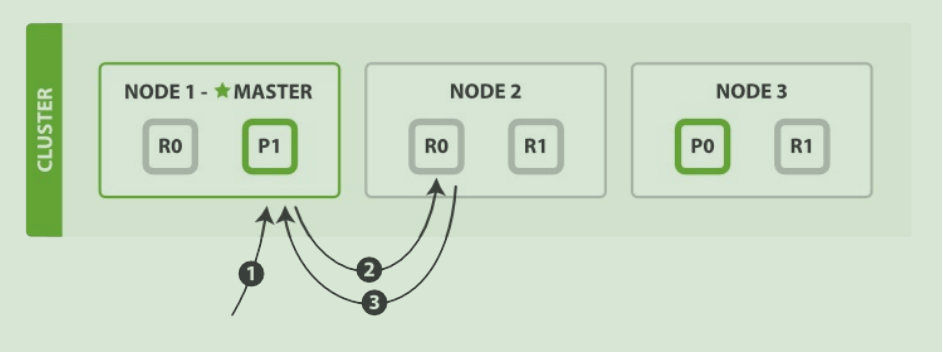
es 读数据过程
可以通过 doc id 来查询,会根据 doc id 进行 hash,判断出来当时把 doc id 分配到了哪个 shard 上面去,从那个 shard 去查询。
1)客户端发送请求到任意一个 node,成为 coordinate node。
2)coordinate node 对 doc id 进行哈希路由,将请求转发到对应的 node,此时会使用 round-robin随机轮询算法,在 primary shard 以及其所有 replica 中随机选择一个,让读请求负载均衡。
3)接收请求的 node 返回 document 给 coordinate node。
4)coordinate node 返回 document 给客户端。
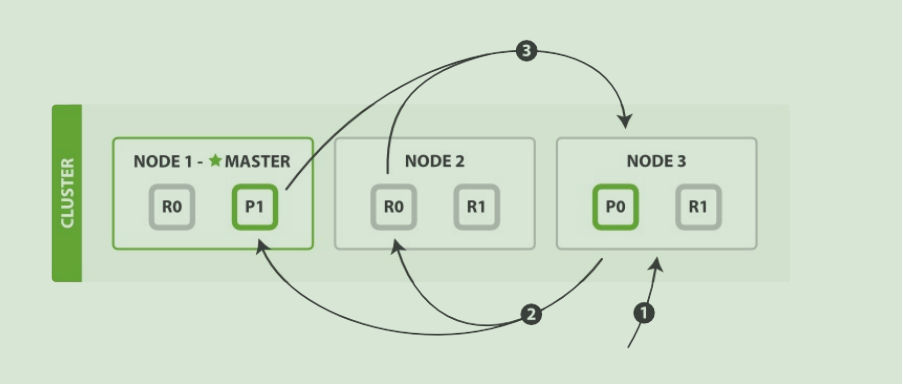
es 搜索数据过程
1)客户端发送请求到一个 coordinate node。
2)协调节点将搜索请求转发到所有的 shard 对应的 primary shard 或 replica shard,都可以。
3)query phase:每个 shard 将自己的搜索结果(其实就是一些 doc id)返回给协调节点,由协调节点进行数据的合并、排序、分页等操作,产出最终结果。
4)fetch phase:接着由协调节点根据 doc id 去各个节点上拉取实际的 document 数据,最终返回给客户端。
查询阶段:
(1)客户端发送一个 search(搜索) 请求给 协调节点,协调节点创建了一个长度为 from+size 的空优先级队列。
(2)协调节点转发这个搜索请求到索引中每个分片的原本或副本。每个分片在本地执行这个查询并且结果将结果到一个大小为 from+size 的有序本地优先队列里去。
(3)每个分片返回document的ID和它优先队列里的所有document的排序值给协调节点 。 协调节点 把这些值合并到自己的优先队列里产生全局排序结果。
取回阶段:
(1)协调节点辨别出哪个document需要取回,并且向相关分片发出 GET 请求。
(2)每个分片加载document并且根据需要丰富(enrich)它们,然后再将document返回协调节点。
(3)一旦所有的document都被取回,协调节点会将结果返回给客户端。
原文:https://www.cnblogs.com/zrzct/p/14135572.html