本章节主要讲述如何利用python和pytorch来读取csv文件;
主要重点在于以下几个:
1.如何读取csv文件;
2.关于切片问题;
3.如何从单值target来构建one-hot target;
4.关于高级索引的问题;
5.各种均值和方差函数的使用;
关于csv文件读取,可以直接采用numpy或者python中的csv文件包进行读取;
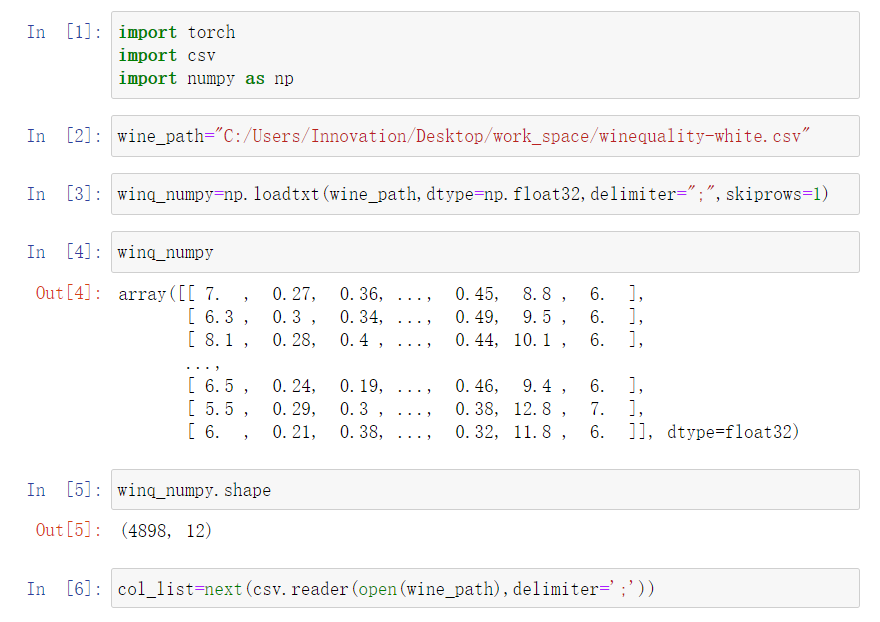
值得注意的是loadtxt函数中的四个参数:
1.指定文件路径;
2.指定文件读取的值类型;
3.指定数据分隔符(也就是每一行每一项的分隔符);
4.指定从第几行开始读取;
切片问题还是老生常谈,对于本例子中给出的数据,最后一列是标签,所以必须要对data和target进行分开提取;
![]()
其中使用.long()函数来进行转换,把标签从浮点转化为整形数据;
对于不少集合中,多以连续数值标签作为类别,例如0-9代表不同的十类,但是对于类别标签,也往往需要转换为one-hot编码;
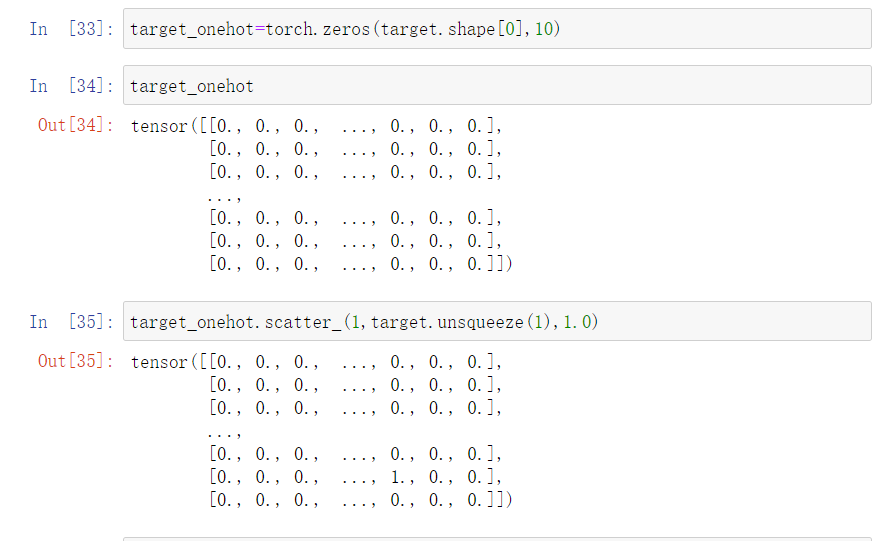
对于target,是tensor(4898,1)形式的张量,由于是十类,所以one-hot标签应该为(4898,10)形式;
而后使用scatter_在target_onehot上直接进行更改;
其中值得注意的是其三个参数:
1.指出修改的是哪一个维度(由于本例子是二维数组,修改的是列,所以应该是1而非0);
2.注意一下unsqueeze()函数;
unsqueeze函数:
旨在进行维度扩充,如下所示:
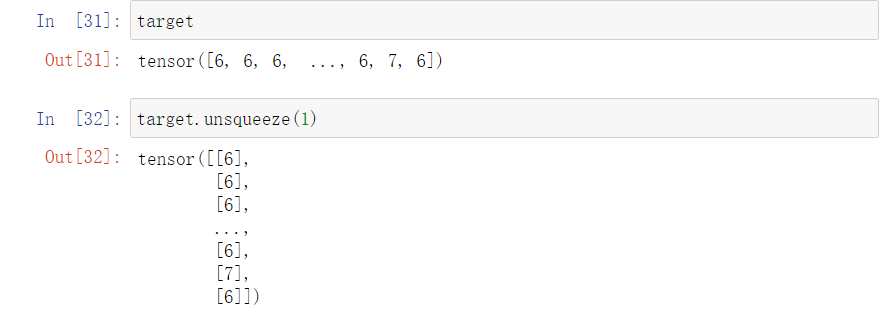
相当于新增维度,直接总1维向量变为2维向量,尽管二维中只有一个元素;
3.指出填充的数字,one-hot直接填充1即可;
所以总而言之,是scatter_目的就是在某一维度,根据对应维度的索引,填入对应的值;
当时有疑惑为什么要用unsqueeze来填充维度,本质是因为one-hot是填充列元素,也是第二维,所以需要坐标指示,而利用unsqueeze可以直接选取第二维中的值作为填充的索引,直接填入即可;
所以,要填充几维,就要扩充到几维,对应的维度内的值即为填充索引;
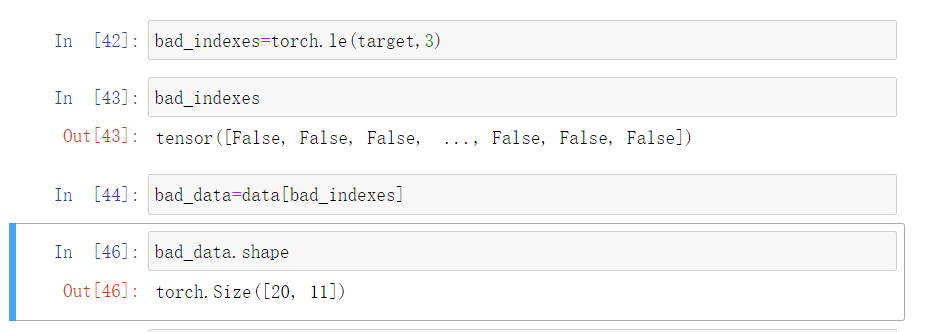
从来没见过的操作;
torch.le返回一个bool列表,对target内指定的值进行判断,符合为true,不符合为false;
高级索引可以直接根据想同维度的bool值来进行选取,如果是true选取对应维度数据,false则跳过,这也是自己没见过的骚操作;
主要采用torch.mean()或者torch.var()来进行,注意使用dim的时候:
dim=0,按照列求均值;
dim=1,按照行求均值;
返回的维度和行或者列维度相同;
原文:https://www.cnblogs.com/songlinxuan/p/14144490.html