这个函数的主要作用是根据时间去看看数据的变化趋势,是下降了还是上升了,最后还要分析趋势的原因,结合业务逻辑去分析
可以根据某个时间周期,计算数据的变化,主要用于时间序列上面
DataFrame.rolling(window,min_periods = None,center = False,win_type = None,on = None,axis = 0,closed = None)
参数说明:
window:int, offset, or BaseIndexer subclass,就是时间周期参数(窗口),数值型,如果是这个BaseIndexer ,比较少见,暂时不管;
min_periods:int, default None,窗口中具有值的最小观察数(否则结果为NA)。对于由偏移量指定的窗口, min_periods将默认为1。否则,min_periods将默认为窗口的大小
center:bool, default False,将标签设置在窗口的中央
win_type:str, default None,提供一个窗口类型。如果为None,则所有点均加权。有关更多信息,请参见下面的注释
on:str, optional,对于DataFrame,是类似于日期时间的列或MultiIndex级别,在该列或MultiIndex级别上计算滚动窗口,而不是DataFrame的索引。由于不使用整数索引来计算滚动窗口,因此忽略提供的整数列并将其从结果中排除
axis:int or str, default 0,行或者列,默认是计算每列
closed:str, default None,使间隔在“右”,“左”,“两个”或“两个都不”端点上关闭。对于基于偏移的窗口,默认为“ right”。对于固定窗口,默认为“两个”。其余情况未针对固定窗口实施,就是开区间或者闭区间
注意:
1.上面说了这么多参数,最终的是window参数,其余的不必细看
2.这个函数一般配合聚合函数(sum,mean等)是使用
3.比如说df[col].rolling(3).sum(),就是计算连续三个值(当前这个+前面两个)的和
import pandas as pd # 导入 pandas import numpy as np index = pd.date_range(‘2019-01-01‘,periods=20) #创建日期序列 data = pd.DataFrame(np.arange(len(index)),index=index,columns=[‘test‘]) #创建简单的pd.DataFrame data #打印data data[‘sum‘] = data.test.rolling(3).sum() #移动3个值,进行求和 data[‘mean‘] = data.test.rolling(3).mean() #移动3个值,进行求平均数 data[‘mean1‘] = data.test.rolling(3,min_periods=2).mean() #移动3个值,最小计数为2,进行求平均数,查看跟上面有何不同
我们看看最后的data
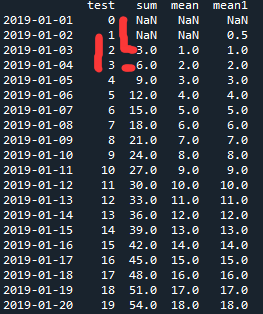
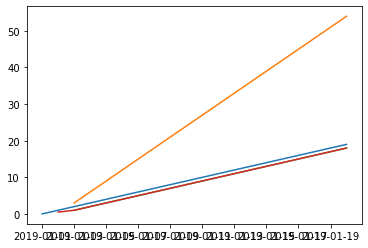
最后可将结果配合plot可视化出来
import matplotlib.pyplot as plt plt.plot(data) #只是简单画图,不做复杂的处理
pandas rolling()根据时间窗口计算滚动(时间序列有关)
原文:https://www.cnblogs.com/cgmcoding/p/14155223.html