特点
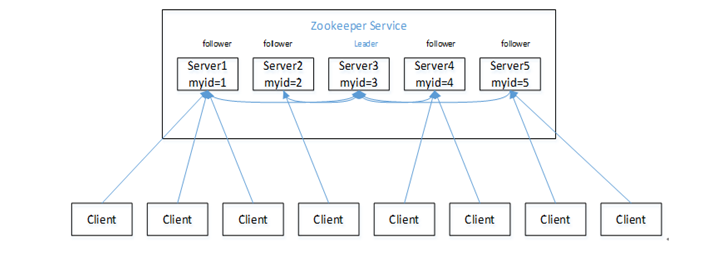
1 Zookeeper:一个领导者,多个跟随者组成的集群
2 集群中只要有半数以上节点存活,Zookeeper就能正常服务
3 全局数据一致性:每个Server保存一份相同的数据副本,CLient无论连接到哪个Server,数据都是一致的。
4 更新请求顺序进行,来自同一个客户端的更新请求按其发送顺序执行
5 数据更新原子性,一次数据要么更新成功,要么失败。
6实时性,在一定范围内,Clinet能读到最新的数据。
help : 显示所有操作命令
ls path:使用ls命令来查看当前znode的子节点
-w 监听子节点得到变化
-s 附加次级信息
create: -s 创建有序
-e 创建临时
get path -w 监听节点内容变化
-s 附加次级信息
set 设置节点的具体值
stat 查看节点的具体值
delete 删除节点
deleteall 递归删除节点
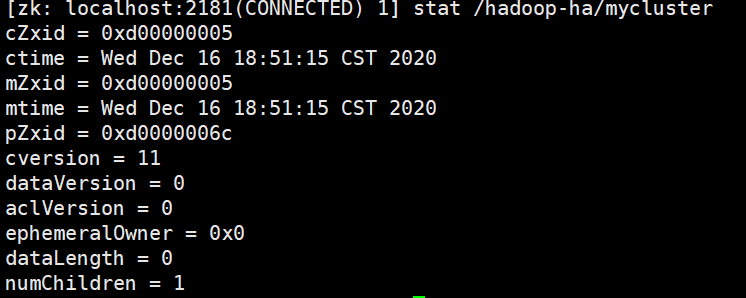
1 cZxid-创建节点的事务 zxid,每次修改Zookeeper状态都会受到一个zxid形式的时间戳,也就是Zookeeper事务ID。事务ID是Zookeeper中所有修改总的次序。每个修改都有唯一的zxid。
2 ctime 被创建的毫秒数
3 mzxid 最后更新的事物zxid
4 mtime 最后修改的毫秒数
5 pZxid 最后更新的子节点zxid
6 cversion 子节点变化号,znode子节点修改次数
7 dataversion 数据变化号
8 aclVersion 访问控制列表的变化号
9 ephemeralOwner 如果是临时节点,这个是znode拥有者的session id。如果不是临时节点则是0
10 dataLength znode的数据长度
11 numChildren znode子节点数量
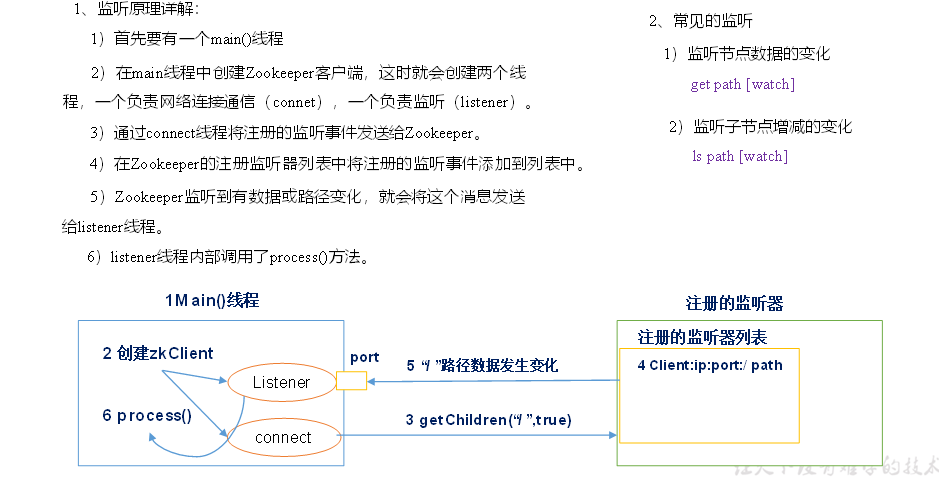
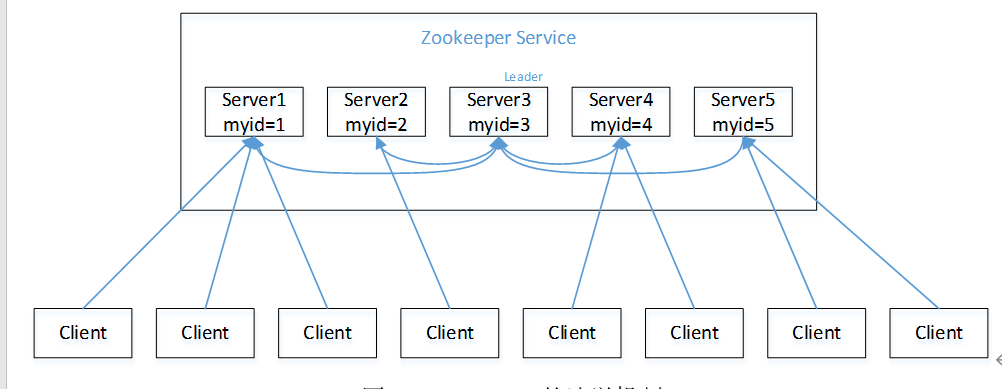
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的ID比自己目前投票推举的(服务器1)大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
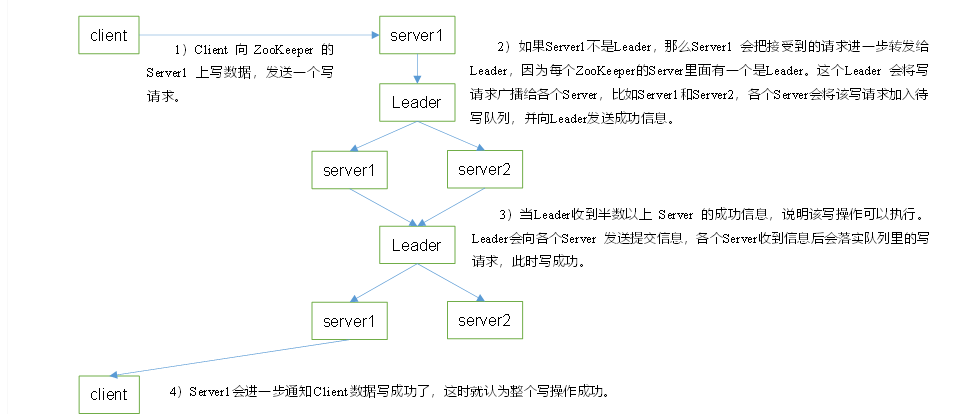
通过多个NameNode消除单点故障
内存中各自保存一份元数据
Edits日志只有Active状态的NameNode节点可以做写操作
所有的NameNode都可以读取Edits
共享的Edits放在一个共享存储中管理
实现了一个zkfailover,常驻在每一个namenode所在的节点,每一个zkfailover负责监控自己所在的NameNode节点,利用zk进行状态标识,当需要进行状态切换时,由zkfailover来负责切换,切换时需要brain spilt现象发生
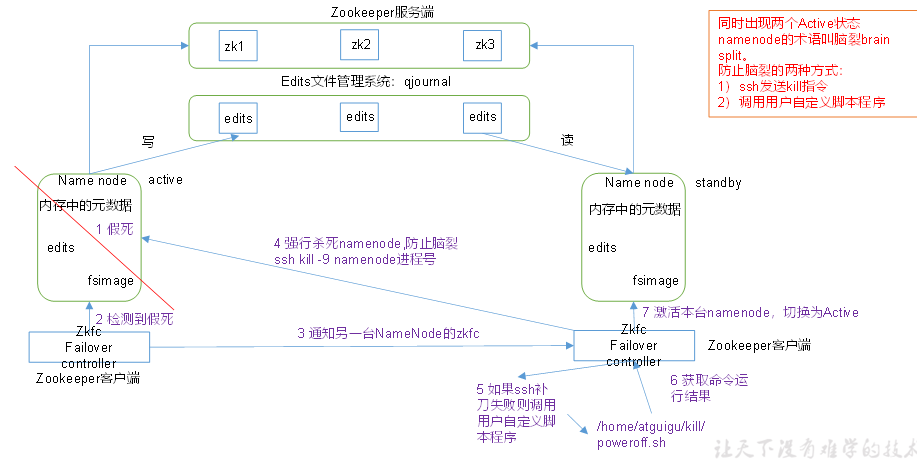
<!--第三步 是通过zookeeper通知另一台NameNode的zkfc-->
1 故障检测
集群中的每个NameNode在Zookeeper中维护了一个会话,如果机器崩溃,Zookeeper中的会话将终止,Zookeeper通知另一个NameNode需要触发故障转移
2 现役NameNode选择
Zookeeper提供了一个简单的机制用于唯一的选择一个节点为active状态。如果目前现役NameNode崩溃,另一个节点可能从Zookeeper获得特殊的排外锁一以表明它应该成为现役NameNode。
ZKFC是自动故障转移中的另一个新组件,是Zookeeper客户端,也监视和管理NameNode的状态。每个运行NameNode的主机也运行了一个ZKFC进程,ZKFC负责:
健康监测 ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,冻结或进入不健康状态,健康监测器标识该节点为非健康的。
ZooKeeper会话管理 当本地NameNode是健康的,ZKFC保持一个在ZooKeeper中打开的会话。如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除。
基于ZooKeeper的选择 如果本地NameNode是健康的,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁。如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active
原文:https://www.cnblogs.com/Stk-HaHa/p/14160835.html