
图片
作者|Thorsten Lorenz
译者|小大非
V8 进行了一次重大架构改造,包括对整个 V8 编译器体系结构以及大部分垃圾收集器的重构,用 TurboFan 取代了 Crankshaft,Orinoco 采用并行机制进行垃圾回收等,本文对这次升级改造进行了简单的介绍。
Node.js 社区中的很多人为最近 V8 的更新感到兴奋,这次更新包括整个 V8 编译器体系结构以及大部分垃圾收集器。TurboFan 取代了 Crankshaft,Orinoco 采用并行机制进行垃圾回收,当然还有一些其它的改进。
第 8 版 Node.js 附带了这个新改进的 V8 引擎,这意味着我们可以放心编写惯用的声明式 JavaScript,而不必担心由于编译器的缺陷引入的性能开销,V8 的开发团队也对这点进行了说明。
因为工作中使用 NodeSource 的缘故,我研究了这些最新的更改,包括查阅 V8 团队发布的博客文章、阅读 V8 源代码以及构建工具来验证特定的性能指标。
我将整理的资料放到了 github 上的 v8-perf 仓库下,以方便大家查看。这些资料也是我本周在 NodeSummit 演讲以及我的系列博客文章的素材基础。
因为这次升级更改较多且比较复杂,我打算在这篇文章中提供一个简单介绍,在本系列的后续博客文章中再对这个主题进行更详细地探讨。
假如你想要立刻了解更多的资料,请直接访问 v8-perf(https://github.com/thlorenz/v8-perf)。
众所周知,以前的 V8 版本遭遇了所谓的优化杀手,似乎已经无法在引擎中修复。V8 团队也很难实现具有良好性能特征的新 JavaScript 语言特性。
其主要原因是 V8 的架构已经变得非常难以更改和扩展。优化编译器 Crankshaft 并没有考虑使用一种有发展前景的语言来实现,编译器管道中层与层之间缺乏隔离也是一个问题。在某些极端情况下,开发人员必须为这四个基础体系结构手工编写汇编代码。
V8 团队意识到了这并不是一个可持续发展的系统,特别是随着 JavaScript 本身的发展速度加快,它也需要添加许多新的语言特性。因此,他们便重新设计了一种新的编译器体系结构。它被划分为三个清晰分离的层:前端层、优化层和后端。
前端主要负责生成由 Ignition 解释器运行的字节码,而优化层则通过 TurboFan 优化编译器改进代码的性能。后端执行较低级的任务,如机器级优化、调度、为受支持的体系结构生成机器代码等。
仅后端分离就比原体系结构代码减少了 29%,尽管新架构可以支持 9 个体系结构。
这个新的 V8 架构的主要目标包括:
在使用新的 V8 时,大多数情况下你只要考虑编写声明式 JavaScript 和使用优良的数据结构和算法就可以了。但是,在应用程序的热代码运行时,你可能希望确保它能在最佳性能下运行。
TurboFan 优化编译器使用高级技术使热代码尽可能快地运行。这些技术包括连接海量节点的方法,创新的调度方式,更多的技术点我会在后续的博文中解释。
TurboFan 依赖于通过内联缓存收集的输入类型信息,相关功能通过 Ignition 解释器运行。使用这些信息,可以生成足以处理各种情况的最优的代码。
编译器需要考虑的函数输入类型变化越少,生成的代码就越小、越快。因此,你可以通过保持函数的单态或最小化的多态来帮助 TurboFan 提升代码运行速度。
与其盲目地追求最佳性能,我建议你首先了解下优化编译器是如何处理代码的,并检查会导致性能下降的代码情况。
为了更方便地实现这一点,我创建了 deoptigate 项目,这个项目的目的是为你的函数提供优化、反优化和处理函数的单态 / 多态 / 变态特性。
首先来看一个简单的示例脚本,我会使用 deoptigate 对其进行配置。
我定义了两个向量函数:add 和 subtract。
function add(v1, v2) {
return {
x: v1.x + v2.x
, y: v1.y + v2.y
, z: v1.z + v2.z
}
}
function subtract(v1, v2) {
return {
x: v1.x - v2.x
, y: v1.y - v2.y
, z: v1.z - v2.z
}
}接下来,我在循环体中使用相同类型 (相同的属性以相同的顺序分配) 的对象执行这些函数。
const ITER = 1E3
let xsum = 0
for (let i = 0; i < ITER; i++) {
for (let j = 0; j < ITER; j++) {
xsum += add({ x: i, y: i, z: i }, { x: 1, y: 1, z: 1 }).x
xsum += subtract({ x: i, y: i, z: i }, { x: 1, y: 1, z: 1 }).x
}
}这样 add 和 subtract 两个函数应该会运行得比较消耗性能了,同时也会得到对应的优化。
现在再次执行它们,将对象传递给 add 函数,此时已经不存在和之前相同类型的对象了,因为它们的属性是按照不同的顺序分配的 ({y: I, x: I, z: I})。
给 subtract 函数传递和之前一样的对象值。
for (let i = 0; i < ITER; i++) {
for (let j = 0; j < ITER; j++) {
xsum += add({ y: i, x: i, z: i }, { x: 1, y: 1, z: 1 }).x
xsum += subtract({ x: i, y: i, z: i }, { x: 1, y: 1, z: 1 }).x
}
}运行此代码并使用 deoptigate 检查它。
node --trace-ic ./vector.js
deoptigate在使用 -trace-ic 标志执行我们的脚本时,V8 会将我们需要的信息写入 isolate-v8.log 日志文件。当 deoptigate 在该文件夹下运行时,它将处理该文件并使用可视化的方式显示所包含的数据。
它是一个 web 应用程序,所以你可以在浏览器中打开它以进行后续操作。
deoptigate 为我们提供了所有文件的摘要,在我们的示例中就是 vector.js。对于每个文件,它显示相关的优化、反优化和内联缓存信息。这里绿色表示没有问题,蓝色是次要问题,红色是潜在的重要问题,应该调查。只需单击文件的名称,就可以展开文件的细节。
图片
左侧提供了文件的源代码,其中的注释指出了潜在的性能问题。在右边,我们可以了解每个问题的更多细节。两个视图的功能是串联的;单击左边的注释会突出显示右边注释的更多细节,反之亦然。
图片
快速浏览一下,我们可以看到,subtract 显示不存在潜在的问题,但是 add 是存在的。单击代码中的红色三角形将突出显示右边的相关反优化信息。请注意,对于使用 Map 错误的原因。
点击任何一个蓝色的电话图标就会显示更多的信息。我们发现函数变成了多态性。正如我们所看到的,这也是由于 Map 不匹配造成的。
在页面顶部检查轻度告警信息可以获得更多有关优化的建议,这次我们还介绍了包括用于 add 函数的时间戳在内的优化。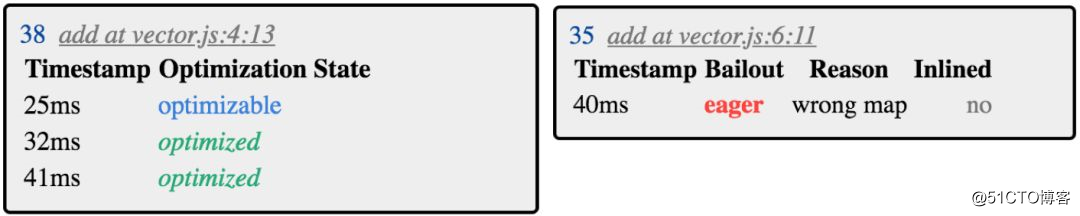
图片
#我们看到 add 在 32ms 后得到了优化。在大约 40ms 时,它被提供了一个输入类型,优化后的代码没有考虑到这个类型——因此出现了错误的映射——并且在这个时候被降级为 Ignition 字节码,同时收集更多的内联缓存信息,并在 41 毫秒后很快又进行了优化。
总之,add 函数最终通过优化的代码执行,但是该代码需要处理两种类型的输入 (不同的映射),它更庞大了但不像以前那样最优。
相反,subtract 函数只优化了一次,我们可以通过点击函数签名中的绿色三角形进行验证。
有些人可能想知道为什么 V8 认为通过{x, y, z}赋值创建的对象与通过{y, x, z}赋值创建的对象不同,既然它们具有完全相同的属性,只是以不同的顺序赋值而已。
这要归因于在初始化 JavaScript 对象时创建映射的方式,这也会是我另一篇文章将要介绍的主题 (我将在 NodeSummit 会议上更详细地解释这一点)。希望后续继续关注我的系列博客。
原文链接
https://nodesource.com/blog/why-the-new-v8-is-so-damn-fast
活动推荐
ArchSummit 全球架构师峰会将于 12 月 7-8 日在北京国际会议中心举办,会议专题聚集了微服务金融架构、微服务架构、数据基础平台建设、短视频架构、区块链、信息隐私安全等话题。邀请了阿里巴巴、Netflix、百度、LinkedIn 等公司的技术专家来分享。
大会 7 折报名中,立减 2040 元,有任何问题欢迎咨询票务经理 Lachel- 灰灰,电话 / 微信:17326843116。
原文:https://blog.51cto.com/15057848/2568432