用户数据:
用户id 用户名,年龄,性别,朋友
u001,senge,18,male,angelababy
u002,,58,male,ruhua
...
订单数据:
订单,用户id
order001,u002
order001,u003
order001,u001
order001,u004
order002,u005
...
设计思路:
1.将用户(user)数据缓存到maptask的机器中(本地路径)。
2.在map方法之前读取用户(user)数据,存储到Map集合中 格式: Map<uid, User>
3.map方法只读orders数据,根据orders数据中uid获取Map中的User数据,进行拼接
代码:
package com.xjk.map_join;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.xjk.yarn.DriverClass;
import com.xjk.yarn.WordCountMapper;
import com.xjk.yarn.WordCountReduce;
/*
*map端 join
*1.将user数据缓存到maptask的机器中(当前类路径下)。
*2.在map方法之前读取user数据,存储在Map集合中<uid,User>
*3.map方法只读orders数据,根据orders数据中uid获取Map中
*User进行拼接
*
* */
public class Join {
static class JoinMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
// 创建空Map
Map<String, User> map = new HashMap<>();
// 读取缓存数据
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
// 读取本地,缓存 user.txt文件
BufferedReader br = new BufferedReader(new FileReader("e:/data/user.txt"));
String line = null;
while ((line = br.readLine())!=null) {
// 构建user对象
String[] split = line.split(",");
User user = new User();
user.set(split[0], split[1], Integer.parseInt(split[2]), split[3]);
// map uid为key, user对象为value
map.put(user.getUid(), user);
}
}
Text k = new Text();
// 读取orders数据
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(",");
// 获取订单用户id
String uid = split[1];
// 从map中获取,该uid的用户信息
User user = map.get(uid);
// 订单号与用户信息拼接
String res = split[0] + "," + user.toString();
k.set(res);
context.write(k, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
// 设置用户名 root权限
System.setProperty("HADOOP_USER_NAME", "root");
// 生成默认配置
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 连接远程hdfs
conf.set("fs.defaultFS", "hdfs://linux01:9000");
// 设置程序运行在yarn ,默认local
conf.set("mapreduce.framework.name", "yarn");
// 设置resource manager主机
conf.set("yarn.resourcemanager.hostname","linux01");
// 允许 mapreduce程序跨平台运行
conf.set("mapreduce.app-submission.cross-platform","true");
// 设置本地程序的jar路径
job.setJar("E:\\data\\join.jar");
// 设置缓存分布式路径 hdfs根目录的user.txt
job.addCacheFile(new Path("hdfs://linux01:9000/user.txt").toUri());
job.setMapperClass(JoinMapper.class);
// map做最终输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//输入数据 设置默认处理文件路径,默认处理文本数据long line
FileInputFormat.setInputPaths(job, new Path("hdfs://linux01:9000/data/join/input/"));
//输出数据路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://linux01:9000/data/join/output/"));
// 设置reduce数量
job.setNumReduceTasks(2);
// 将任务提交,默认在本地运行true将job执行消息打印在控制台上。
job.waitForCompletion(true);
// 输入数据路经中只有order数据
}
}
前置配置:
# 1.将程序打包jar包到 E:\\data\\join.jar下
# 2.启动linux机器
start-all.sh
# 3.将order.txt 和user.txt添加hdfs中
hdfs dfs -mkdir -p /data/join/input
hdfs dfs -put ./order.txt /data/join/input
hdfs dfs -put ./user.txt /
# 运行程序
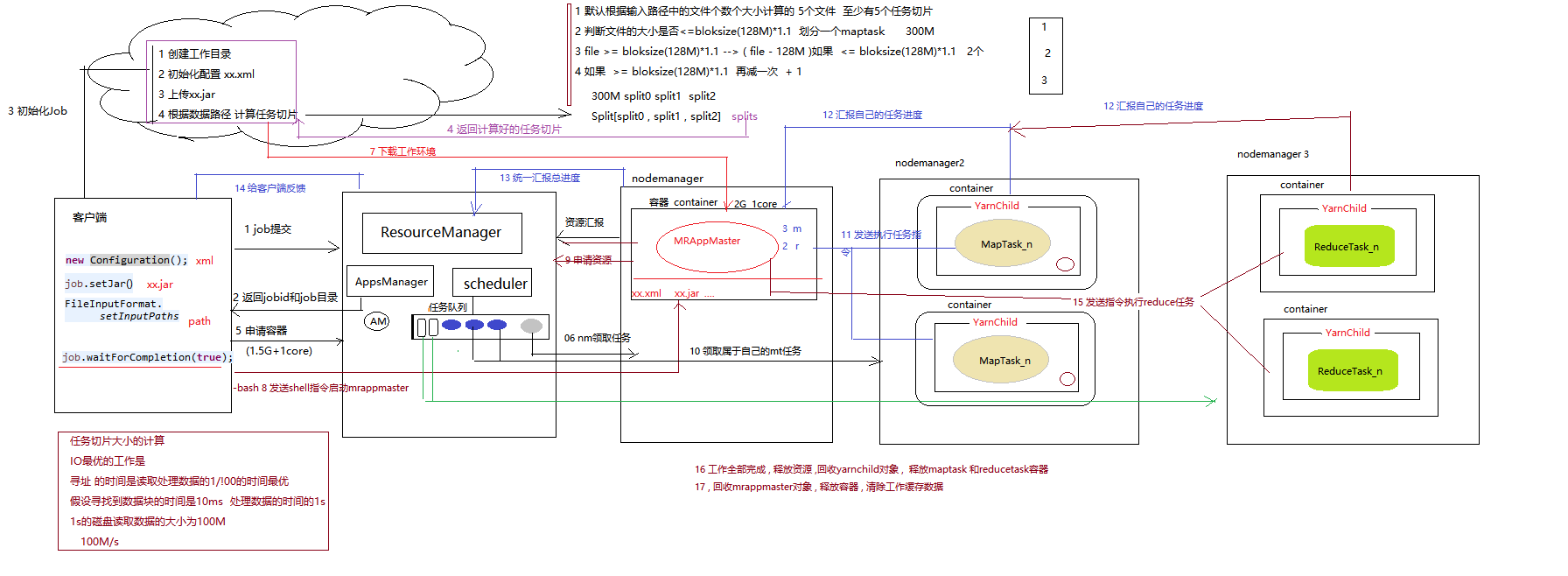
mr在yarn工作流程:
步骤1:客户端
new Configurationn();// 配置信息
job.setJar() // jar包
FileInputFormat.setInputPaths // 工作路径
通过job.waitForCompletion(true)将job任务提交到 ResourceManager
步骤2:ResourceManager:
到ResourceManager节点上会返回一个job的id和工作目录 给客户端。
而 ResourceManager 有两个重要的组件:ApplicationManager(管理任务程序) 和 scheduler(调度器,分配资源)
步骤3:
客户端对job进行初始化(它作用是:1.创建工作目录。2初始化配置xml文件。3.上传jar包。)。
步骤4:
客户端根据数据路经计算任务切片。
计算任务切片方式:
1.根据输入路径中文件个数和大小计算
2.判断文件大小是否小于等于blocksize(128M),划分一个maptask。
步骤5:
客户端向 ResourceManager 的scheduler 申请容器, ResourceManager通过 ApplicationManager申请一个任务程序(apptask),而scheduler 会有一个任务队列,并把apptask放进任务队列里。
步骤6:
而nodemanager定期会向ResourceManager汇报同时会领取自己的任务。在领取自己任务之后,会创建一个容器(container 比如2G 1core)。
步骤7:
nodemanager 从初始化job客户端 下载所需工作环境(*.xml,*.jar)。并初始化maprreduceapptask
步骤8:
客户端 发送shell命令启动 并初始化maprreduceapptask
步骤9:
此时 nodemanager 里的 maprreduceapptask 知道有几个maptask和reducetask。 而nodemanager会向 ResourceManager 申请资源。
步骤10:
而 ResourceManager 任务队列会创建 maptask 和 reducetask任务(假如有2个maptask,2个reducetask)。然后各个 nodemanager 领取自己任务 并创建容器,通过 YarnChild 管理自己maptask。
步骤11:
通过 maprreduceapptask 发送执行任务指令 让 maptask执行
步骤12:
各个执行的maptask 会汇报自己执行maptask 任务进度给 maprreduceapptask
步骤13:
maprreduceapptask 统一 向 ResourceManager 汇报总进度
步骤14:
maprreduceapptask 给客户端进行反馈
步骤15:
maptask运行一阵后产生数据,maprreduceapptask 发送指令 执行 reducetask。而reducetask 也一样会定期向 maprreduceapptask汇报
步骤16:
当工作全部完成, 回收Yarnchild对象,释放maptask和reducetask容器。
步骤17:
回收 maprreduceapptask 对象,释放 初始化容器,清除工作的缓存(*.jar等等)
当某个数据hashcode特别多,大多数任务压在一台机器上,导致当前机器压力特别大,而其他机器资源占用少。通过对key进行random均衡分配任务给各个机器上。避免数据倾斜。
第一步处理:
package com.xjk.map.skew;
import java.io.IOException;
import java.util.Random;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Skew1 {
static class Skew1Mapper extends Mapper<LongWritable, Text, Text, IntWritable>{
int numReduceTasks = 1;
@Override
protected void setup(
Mapper<LongWritable, org.apache.hadoop.io.Text, org.apache.hadoop.io.Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// 在setup方法中获取job中reducer的个数。
numReduceTasks = context.getNumReduceTasks();
}
Text k = new Text();
Random r = new Random();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split(" ");
for (String word : split) {
// 通过reducer个数获取随机数
int nextInt = r.nextInt(numReduceTasks);
// 拼接key的值。这样对key进行hashcode减少数据倾斜
String res = word + "-" + nextInt;
k.set(res);
context.write(k, v);
}
}
}
static class Skew1Reducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
// 遍历values
for (IntWritable intWritable : values) {
count ++;
}
context.write(key, new IntWritable(count));// a-1 10,a-2 15
}
}
public static void main(String[] args) throws Exception {
// 生成默认配置
Configuration configuration = new Configuration();
//configuration.set("hadoop.tmp.dir", "E:/hdfs_tmp_cache");
Job job = Job.getInstance(configuration);
// map和reduce的类
job.setMapperClass(Skew1Mapper.class);
job.setReducerClass(Skew1Reducer.class);
// map输出k-v类型,
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//reduce输出k-v类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置reduce数量
job.setNumReduceTasks(3);
//输入数据 设置默认处理文件路径,默认处理文本数据long line
FileInputFormat.setInputPaths(job, new Path("D:\\data\\skew\\input"));
//输出数据路径
FileOutputFormat.setOutputPath(job, new Path("D:\\data\\skew\\output2"));
// 将任务提交,默认在本地运行true将job执行消息打印在控制台上。
job.waitForCompletion(true);
}
}
得到数据
a-0 596
b-2 106
c-1 297
...
第二步骤处理:
package com.xjk.map.skew;
import java.io.IOException;
import java.util.Random;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Skew2 {
static class Skew1Mapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split("\t");
String word = split[0].split("-")[0];
int count = Integer.parseInt(split[1]);
k.set(word);
v.set(count);
context.write(k, v);
}
}
static class Skew1Reducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
// 遍历values
for (IntWritable intWritable : values) {
count += intWritable.get();
}
context.write(key, new IntWritable(count));// a-1 10,a-2 15
}
}
public static void main(String[] args) throws Exception {
// 生成默认配置
Configuration configuration = new Configuration();
//configuration.set("hadoop.tmp.dir", "E:/hdfs_tmp_cache");
Job job = Job.getInstance(configuration);
// map和reduce的类
job.setMapperClass(Skew1Mapper.class);
job.setReducerClass(Skew1Reducer.class);
// map输出k-v类型,
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//reduce输出k-v类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置reduce数量
job.setNumReduceTasks(3);
//输入数据 设置默认处理文件路径,默认处理文本数据long line
FileInputFormat.setInputPaths(job, new Path("D:\\data\\skew\\output2"));
//输出数据路径
FileOutputFormat.setOutputPath(job, new Path("D:\\data\\skew\\output3"));
// 将任务提交,默认在本地运行true将job执行消息打印在控制台上。
job.waitForCompletion(true);
}
}
得到数据
a 1770
d 240
g 60
...
有时我们想将输出结果自定义输出到不同路径上,我们可以通过执行reduce中自定义方式进行多路径输出
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
// 1.在reduce处理setup方法中,生成多路径对象
MultipleOutputs<Text, IntWritable> outputs = null;
@Override
protected void setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
outputs = new MultipleOutputs<>(context);
}
// 2. reduce中定义输出路径
if (word.startsWith("h")) {
// key, value ,输出路径
outputs.write(key, new IntWritable(count), "d:/data/wc/out1/");// 最后带斜杠会生成数据文件会在out1文件夹里,不带斜杠会生成out1的文件
}else {
outputs.write(key, new IntWritable(count), "d:/data/wc/out2/");
}
// 3. 最后关闭输出对象
/*关闭输出对象,释放输出流*/
@Override
protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
outputs.close();
}
// 4.
FileOutputFormat.setOutputPath(job, new Path("d:/data/wc/output"));
// 此时执行结果会输出到自定义路径。如果想在最终定义的输出路径不产生文件可执行
import org.apache.hadoop.mapreduce.lib.output.LazyOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
LazyOutputFormat.setOutputFormatClass(job, TextOutputFormat.class);
SequenceFileInputFormat,SequenceFileOutputFormat
SequenceFile:是hadoop设计的一种序列化文件格式,SQE开头,文件中是连续的key-value序列化数据。
当MAPREDUCE处理的数据是SequenceFile的时候,需要知道处理文件key,value格式,运算框架会读取一堆key-value处理。
其实相当于每次读一对key-value.没有换行概念。
// 输出端:
// 默认输出TextFileOutput
FileOutputFormat.setOutputPath(job, new Path("d:/data/Friends/output/"));
// 用来取代默认text文件格式输出,输出Sequence格式
job.setOutputFormatClass(SequenceFileOutputFormat.class);
// 输入端:
保证输入的key和value类型与输出端一致, 在map方法读取一堆key-value
static class SameF2Mapper extends Mapper<Text, Text, Text, Text>{
Text k = new Text();
Text v = new Text();
protected void map(Text key, Text value, org.apache.hadoop.mapreduce.Mapper<LongWritable,Text,Text,Text>.Context context) throws java.io.IOException ,InterruptedException {
context.write(key, value);
}
//设置读取sequence文件
job.setInputFormatClass(SequenceFileInputFormat.class);
# 指定输出压缩文件
<property>
<name>mapreduce.map.output.compress</name>
<value>false</value>
</property>
# 默认编码方式
<property>
<name>mapreduce.map.output.compress.cpdec</name>
<value>org.apache.hadoop.io.compress.Defai;tCpdec</value>
</property>
统计每个人评分最高的5条记录
实现思路:
1.map端输出key=MovieBean value=NullWritable
2.进行排序:uid相同,按照分数降序排序,按照uid的hashcode分区,这样相同uid被分到相同区内。
3.归并排序
实现步骤:
1.给MovieBean指定排序规则。
2.重写hashPartition方法,按照uid进行分区。
3.重写GroupPartition方法,按照key的uid进行分组。
代码实现:
package com.xjk.high_topN;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/*
* MovieBean 要做为map端key输出
* 1.序列化
* 2.自定义排序:用户的uid相同按照分数降序排序
* */
public class MovieBean implements WritableComparable<MovieBean> {
private String movie;
private double rate;
private String timeStamp;
private String uid;
public String getMovie() {
return movie;
}
public void setMovie(String movie) {
this.movie = movie;
}
public double getRate() {
return rate;
}
public void setRate(double rate) {
this.rate = rate;
}
public String getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(String timeStamp) {
this.timeStamp = timeStamp;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
@Override
public void readFields(DataInput in) throws IOException {
this.movie = in.readUTF();
this.rate = in.readDouble();
this.timeStamp = in.readUTF();
this.uid = in.readUTF();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(movie);
out.writeDouble(rate);
out.writeUTF(timeStamp);
out.writeUTF(uid);
}
// uid不同按照uid排序
// 用户的uid相同按照分数降序排序
@Override
public int compareTo(MovieBean o) {
return this.uid.compareTo(o.getUid()) == 0 ?
Double.compare(o.getRate(), this.rate):this.uid.compareTo(o.getUid()) ;
}
@Override
public String toString() {
return "MovieBean [movie=" + movie + ", rate=" + rate + ", timeStamp=" + timeStamp + ", uid=" + uid + "]";
}
}
package com.xjk.high_topN;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
// HashPartitioner为默认分区方式,继承HashPartitioner重写getPartition自定义分区
public class MyPartitioner extends HashPartitioner<MovieBean, NullWritable> {
@Override
public int getPartition(MovieBean key, NullWritable value, int numReduceTasks) {
return (key.getUid().hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
package com.xjk.high_topN;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
// 继承WritableComparator 重写compare方法 自定义分组
// 将相同uid分配到一个迭代器中。本质是比较uid
public class MyGroupingPartition extends WritableComparator {
// 如果不写构造方法会调用父类空参构造方法。
public MyGroupingPartition() {
// 调用父类构造方法,用于实例Movie对象
// 并且反射实例对象
super(MovieBean.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
MovieBean m1 = (MovieBean) a;
MovieBean m2 = (MovieBean) b;
return m1.getUid().compareTo(m2.getUid());
}
}
package com.xjk.high_topN;
import java.io.IOException;
import com.google.gson.Gson;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.google.gson.Gson;
public class TopN {
static class TopNMapper extends Mapper<LongWritable, Text, MovieBean, NullWritable>{
Gson gs = new Gson();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, MovieBean, NullWritable>.Context context)
throws IOException, InterruptedException {
try {
String line = value.toString();
MovieBean mb = gs.fromJson(line, MovieBean.class);
// 取出自定分区,按照uid
// 写出数据:
context.write(mb, NullWritable.get());
} catch (Exception e) {
e.printStackTrace();
}
}
}
static class TopNReducer extends Reducer<MovieBean, NullWritable, MovieBean, NullWritable>{
@Override
protected void reduce(MovieBean key, Iterable<NullWritable> values,
Reducer<MovieBean, NullWritable, MovieBean, NullWritable>.Context context)
throws IOException, InterruptedException {
int count = 0;
for (NullWritable nullWritable : values) {// key是变化的
count ++;
context.write(key, nullWritable);
if (count==5) {
return ;
}
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("hadoop.tmp.dir", "E:/hdfs_tmp_cache");
Job job = Job.getInstance(conf);
job.setMapperClass(TopNMapper.class);
job.setReducerClass(TopNReducer.class);
job.setMapOutputKeyClass(MovieBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(MovieBean.class);
job.setOutputValueClass(NullWritable.class);
// 设置自定义分区
job.setPartitionerClass(MyPartitioner.class);
// 设置自定义的分组规则
job.setGroupingComparatorClass(MyGroupingPartition.class);
FileInputFormat.setInputPaths(job, new Path("D:\\data\\sourcedata\\simple\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\data\\sourcedata\\simple\\output"));
boolean b = job.waitForCompletion(true);
// 程序退出 0正常退出 ,非0异常退出
System.exit(b?0:-1);
}
}
继承Reducer进行局部聚合操作,减少在reduce的迭代次数。
package combiner;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> iters,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable intWritable : iters) {
count ++;
}
context.write(key, new IntWritable(count));
}
}
// 设置combiner局部聚合
job.setCombinerClass(MyCombiner.class);
比如我们在map端读取行数据进行json转换,有可能转换失败。我们可以用全局计数器
import org.apache.hadoop.mapreduce.Counter;
...
Counter counter = null;
protected void map(...){
context.getCounter("mycounter", "ERROR");
try {
...
} catch (Exception e) {
// 计数器 记录脏数据格式
counter.increment(1);
}
}
// 终端打印:
mycounter
ERROR=5 //脏数据5个
当你的小文件比较多时候后,可以设置小文件合并成逻辑切片的大小,合并文件大小以byte为单位
1.设置小文件合并切片大小
conf,setLong("mapreduce.input.fileInputformat.split.minsize", 1024*2) //设置2M
2.设置输入类
job.setInputFormatClass(CombineTextInputFormat.class)
以统计单词为例
// 在 main 中
import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat;
public class DriverClass {
public static void main(String[] args) throws Exception {
...
// 设置map处理数据的最小大小, 当大小不够进行合并
conf,setLong("mapreduce.input.fileInputformat.split.minsize", 1024*32) // 此时设置32M,不是固定的。根据数据大小自行测试。
...
// 使用 CombineTextInputFormat重新任务划分
job.setInputFormatClass(CombineTextInputFormatrmat.class)
// 将任务提交,默认在本地运行true将job执行消息打印在控制台上。
job.waitForCompletion(true);
}
}
// 注意此时用上述方法在map端是无法获取文件名的。否则会报转换异常
hadoop管理命令和安全模式
// 各个节点配置信息
[root@linux01 bin]# ./hdfs dfsadmin -report
// 安全模式(可以查数据,但无法写入)
[root@linux01 bin]# ./hdfs dfsadmin -safemode enter // 进入安全模式
[root@linux01 bin]# ./hdfs dfsadmin -safemode leave // 退出安全模式
原文:https://www.cnblogs.com/xujunkai/p/14176280.html