来源:Will Koehrsen
代码整理及注释翻译:黄海广
代码和数据下载地址:
该选择器基于Python编写,有五种方法来标识要删除的特征:
在这个Jupyter文件中, 我们将使用 FeatureSelector 类来选择数据集中要删除的特征,这个类提供五种方法来查找要删除的功能:
from feature_selector import FeatureSelector
import pandas as pd该数据集被用作Kaggle上房屋信用违约风险竞赛的(https://www.kaggle.com/c/home-credit-default-risk) 一部分(文末提供下载)。它旨在用于有监督的机器学习分类任务,其目的是预测客户是否会拖欠贷款。您可以在此处下载整个数据集,我们将处理10,000行的一小部分样本。
特征选择器旨在用于机器学习任务,但可以应用于任何数据集。基于特征重要性的方法需要使用机器学习的监督学习问题。
train = pd.read_csv(‘data/credit_example.csv‘)
train_labels = train[‘TARGET‘]
train.head()
5 rows × 122 columns
数据集中有几个分类列。FeatureSelector处理这些特征重要性的时候使用独热编码。
train = train.drop(columns = [‘TARGET‘])在FeatureSelector具有用于标识列,以除去五种特征 :
FeatureSelector 仅需要一个在行中具有观察值而在列中具有特征的数据集(标准结构化数据)。我们正在处理机器学习的分类问题,因此我们也需要训练的标签。
fs = FeatureSelector(data = train, labels = train_labels)第一种特征选择方法很简单:找到丢失分数大于指定阈值的任何列。在此示例中,我们将使用阈值0.6,这对应于查找缺失值超过60%的特征。(此方法不会首先对特征进行一次独热编码)。
fs.identify_missing(missing_threshold=0.6)17 features with greater than 0.60 missing values.
可以通过 FeatureSelector 对象的ops词典访问已确定要删除的特征。
missing_features = fs.ops[‘missing‘]
missing_features[:10][‘OWN_CAR_AGE‘,
‘YEARS_BUILD_AVG‘,
‘COMMONAREA_AVG‘,
‘FLOORSMIN_AVG‘,
‘LIVINGAPARTMENTS_AVG‘,
‘NONLIVINGAPARTMENTS_AVG‘,
‘YEARS_BUILD_MODE‘,
‘COMMONAREA_MODE‘,
‘FLOORSMIN_MODE‘,
‘LIVINGAPARTMENTS_MODE‘]
我们还可以绘制数据集中所有列的缺失列分数的直方图。
fs.plot_missing()
有关缺失分数的详细信息,我们可以访问missing_stats属性,这是所有特征缺失分数的DataFrame。
fs.missing_stats.head(10)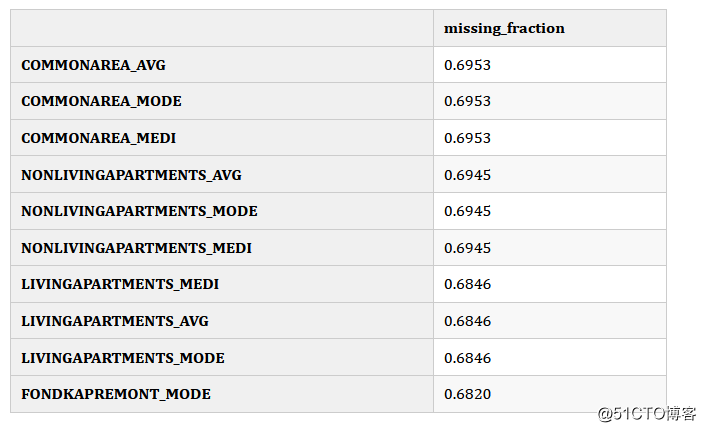
下一个方法很简单:找到只有一个唯一值的所有特征。(这不会对特征进行独热编码)。
fs.identify_single_unique()4 features with a single unique value.
single_unique = fs.ops[‘single_unique‘]
single_unique[‘FLAG_MOBIL‘, ‘FLAG_DOCUMENT_10‘, ‘FLAG_DOCUMENT_12‘, ‘FLAG_DOCUMENT_17‘]
我们可以绘制数据集中每个特征中唯一值数量的直方图。
fs.plot_unique()
最后,我们可以访问一个DataFrame,其中包含每个特征的唯一值数量。
fs.unique_stats.sample(5)
该方法基于皮尔森相关系数找到共线特征对。对于高于指定阈值(就绝对值而言)的每一对,它标识要删除的变量之一。我们需要传递一个 correlation_threshold。
此方法基于在:https://chrisalbon.com/machine_learning/feature_selection/drop_highly_correlated_features/ 中找到的代码。
对于每一对,将要删除的特征是在DataFrame中列排序方面排在最后的特征。(除非one_hot = True,否则此方法不会预先对数据进行一次独热编码。因此,仅在数字列之间计算相关性)
fs.identify_collinear(correlation_threshold=0.975)24 features with a correlation magnitude greater than 0.97.
correlated_features = fs.ops[‘collinear‘]
correlated_features[:5][‘AMT_GOODS_PRICE‘,
‘FLAG_EMP_PHONE‘,
‘YEARS_BUILD_MODE‘,
‘COMMONAREA_MODE‘,
‘ELEVATORS_MODE‘]
我们可以查看阈值以上相关性的热图。将要删除的特征位于x轴上。
fs.plot_collinear()
要绘制数据中的所有相关性,我们可以将 plot_all = True 传递给 plot_collinear函数。
fs.plot_collinear(plot_all=True)
fs.identify_collinear(correlation_threshold=0.98)
fs.plot_collinear()21 features with a correlation magnitude greater than 0.98.

要查看阈值以上的相关细节,我们访问record_collinear 属性,它是一个DataFrame。 drop_feature 将被删除,并且对于每个将被删除的特征,它与 corr_feature可能存在多个相关性,而这些相关性都高于correlation_threshold。
fs.record_collinear.head()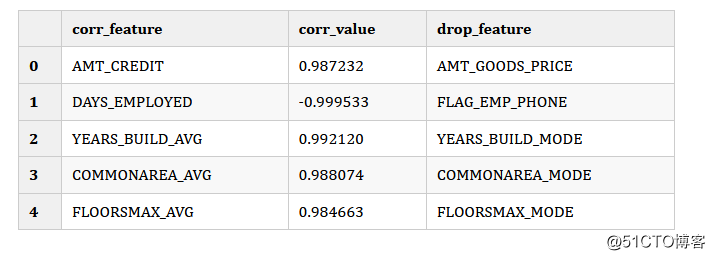
此方法依赖于机器学习模型来识别要删除的特征。因此,它是有标签的监督学习问题。该方法通过使用LightGBM库中实现的梯度增强机找到特征重要性。
为了减少所计算的特征重要性的差异,默认情况下对模型进行了10次训练。默认情况下,还使用验证集(训练数据的15%)通过提前停止训练模型,以识别要训练的最优估计量。可以将以下参数传递给identify_zero_importance 方法:
注意:与其他方法相比,模型的特征重要性是不确定的(具有少许随机性)。每次运行此方法时,其结果都可能更改。
fs.identify_zero_importance(task = ‘classification‘, eval_metric = ‘auc‘,
n_iterations = 10, early_stopping = True)
Training Gradient Boosting Model
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[57] valid_0‘s auc: 0.760957 valid_0‘s binary_logloss: 0.250579
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[29] valid_0‘s auc: 0.681283 valid_0‘s binary_logloss: 0.266277
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[50] valid_0‘s auc: 0.73881 valid_0‘s binary_logloss: 0.257822
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[34] valid_0‘s auc: 0.720575 valid_0‘s binary_logloss: 0.262094
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[48] valid_0‘s auc: 0.769376 valid_0‘s binary_logloss: 0.247709
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[35] valid_0‘s auc: 0.713877 valid_0‘s binary_logloss: 0.262254
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[76] valid_0‘s auc: 0.753081 valid_0‘s binary_logloss: 0.251867
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[70] valid_0‘s auc: 0.722385 valid_0‘s binary_logloss: 0.259535
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[45] valid_0‘s auc: 0.752703 valid_0‘s binary_logloss: 0.252175
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[49] valid_0‘s auc: 0.757385 valid_0‘s binary_logloss: 0.250356
81 features with zero importance after one-hot encoding.
运行梯度提升模型需要对特征进行独热编码。这些特征保存在 FeatureSelector的 one_hot_features 属性中。原始特征保存在base_features中。
one_hot_features = fs.one_hot_features
base_features = fs.base_features
print(‘There are %d original features‘ % len(base_features))
print(‘There are %d one-hot features‘ % len(one_hot_features))There are 121 original features
There are 134 one-hot features
FeatureSelector 的 data 属性保存原始DataFrame。独热编码后, data_all属性将保留原始数据以及独热编码特征。
fs.data_all.head(10)
10 rows × 255 columns
我们可以使用多种方法来检查特征重要性的结果。首先,我们可以访问具有零重要性的特征列表。
zero_importance_features = fs.ops[‘zero_importance‘]
zero_importance_features[10:15][‘ORGANIZATION_TYPE_Transport: type 1‘,
‘ORGANIZATION_TYPE_Security‘,
‘FLAG_DOCUMENT_15‘,
‘FLAG_DOCUMENT_17‘,
‘ORGANIZATION_TYPE_Religion‘]
使用 plot_feature_importances 的特征重要性画图将向我们显示 plot_n 最重要的特征(按归一化比例将特征加总为1)。它还向我们显示了累积特征重要性与特征数量之间的关系。
当我们绘制特征重要性时,我们可以传递一个阈值,该阈值标识达到指定的累积特征重要性所需的特征数量。例如,threshold = 0.99将告诉我们占总重要性的99%所需的特征数量。
fs.plot_feature_importances(threshold = 0.99, plot_n = 12)

111 features required for 0.99 of cumulative importance
在 FeatureSelector中的 feature_importances 属性中可以访问所有的特征重要性。
fs.feature_importances.head(10)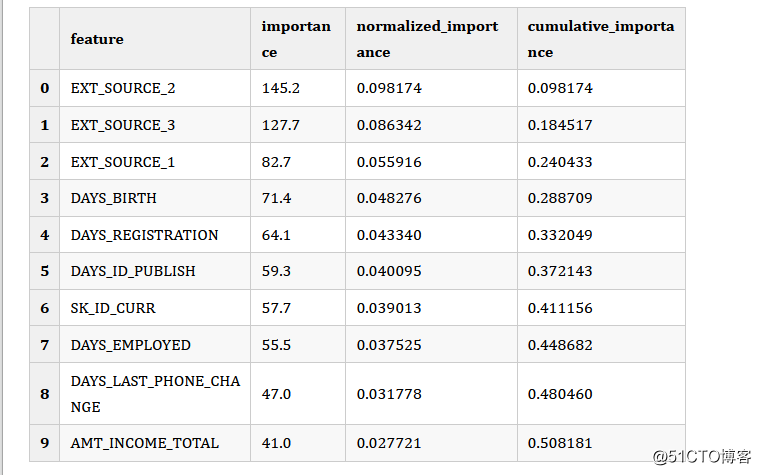
我们可以使用这些结果来仅选择“”个最重要的特征。例如,如果我们希望排名前100位的重要性最高,则可以执行以下操作。
one_hundred_features = list(fs.feature_importances.loc[:99, ‘feature‘])
len(one_hundred_features)100
此方法使用梯度提升算法(必须首先运行identify_zero_importance)通过查找达到指定的累积总特征重要性所需的最低特征重要性的特征,来构建特征重要性。例如,如果我们输入0.99,则将找到最不重要的特征重要性,这些特征总的不到总特征重要性的99%。
使用此方法时,我们必须已经运行了identify_zero_importance ,并且需要传递一个cumulative_importance ,该值占总特征重要性的一部分。
注意:此方法建立在梯度提升模型的重要性基础之上,并且还是不确定的。我建议使用不同的参数多次运行这两种方法,并测试每个结果的特征集,而不是只选择一个数字。
fs.identify_low_importance(cumulative_importance = 0.99)110 features required for cumulative importance of 0.99 after one hot encoding.
129 features do not contribute to cumulative importance of 0.99.
要删除的低重要性特征是指那些对指定的累积重要性无贡献的特征。这些特征也可以在 ops 词典中找到。
low_importance_features = fs.ops[‘low_importance‘]
low_importance_features[:5][‘NAME_FAMILY_STATUS_Widow‘,
‘WEEKDAY_APPR_PROCESS_START_SATURDAY‘,
‘ORGANIZATION_TYPE_Business Entity Type 2‘,
‘ORGANIZATION_TYPE_Business Entity Type 1‘,
‘NAME_INCOME_TYPE_State servant‘]
一旦确定了要删除的特征,便可以通过多种方式删除这些特征。我们可以访问removal_ops词典中的任何功能列表,并手动删除列。我们还可以使用 remove 方法,传入标识我们要删除的特征的方法。
此方法返回结果数据,然后我们可以将其用于机器学习。仍然可以在特征选择器的 data 属性中访问原始数据。
请注意用于删除特征的方法!在使用删除特征之前,最好先检查将要remove的特征。
train_no_missing = fs.remove(methods = [‘missing‘])Removed 17 features.
Removed 98 features.
要从所有方法中删除特征,请传入 method=‘all‘。在执行此操作之前,我们可以使用check_removal检查将删除了多少个特征。这将返回已被识别为要删除的所有特征的列表。
all_to_remove = fs.check_removal()
all_to_remove[10:25]Total of 156 features identified for removal
[‘FLAG_OWN_REALTY_Y‘,
‘FLAG_DOCUMENT_19‘,
‘ORGANIZATION_TYPE_Agriculture‘,
‘FLOORSMIN_MEDI‘,
‘ORGANIZATION_TYPE_Restaurant‘,
‘NAME_HOUSING_TYPE_With parents‘,
‘NONLIVINGAREA_MEDI‘,
‘NAME_INCOME_TYPE_Pensioner‘,
‘HOUSETYPE_MODE_specific housing‘,
‘ORGANIZATION_TYPE_Industry: type 5‘,
‘ORGANIZATION_TYPE_Realtor‘,
‘OCCUPATION_TYPE_Cleaning staff‘,
‘ORGANIZATION_TYPE_Industry: type 12‘,
‘OCCUPATION_TYPE_Realty agents‘,
‘ORGANIZATION_TYPE_Trade: type 6‘]
现在我们可以删除所有已识别的特征。
train_removed = fs.remove(methods = ‘all‘)[‘missing‘, ‘single_unique‘, ‘collinear‘, ‘zero_importance‘, ‘low_importance‘] methods have been run
Removed 156 features.
如果我们查看返回的DataFrame,可能会注意到原始数据中没有的几个新列。这些是在对数据进行独热编码以进行机器学习时创建的。要删除所有独热特征,我们可以将 keep_one_hot = False 传递给 remove 方法。
train_removed_all = fs.remove(methods = ‘all‘, keep_one_hot=False)[‘missing‘, ‘single_unique‘, ‘collinear‘, ‘zero_importance‘, ‘low_importance‘] methods have been run
Removed 190 features including one-hot features.
print(‘Original Number of Features‘, train.shape[1])
print(‘Final Number of Features: ‘, train_removed_all.shape[1])Original Number of Features 121
Final Number of Features: 65
如果我们不想一次运行一个识别方法,则可以使用identify_all 在一次调用中运行所有方法。对于此功能,我们需要传入参数字典以用于每种单独的识别方法。
以下代码在一个调用中完成了上述步骤。
fs = FeatureSelector(data = train, labels = train_labels)
fs.identify_all(selection_params = {‘missing_threshold‘: 0.6, ‘correlation_threshold‘: 0.98,
‘task‘: ‘classification‘, ‘eval_metric‘: ‘auc‘,
‘cumulative_importance‘: 0.99})17 features with greater than 0.60 missing values.
4 features with a single unique value.
21 features with a correlation magnitude greater than 0.98.
Training Gradient Boosting Model
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[46] valid_0‘s auc: 0.743917 valid_0‘s binary_logloss: 0.254668
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[82] valid_0‘s auc: 0.766619 valid_0‘s binary_logloss: 0.244264
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[55] valid_0‘s auc: 0.72614 valid_0‘s binary_logloss: 0.26157
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[81] valid_0‘s auc: 0.756286 valid_0‘s binary_logloss: 0.251242
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[39] valid_0‘s auc: 0.686351 valid_0‘s binary_logloss: 0.269367
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[41] valid_0‘s auc: 0.744124 valid_0‘s binary_logloss: 0.255549
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[90] valid_0‘s auc: 0.761742 valid_0‘s binary_logloss: 0.249119
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[49] valid_0‘s auc: 0.751569 valid_0‘s binary_logloss: 0.254504
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[76] valid_0‘s auc: 0.726789 valid_0‘s binary_logloss: 0.257181
Training until validation scores don‘t improve for 100 rounds.
Early stopping, best iteration is:
[46] valid_0‘s auc: 0.714889 valid_0‘s binary_logloss: 0.260482
80 features with zero importance after one-hot encoding.
115 features required for cumulative importance of 0.99 after one hot encoding.
124 features do not contribute to cumulative importance of 0.99.
150 total features out of 255 identified for removal after one-hot encoding.
train_removed_all_once = fs.remove(methods = ‘all‘, keep_one_hot = True)[‘missing‘, ‘single_unique‘, ‘collinear‘, ‘zero_importance‘, ‘low_importance‘] methods have been run
Removed 150 features.
fs.feature_importances.head()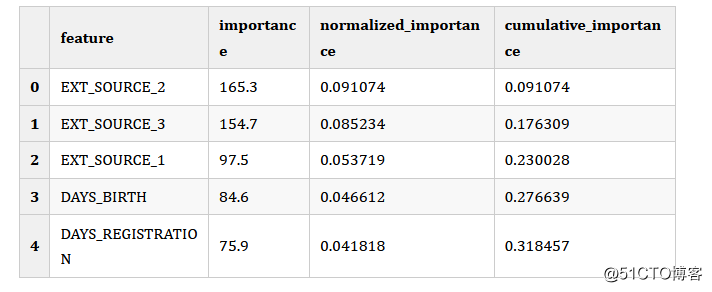
由于特征重要性已更改,因此删除的特征数略有差异。由缺失的(missing)、单一的(single_unique)和共线( collinear)确定要删除的特征数量将保持不变,因为它们是确定性的,但是由于多次训练模型,零重要性( zero_importance )和低重要性(low_importance )的特征数量可能会有所不同。
本笔记本演示了如何使用FeatureSelector类从数据集中删除特征。此实现中有几个重要注意事项:
代码和数据下载地址:
WillKoehrsen:https://github.com/WillKoehrsen/feature-selector
原文:https://blog.51cto.com/15064630/2571673