我们经常听到说Redis是单线程的,也会有疑问:为什么单线程的Redis能那么快?
这里要明白一点:Redis是单线程,主要是指Redis的网络IO和键值对读写是由一个线程来完成的,这也是Redis对外提供键值存储服务的主要流程。但Redis的其他功能,比如持久化、异步删除、集群数据同步等,都是由额外的线程执行的。
我们知道多线程能够提升并发性能,那为什么Redis会采用单线程,而非多线程?为什么单线程能那么快?
下面我们就来学习一下Redis采用单线程的原因。
使用多线程,虽然可以增加系统吞吐率,或是增加系统扩展性,但同样会产生开销。
Redis的数据是在内存里的,是共享的,如果使用多线程就会引发共享资源的竞争,需要引入互斥锁来解决,使得并行变串行。最终系统吞吐率并没有随着线程的增加而增加。
另外,多线程开发需要精细的设计,会增加系统的复杂度,降低代码的易调试性和可维护性。为了避免这些问题,Redis采用单线程模式。
通常来说,单线程的处理能力比多线程要差很多,那Redis却能使用单线程模型达到每秒数十万级别的处理能力,这是为什么呢?
一方面,Redis大多数操作是在内存上完成的,并且采用高效的数据结构,例如哈希表和跳表。另一方面,Redis采用了多路复用机制,使其在网络IO操作中能并发处理大量的客户端请求,实现高吞吐率。
在学习多路复用机制前,我们要弄明白网络操作的基于IO模型和潜在的阻塞点。
以Get请求为例,为了处理一个Get请求:
下图显示了这一过程,其中,bind/listen、accept、recv、parse和send属于网络IO处理,而get属性键值数据操作。
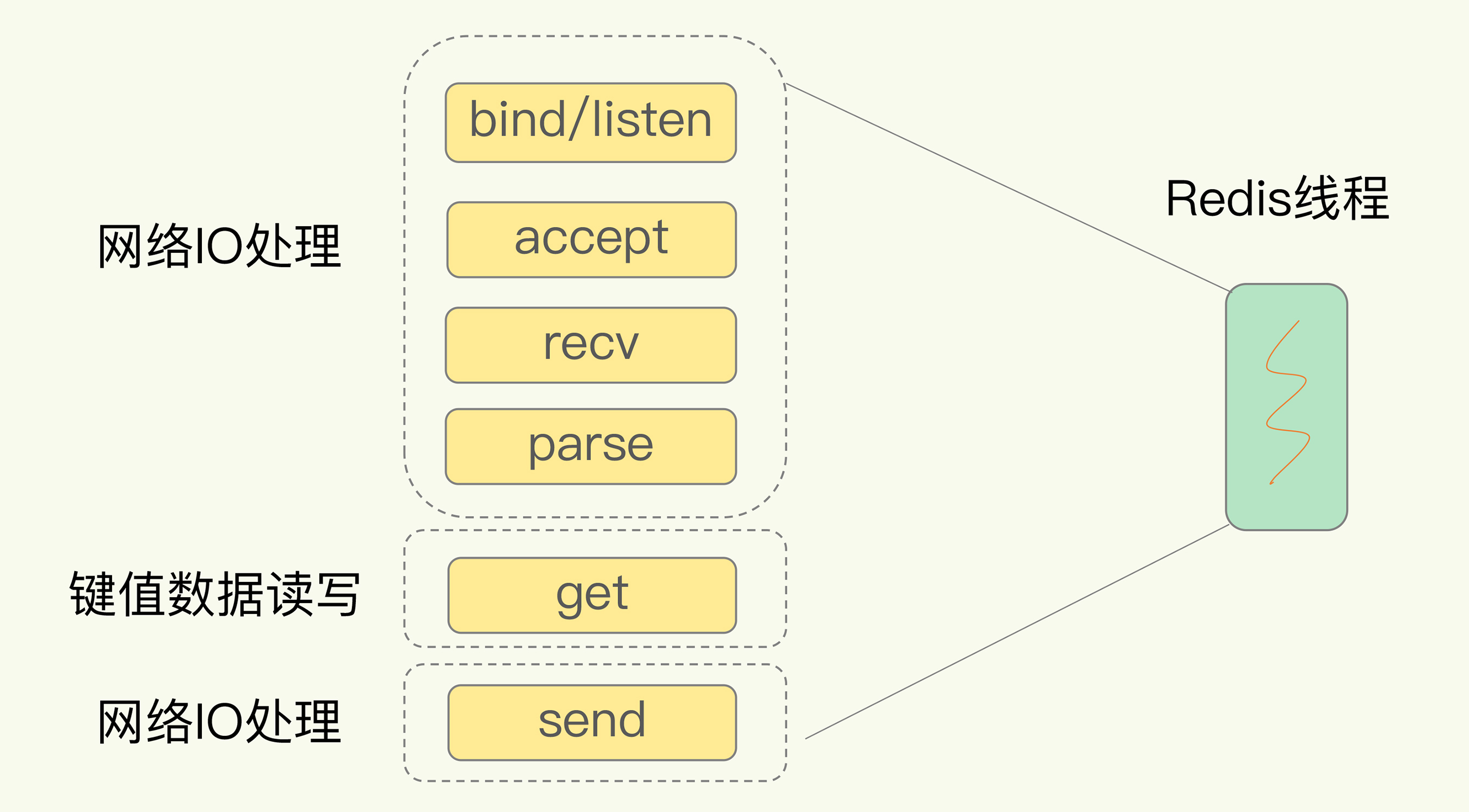
但是在这里的网络IO操作中,有潜在的阻塞点,分别是accept()和recv()。
这就导致Redis整个线程阻塞,无法处理其他客户端请求,效率很低。不过,幸运的是,socket网络模型本身支持非阻塞模式。
Socket网络模型可以设置非阻塞模式。

这样能保证Redis线程既不会像基本IO模型中一直在阻塞点等待,也不会导致Redis无法处理实际到达的连接请求或数据。
下面就到多路复用机制登场了。
Linux的IO多路复用机制是指一个线程处理多个IO流,也就是select/epoll机制。
在Redis运行单线程下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。
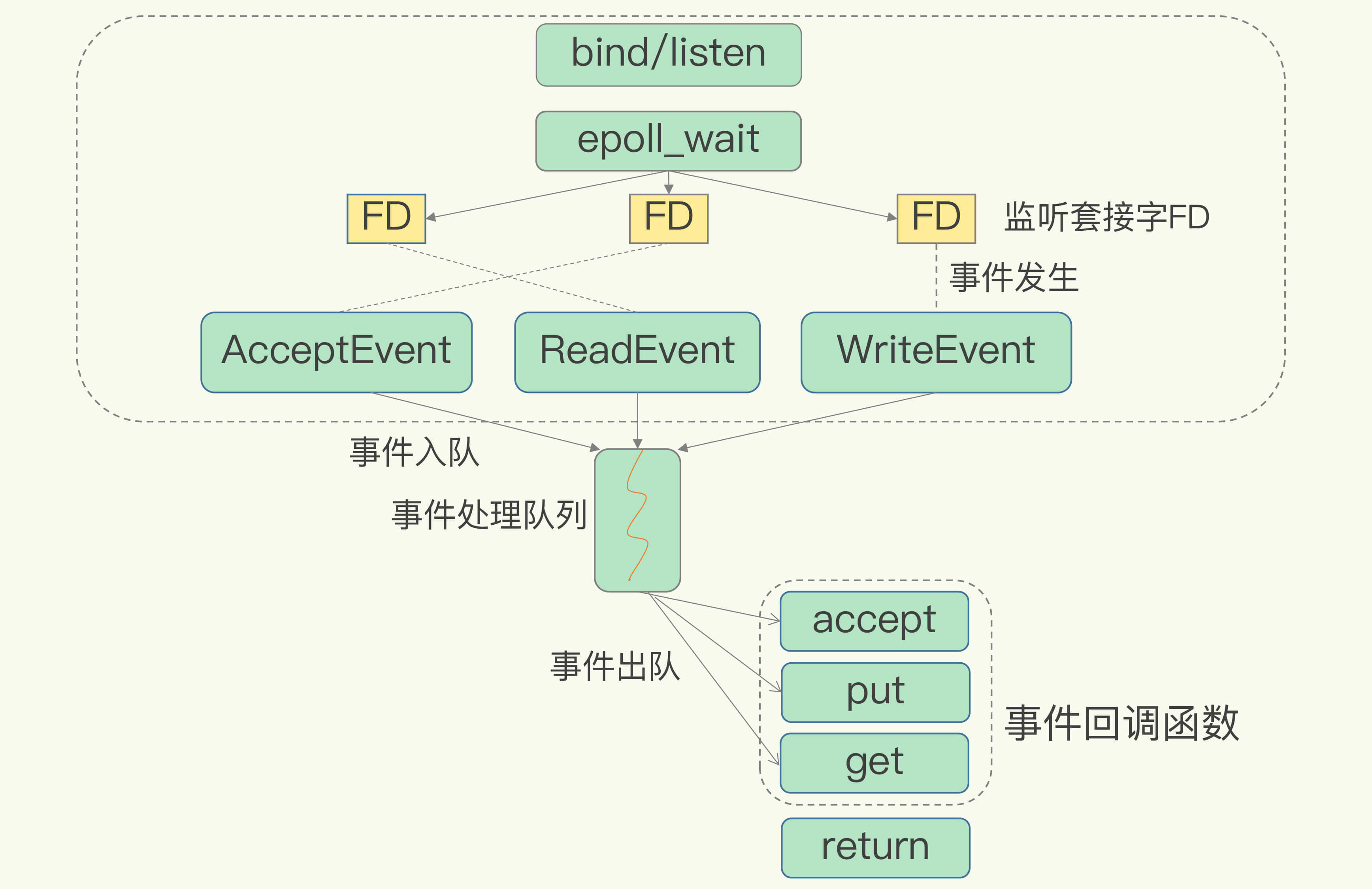
为了在请求到达时能通知到Redis线程,select/epoll提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。
回调机制的工作流程:
因为Redis一直在对事件队列进行处理,所以能及时响应客户端请求,提升Redis的响应性能。
不过,需要注意的是,在不同的操作系统上,多路复用机制也是适用的。
在“Redis基本IO模型”图中,有哪些潜在的性能瓶颈?
Redis单线程处理IO请求性能瓶颈主要包括2个方面:
1、任意一个请求在server中一旦发生耗时,都会影响整个server的性能 也就是说后面的请求都要等前面这个耗时请求处理完成,自己才能被处理到。
耗时的操作包括:
解决办法:
2、并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但是读写客户端数据依旧是同步IO,只能单线程依次读取客户端的数据,无法利用到CPU多核。
解决办法:
原文:https://www.cnblogs.com/liang24/p/14178730.html