Course outline
Chapter 1: DataFrames
Chapter 2:Aggregating Data
Chapter 3:Slicing and Indexing Data
Chapter 4:Creating and Visualizing Data
Chapter 1
.head() : 返回前五行
.info() : 返回每一列的信息,例如数据类型和丢失的值(是否有null)
.shape :返回字典的行和列内容
.describe() : 计算每一列的一些描述性统计,例如count、mean、std、min、25%、50%、75%、max
.values :返回对应的二维NumPy值数组
.columns : 返回列名
.index : 返回行的索引,通常为行号
.isin() : 选择限定的条件 dog["colors"].isin(["Black","Brown"])
.sort_values() : 选定2列进行排序,先按第一列排序,第一列相同时按第二列排序,并且指定2列的排列顺序 df.sort_values(["a","b"],ascending=[True,False])
按要求构造字典的子集(多个要求):dogs[(dogs["a"] > 10) & (dogs["b"] == "regions")]
Chapter 2
.agg(函数名1)/.agg([函数名1,函数名2]) 使用df的列名调用agg(),将会对这列执行agg中的函数
.cumsum() - np.cumsum(a) 输入一维数组/列表,当前列之前的和加到当前列上
- np.cumsum(a,axis=0/1) 输入二维数组/列表,可以使用axis指定累积求和的方向; axis=0 将上一行累加到当前行;axis=1 将上一列累加到当前列
- np.cumsum(a,axis=0/1/2) 输入三维数组/列表

.cummax() 累积和
.cumprod() 累积积
.drop_duplicates(subset="name") 去除一列的重复项
.drop_duplicates(subset=["name","is_holiday"]) 去除两列的重复项
.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True) 统计df或series中不同数或字符串出现的次数,返回一个序列series,该序列包含每个值的数量
参数:normalize : boolean, default False 如果为True,则返回的对象将包含唯一值的相对频率。
sort : boolean, default True 按值排序
ascending : boolean, default False 按升序排序
bins : integer, optional 而不是数值计算,把它们分成半开放的箱子,一个方便的pd.cut,只适用于数字数据
dropna : boolean, default True 不包括NaN的数量
groupby
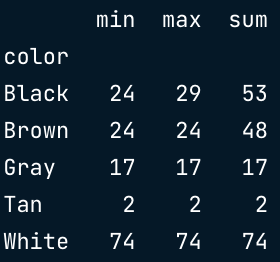
聚合1列: df.groupby("列名")["被计算的列"].agg([min,max,sum])
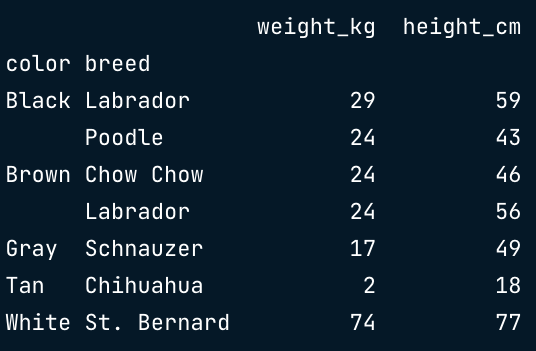
聚合2列:df.groupby(["列名1","列名2"])["被计算的列"].mean()
聚合2列计算2列: df.groupby(["列名1","列名2"])[["被计算的列1","被计算的列2"]].mean()
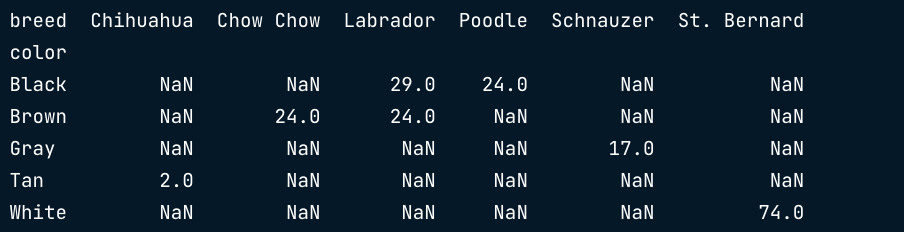
index:表示索引列(层次字段),要通过透视表获得哪些列的信息,就按照相应的顺序设置字段,如果设置多个列名,结果是一样的。
values:对需要的计算数据进行筛选,筛选的是index索引到的表的指定列
aggfunc:设置我们对数据聚合时进行的函数操作,未设置aggfunc时,默认为mean计算均值
columns: 类似index设置列层次字段,它不是一个必要参数,作为一种分割数据的可选方式
fill_value: 设置填充空值
margins = True :表最后一列为ALL 内容为行均值
dogs.groupby(["color","breed"])["weight_kg"].mean()
dogs.pivot_table(values="weight_kg",index="color",columns="breed")
Chapter 3
df[df["列名"].isin(["aaa","ca"])] 选择某列等于多个数值或者字符串,isin()括号内应该是个list
df.sort_values() 既可以根据列数据,也可根据行数据排序,必须要指定哪几行/列
df.sort_index(level="列名",ascending=True/False) 默认根据行标签对所有行排序,或根据列标签对所有列排序
df.set_index("xxx") 设置索引列
.loc["aaa":"bbb"] 索引aaa到bbb
.iloc[n] 通过行号获取行数据,不能是字符
print(‘\n‘,test1.iloc[0])#读取‘One‘行数据
print(‘\n‘,test1.iloc[0,0:3])#读取‘One‘行,‘a‘:‘c‘列的数据
print(‘\n‘,test1.iloc[0:3,0:3])#读取‘One‘:‘Three‘行,‘a‘:‘c‘列的数据
print(‘\n‘,test1.iloc[[0,2],0:3])#读取‘One‘,‘Three‘,:‘Three‘行,‘a‘:‘c‘列的数据
日期之间比较,可以使用数字比较
筛选日期从2020年至2011年: temperatures[(temperatures["date"] >= "2020-01-01") & (temperatures["date"] <= "2011-12-31")]
原文:https://www.cnblogs.com/zhoujingye/p/14169636.html