如果客户端要保存客户的数据,就需要通过客户模块去操作。但是我们想保存后在客户模块调用搜索模块,又想调用缓存模块缓存起来,还想调用其它模块。其实我们的核心业务就是用客户模块去存数据,其它的也是必做的,但是不是我们的核心需求。这时候会有什么问题?
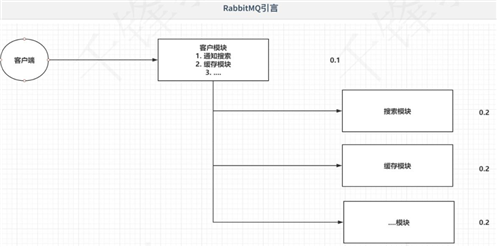
这就需要我们的RabbitMQ来帮我们处理了。
市面上比较火爆的几款MQ:
ActiveMQ(比较古老,比较早)、RocketMQ、Kafka(常用于大数据中)、RabbitMQ。
RabbitMQ是由Rabbit公司去研发和维护的,最终在Pivotal。
RabbitMQ严格的遵循AMQP协议,高级消息队列协议,帮助我们在进程之间传递异步消息。这样上面的两个问题都解决了,因为是异步,如果缓存模块宕机,可以不影响用户模块;又因为是异步,时间从成本变小了,用户模块存储完就返回了,只是有另外的线程去执行搜索模块,缓存模块和...模块。
这里安装还是用Daocker安装。下面是docker-compose管理需要的yml文件:
version: "3.1"
services:
rabbitmq:
image: daocloud.io/library/rabbitmq:management # 这里的版本我们要选择后缀有management的,因为我们除了用rabbitmq还要用其图形化界面,这里就选版本是management,不选x.xmanagement
restart: always
container_name: rabbitmq
ports:
- 5672:5672
- 15672:15672 # 这个是图形化管理界面的端口号,一定要把他也映射上
volumes:
- ./data:/var/lib/rabbitmq # 我们上面已经说过,rabbitmq会对消息持久化,因此我们用volume映射一下这个数据,方便查看。(为了保证消息不会丢失)
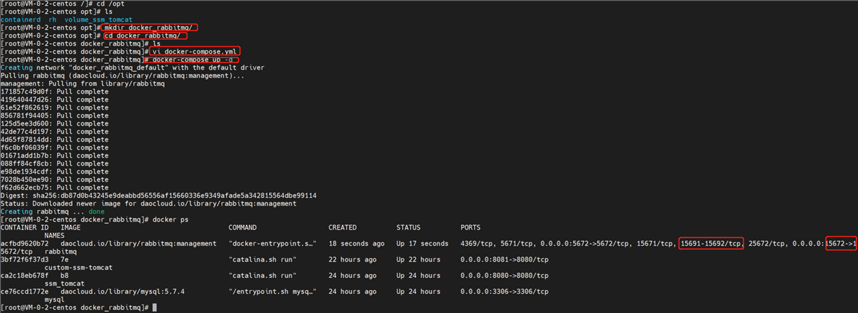
下面我们到xterm中安装一下:
首先进入opt目录下;然后创建docker-rabbitmq文件夹;然后vi docker-compose.yml;然后粘贴上面的yml文件内容,保存;并运行。
下面就可以访问一下,当然我们这里不是访问Rabbit,而是访问rabbitmq的图形化界面:这里有个默认的用户名和密码是guest和guest,这里面的内容等讲Rabbitmq的架构时再讲。
三、RabbitMQ架构
3.1 官方的简单架构图
我这里先大致描述一下下图:这是来自官网的一张图片,我们可以看到最左侧是Publisher,最右侧是Consumer。这两者是没有直接交互的。Publisher是发布消息的,就相当于上面的用户模块,他除了要完成自身的使命保存数据,还要发布消息(调用搜索模块和缓存模块等);而Consumer就是消费消息的,但是这里的消费消息并非是Publisher发布的消息,而是经过处理的消息;这个处理的过程就是RabbitMQ的使命了。我们可以看到RabbitMQ中有两个部分,第一个是Exchange,是与Publish交互的,他接收Publihser发布的消息,然后通过一定的策略转存储到Queue中;而这个Queue和Consumer交互。
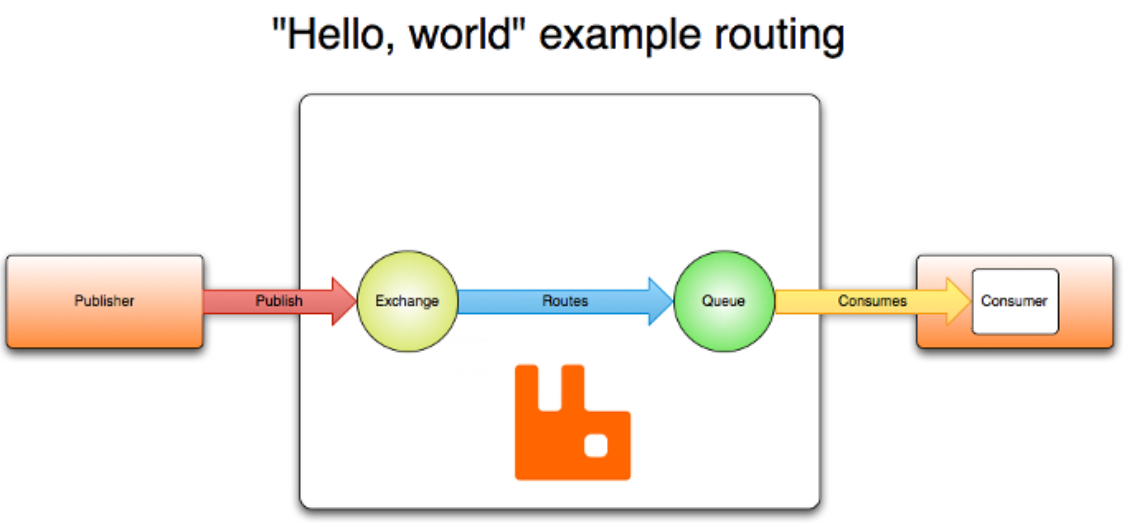
这样的话对于上面的问题,我们在客户模块和下面的搜索模块、缓存模块和...模块间用RabbitMQ就可以解决了,即可以解决:一个模块宕机问题;同步通讯成本问题(现在是异步)。
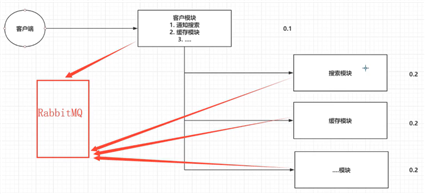
下面我们再讲一下Rabbitmq的详细架构图,我们可以知道上面我们访问的官网显示的都是什么意思。
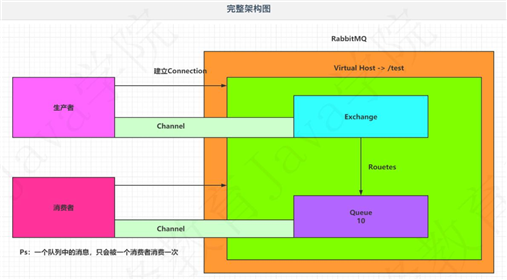
这个图我来解释一下,其实和上面的是一样的,只是这里展示了如何使用RabbitMQ。
要想使用RabbitMQ,首先我们得有RabbitMQ;然后RabbitMQ里面有许多Vrtual Host,即虚拟机,如果我们点开RabbitMQ的Admin会发现里面有一个Virtual Host叫/,RabbitMQ里面有许多Vitural Host,我们这里用的虚拟机是test,我们需要建;然后每个虚拟机里面有许多Exchange和Queue
3.3 查看图形化界面并创建一个Virtual Host
这里查看图形化界面并创建一个Virtual Host,以便我们后面对RabbitMQ的使用。
在RabbitMQ的首页,展示的是Overview页面,这个是展示RabbitMQ所有信息的页面,但是不作为我们的重点。
原文:https://www.cnblogs.com/G-JT/p/14189909.html