SortShuffleWriter的实现过程如下图所示:
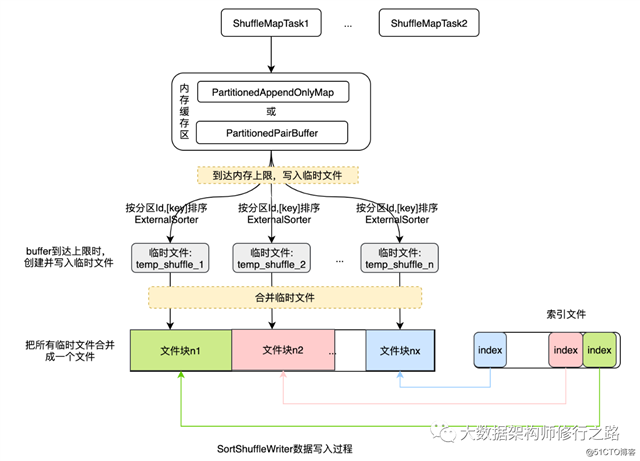
对该过程的说明如下:
1)不断地把每个分区的数据填充到内存buffer中,有两种buffer:若需要通过key来进行聚合,则会使用PartitionedAppendOnlyMap结构;若不需要进行聚合操作,则使用PartitionedPairBuffer。在buffer中,会先按分区Id对记录进行排序,然后可能还会根据key进行排序。为了避免每个key多次使用分区器(partitioner),会把分区ID与每条记录一起存储,形如:((partitionId, K), V)。
2)当buffer达到内存上限时,就会把buffer的内容写入磁盘的一个临时文件中,然后释放内存资源。若我们需要进行聚合操作时,会先对记录按分区Id进行排序,然后还可能根据key或key的hashcode进行排序。对于每个文件,会跟踪记录每个分区有多少条数据,所以,我们不需要为每条数据写出分区Id。
3)然后,合并这些临时文件,包括目前在内存中的数据。若没有排序和聚合操作会按第2)步中的记录顺序进行合并;若需要按key进行聚合,则需要进行总体排序,或读取具有相同hashcode的可以,然后对其值进行排序。
该排序器对数据进行排序,并合并多个类型为(K,V)的键-值对来生成类型为(K,C)的键-组合器对。它使用分区器首先将键值分组到分区中,然后使用自定义比较器有选择地对每个分区中的键值进行排序。对于Shuffle操作获取数据时,可能会输出一个具有不同大小的单个分区文件。
外部排序器会反复填充数据的缓冲区,若想通过key来进行聚合操作,则使用:PartitionedAppendOnlyMap来缓存数据。若不对数据进行聚合,则使用:PartitionedPairBuffer来缓存数据。在缓存区中,ExternalSorter会按分区ID对元素进行排序,然后也可以按key进行排序。为避免每个key多次调用分区程序,将分区ID存储在每条记录处。
当每个缓冲区达到ExternalSorter规定的内存限制时,会将其写出到文件中。如果想要进行聚合,则该文件首先按分区ID排序,并且可能按key或key的哈希值进行排序。对于每个文件,ExternalSorter会跟踪内存中每个分区中有多少对象,因此不必把每个元素写出分区ID。
当用户请求迭代器或文件输出时,使用上面定义的相同排序顺序合并写出的文件以及任何剩余的内存数据(除非禁用排序和聚合)。如果我们需要按key聚合,要么使用排序参数的总排序,要么读取具有相同哈希值的键key,并将它们相互比较以获得合并值的一致性。
在ExternalSorter对象进行初始化时,会获取一些环境配置,和辅助的类对象。具体的初始化过程如下:
获取SparkEnv的配置数据,直接通过conf = SparkEnv.get.conf进行获取。
获取分区数:numPartitions = partitioner.map(_.numPartitions).getOrElse(1)
获取数据块管理器:blockManager = SparkEnv.get.blockManager
获取磁盘数据块管理器:diskBlockManager = blockManager.diskBlockManager
获取序列化管理器:serializerManager = SparkEnv.get.serializerManager
实例化序列化管理器:serInstance = serializer.newInstance()
获取配置参数的值:spark.shuffle.file.buffer
说明,一般情况下,该参数表示:每个shuffle文件输出流的内存缓冲区大小(K)。默认值是:32K
作用:通过这些缓冲区,减少了在创建中间shuffle文件时进行的磁盘I/O和系统调用的次数。
获取配置参数:spark.shuffle.spill.batchSize的值:
说明,该参数表示:每次从序列化器批量读/写对象的个数。该参数的默认值是:10000
对象是批量写入的,每个批处理使用自己的序列化流。这样减少了反序列化流时构造的消耗。
注意:在实际使用时,该值不能设置的太低。若将此设置得太低会导致序列化时过度复制。
// 有聚合操作时使用
@volatile private var map = new PartitionedAppendOnlyMap[K, C]
// 无聚合操作时使用
@volatile private var buffer = new PartitionedPairBuffer[K, C]insertAll函数主要负责把数据放到shuffle writer的写入缓冲区中。上面已经分析过了,在shuffle writer中,buffer分为两种:
map端无聚合操作,使用:PartitionedPairBuffer[K,C]
并且,在使用这两种buffer时,会按分区ID作为key值。
该函数的详细实现步骤如下:
在aggregator对象中获取设置初始值和更新值的回调函数
遍历记录,若使用了聚合操作,则把记录数据添加到:PartitionedAppendOnlyMap中。若没有聚合操作,则把记录添加到:PartitionedPairBuffer缓冲区中。在写入缓冲区时,都以分区ID作为key。
调用maybeSpillCollection()函数。该函数会调用maybeSpill函数,来判断缓冲区目前的使用情况,并根据使用情况把数据刷到磁盘,每次写入磁盘时都会生成一个临时文件,这样可能会形成多个临时文件,这些临时文件会被记录在定义的变量spillfile中,这些文件会在最后进行合并。
maybeSpill()函数的操作如下:
判断读取的元素个数是否是32的倍数(内存对齐) 且 目前的内存使用量是否超过阈值,即参数:spark.shuffle.spill.initialMemoryThreshold"的值。默认是5M。
若以上条件满足,则会申请:目前使用内存的2倍内存-阈值 这么大的内存。若申请失败,则直接把数据写入到磁盘,并释放内存空间。
若目前的内存占有量大于可用内存的阈值,就应该把数据写入到磁盘上,此时会shouldSpill变量设置为true。
接下来会调用spill()函数把数据写入到磁盘。
scala> val rdd = sc.parallelize(0 to 8).map(s => (s, 1)).reduceByKey((a,b)=>a+b)
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[7] at reduceByKey at <console>:25
scala> rdd.dependencies
res6: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@733f5bf4)
scala> import org.apache.spark.ShuffleDependency
import org.apache.spark.ShuffleDependency
scala> val shuffleDep = rdd.dependencies(0).asInstanceOf[ShuffleDependency[Int, Int, Int]]
shuffleDep: org.apache.spark.ShuffleDependency[Int,Int,Int] = org.apache.spark.ShuffleDependency@733f5bf4
scala> shuffleDep.mapSideCombine
res7: Boolean = true
scala> shuffleDep.aggregator // 查看是否有聚合器
res8: Option[org.apache.spark.Aggregator[Int,Int,Int]] = Some(Aggregator(<function1>,<function2>,<function2>))
scala> shuffleDep.partitioner.numPartitions // 查看分区数
res9: Int = 1
scala> shuffleDep.shuffleHandle // 查看ShuffleHandle的值
res10: org.apache.spark.shuffle.ShuffleHandle = org.apache.spark.shuffle.BaseShuffleHandle@4fc12922从以上代码可以看出,当使用reduceByKey时会产生shuffle操作,从以上操作结果可以看出,ShuffleHandle是BaseShuffleHandle,对应的shufflewriter是SortShuffleWriter。
SortShuffleWriter会先把数据先写入到内存中,并会尝试扩展内存大小,若内存不足,则把数据持久化到磁盘上。
SortShuffleWriter在把数据写入磁盘时,会按分区ID进行合并,并对key进行排序,然后写入到该分区的临时文件中。
原文:https://blog.51cto.com/15067227/2573447