Shuffle Writer负责将Map任务的输出,写出到Shuflle系统的文件中。在基于排序的shuffle框架中,ShuffleWriter还会合并文件,它为每个Map Task生成一个数据文件和一个索引文件。
在运行ShuffleMapTask时,会根据shuffleHandle的值来创建具体的ShuffleWriter对象。代码如下:
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)那么shuffleHandle是由什么决定的呢?实际上shufflehandle是在构建ShuffleDependency对象时,会调用shuffleManager#registerShuffle函数,并根据ShuffleDependency的值来注册对应的ShuffleHandle。实际创建的ShuffleHandle类和条件的对应关系如下表:

从实现层面来看,ShuffleWriter是一个抽象父类,继承该父类的子类有三种,所以在Spark中有三种类型的ShuffleWriter。它们是:
BypassMergeSortShuffleWriter
UnsafeShuffleWriter
Spark根据不同的ShuffleHandle来选择这三种ShuffleWriter。ShuffleHandle和ShuffleWriter的对应关系如下表所示:

ShuffleWriter抽象类只定义了两个函数,代码如下:
// 代码位置:org.apache.spark.shuffle.ShuffleWriter
private[spark] abstract class ShuffleWriter[K, V] {
// 把task一些列输出记录写出到文件中
@throws[IOException]
def write(records: Iterator[Product2[K, V]]): Unit
/** Close this writer, passing along whether the map completed */
// 关闭shufflewrite,清理shuffle过程中产生的各种临时文件和回收内存资源
def stop(success: Boolean): Option[MapStatus]
}如以上代码所示,每个ShuffleWriter都需要实现write和stop这两个接口函数。
write函数是ShuffleWriter的主功能函数,用来把map任务端的数据写入到文件中,还有可能会对数据进行排序、合并等操作。若数据量巨大时,该函数实现的操作可能会比较消耗内存和IO资源。
stop函数用来清理shuffle过程中产生的临时文件和内存资源。在正常和异常结束的情况下都可以使用stop,这样可以保证不会有临时文件残留,也保证内存资源能够及时的得到释放。另外,stop函数还会记录每个map task的数据写入磁盘文件的时长。
ShuffleWriter的大致流程如下图1所示:
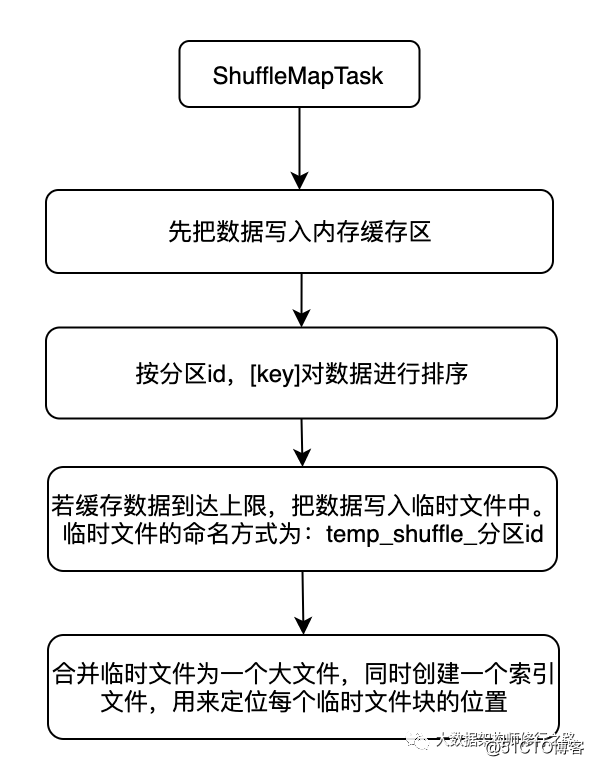
图1 ShuffleWriter写数据的大致流程
(1)在进行shuffle writer时会先把map的数据写入到缓存中。
(2)若缓冲满了,按分区ID对数据进行合并,并对key进行排序,然后写入到该分区的临时文件中。
(3)把临时文件合并成一个大文件,这样每个map任务就得到了一个输出文件。在合并文件时还会生成一个索引文件,通过该索引文件可以方便的找到不同分区数据块在合并文件中对应的位置。这样做可以有效的减少文件个数和系统的资源消耗。
本文介绍了ShuffleWriter的分类和大致处理流程。接下来的文章会对每种ShuffleWriter的实现进行详细分析。
原文:https://blog.51cto.com/15067227/2573455