目标检测推理部署:优化和部署
本文简要介绍了端对端推理管道的优化技术和部署。
将在以下三个方面研究推理优化过程:硬件优化,软件优化和模型优化。推理优化的关键指标如下:
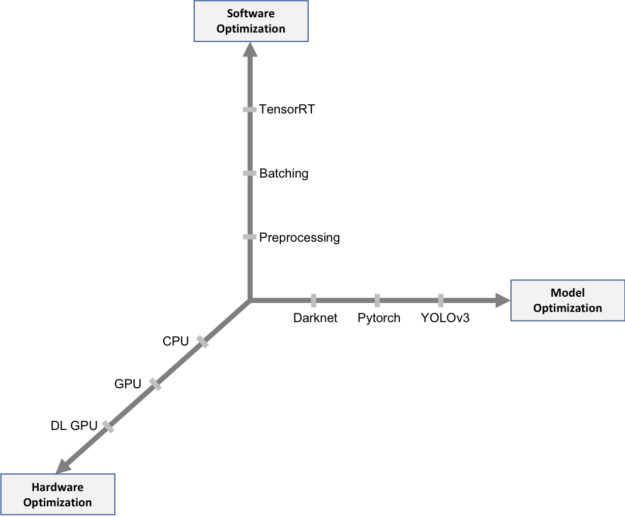
图1.三轴推理优化。
模型优化
YOLOv3-416模型用作预训练模型时,在兼容的数据集上表现最佳。当用作基本模型时,需要调整超参数以更好地适合自定义数据集。下面列出了YOLOv3中需要考虑的体系结构选择和配置:
硬件优化
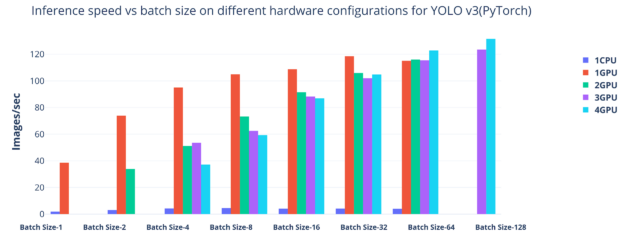
图2. YOLOv3在不同硬件配置上的推理速度与批量大小的关系。
在具有不同批处理大小的单个CPU,单个GPU和多个GPU上运行推理服务器。可以看出,在GPU环境中运行时runtime,推理性能更高。对于较小的批处理大小,未充分利用多GPU,并且最大批处理大小为128,四个GPU的吞吐量最高。
最初在NVIDIA Volta架构中引入的Tensor Core是混合精度训练的主力军。PyTorch支持使用FP32和FP16数据类型的混合精度,从而有效地最大程度地利用Volta和Turing Tensor Core。在16位中执行乘法,然后在32位累加中求和,可实现能源和面积成本的优化。
软件优化
PyTorch提供了高级功能,例如具有强大GPU加速功能的张量计算,无论是将模型放在GPU上还是将张量复制到GPU。使用NVIDIA NGC上提供的PyTorch容器,NVIDIA NGC是GPU优化的软件中心,针对多GPU和多节点系统的支持而针对可扩展性能进行了优化。容器化的环境使构建在PyTorch框架之上的整个目标检测堆栈变得轻便,轻松。该部署能够在Pascal,Volta或基于Turing的NVIDIA DGX,工作站,服务器和领先的云平台上的任何地方运行。
使用DataParallel来最大化四个GPU的利用率。它会自动分割数据,并在多个GPU上的多个模型之间分配它们,并合并输出。使用四个NVIDIA V100 GPU,能够提高每次迭代的推理吞吐量,并且使用四个GPU和一个GPU,批处理大小增加到128张图像。CPU的数量必须足够高,以避免数据预处理和后处理中的瓶颈。需要八个CPU才能达到131 FPS的推理速度。
诸如修剪,权重共享和量化之类的几种技术是可用于增强算法性能的其它优化方法。
Tensor RT优化
诸如PyTorch之类的框架非常灵活,可以快速地表达规定的网络体系结构,因为它们已预先配置了cuDNN之类的库。cuDNN库有效地实现了低级原子运算,以在CUDA中执行卷积,矩阵乘法等。但是,PyTorch之类的框架提供的灵活性确实会增加开销,从而影响部署后的总体推理性能。
TensorRT是一个旨在优化推理性能的库。TensorRT由优化器和运行时runtime引擎组成。优化器是一次操作,负责通过指定推理批大小和FP-32,FP-16或8位INT精度来优化模型图,以将优化的模型或计划序列化到存储中。TensorRT运行时runtime引擎从存储加载优化的模型以在运行时runtime执行推理。在对其它框架的支持中,模型导入器支持通过ONNX格式将基于PyTorch的模型导入TensorRT。 torch2trt 是使用TensorRT Python API的PyTorch到TensorRT转换器。
大规模部署:Dockerzing推理代码
Docker作为容器化平台的兴起极大地简化了创建,部署和管理分布式应用程序的过程。Docker容器将软件包装及其核心组件和依赖项作为标准单元,然后可以在任何计算环境中可靠地运行。
使用PyTorch-YOLOv3系统
从NGC提取的PyTorch容器用作目标检测应用程序堆栈的框架。NGC拥有以下资源:
构建应用程序需要安装一些Python依赖包,例如libopencv-dev。该软件包有助于实时图像处理。运行此应用程序还需要其它基于Python的软件包,例如NumPy,Matplotlib,Pillow,Tqdm和OpenCV-python。NGC上托管的PyTorch容器包括所有这些软件包。
运行NGC GPU容器的前提条件
NGC容器在支持NGC的系统(例如NVIDIA DGX系统,工作站和带有NVIDIA计算服务器的虚拟化环境)中开箱即用。
大多数云服务提供商(CSP)提供随必要的NVIDIA驱动程序,Docker版本和容器工具包一起提供的机器映像。以下是与某些最常见的CSP对应的NVIDIA机器映像:
或者,必须在配备NVIDIA GPU的系统上运行的VM中安装以下软件包:
运行PyTorch-YOLOv3容器
可以运行容器化的PyTorch-YOLOv3应用程序。主机路径可以使用绑定挂载进行安装,而容器路径可以直接从主机输入源数据并将其输出存储在主机中。
要在运行容器时使用机器中所有可用的GPU,请提及--gpus all以下命令中所示。可以通过将以下命令中突出显示的部分替换为来使用有限数量的GPU运行该容器--gpus=<no-of-gpus>。甚至可以通过删除命令中突出显示的部分来仅使用CPU运行此容器。
$ sudo docker run -it --gpus all -v(输入主机路径):(输入容器路径)-v(输出主机路径):(输出容器路径)<PyTorch-YOLOv3-image >
结论
自动驾驶汽车行业一直在寻找从当前状态转变为可部署的安全,自动驾驶车辆所需的技术创新。神经网络的阵列为自动驾驶汽车的感知和决策能力奠定了基础。AI注释模型推论简化了标注新训练数据以开发神经网络的过程,这些神经网络形成了自动驾驶汽车软件开发堆栈的核心,从而节省了宝贵的时间和资源。
本文介绍了自动驾驶上下文中的数据注释管道,包括设置,推理,性能指标,优化,部署以及使用NVIDIA在GPU上运行的端到端目标检测管道的运行时runtime。来自NGC的Docker,并利用TensorRT。
原文:https://www.cnblogs.com/wujianming-110117/p/14196644.html