http://sofasofa.io/forum_main_post.php?postid=1000940
在实际运用中,我个人认为随机森林比支持向量机更加实用。主要有以下几个原因:
随机森林更适用于多元分类。如果用支持向量机处理多元分类的问题,则需要one vs rest的框架。而这种框架通常要消耗更多的内存。
随机森林算法可以输入每个特征的重要程度。
支持向量机的训练过程通常比较费时,尤其是在实用了非线性的核(kernel)的情况下
https://www.jianshu.com/p/a0275e8a90e1?utm_campaign

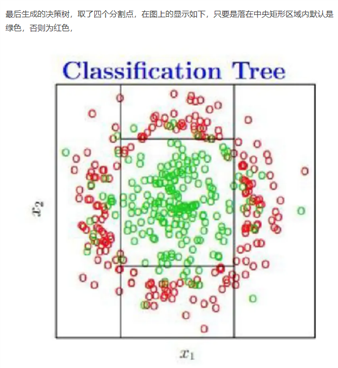
不过这种情况是分类参数选择比较合理的情况(它不介意某些绿色的点落在外围),但是当在训练的时候需要将所有的绿点无差错的分出来(即参数选择不是很合理的情况),决策树会产生过拟合的现象,导致泛化能力变弱。
单纯的决策树是一种非黑即白的分类,这种方式从数学上或者哲学上去理解,相当于工作在低维,缺乏高维抽象能力。用生活中的话说,就是”不够圆滑“。因此引入随机森林这些,相当于提升到了高维一样。
参考上面两幅图的对比。综合准确率和泛化性能来说,第一个图的圆圈分类比较好;但是决策树”直来直去“。当然极限情况下,足够多足够短的直线确实可以拟合圆,但是想想这复杂度。。。
再结合 SVM,核函数可以升维。所以随机森林之于决策树,可以理解为核函数之于 SVM。他们都有升高维度的作用。
原文:https://www.cnblogs.com/rinroll/p/14208369.html