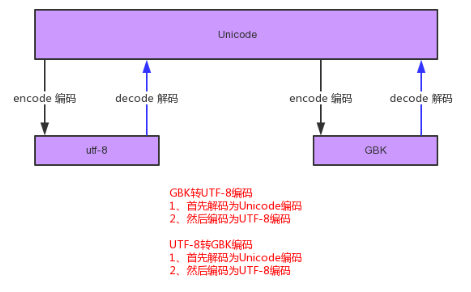
# Python2.7 默认的编码是什么? # 打印系统默认编码 import sys print(sys.getdefaultencoding()) ---> ascii # 虽然程序是用 utf8 但默认编码是 ascii # 如果没有 encode,会自动按系统编码 ascii 自动解码 1-1 s = "你好" s_to_gbk = s.encode("gbk") print(s_to_gbk) print("你好") ---> b‘\xc4\xe3\xba\xc3‘ 你好 2-1 怎么解码呢? s = "你好" s_to_gbk = s.decode().encode("gbk") print(s_to_gbk) print("你好") ---> Error decode 如果不往里面传值,相当于用默认的编码;与没写是一样的 所以必须要显示的写进去 2-2 s = "你好" s_to_unicode = s.decode("utf-8") print(s_to_unicode) s_to_gbk = s_to_unicode.encode("gbk") print(s_to_gbk) 3-1 gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8") print(gbk_to_utf8) # gbk 转成 unicode 要告诉 unicode 之前是什么编码, # 然后 unicode 在去找和这个编码对应的并转成 unicode # 然后在编码成 utf8 4-1 >>> s = "你好" >>> s = u"你好" >>> print(s) 你好 >>> # u 表示 unicode # utf-8 是属于 unicode 的扩展集,unicode 是可以直接在 utf-8 中打印出来的 # 但是 gbk 不行,gbk 和 unicode 必须转换 # utf8 和 unicode 可以直接打印 4-2 如果 s 已经是 unicode了,所有的 decode 动作都是要解成 Unicode 如果已经是 unicode 了,解的时候就会报错 # 现在看看 Python 3 # 在 python3 中 不需要加 编码集 5-1 s = "你哈" # 现在想要转成 gbk,默认就是 unicode,所以不需要解码,直接 encode print(s.encode("gbk")) ---> b‘\xc4\xe3\xb9\xfe‘ # 现在右下角是默认编码 utf-8 5-2 # 如果把默认编码格式改为 gbk 呢? s = "你哈" # 注:默认 utf-8 编码 print(s.encode("gbk")) ---> SyntaxError: Non-UTF-8 code starting with ‘\xc4‘ in file # python3 默认是 unicode 所以无法处理 gbk,因为现在的这个文件是 gbk 编码的 # 所以是无法处理的,那应该怎么办呢? # 需要声明,在文件头声明成 gbk # -*- coding:gbk -*- s = "你哈" # 现在想要转成 gbk,默认就是 unicode,所以不需要解码,直接 encode print(s) print(s.encode("gbk")) ---> 你哈 b‘\xc4\xe3\xb9\xfe‘ # b表示 bites;在python3 中,encode之后,除了修改编码集,会全部变成 bites 类型,这是和 python2 最大的区别 6-1 s = "你哈" s_gbk = s.encode("gbk") print(s_gbk) print(s.encode()) ---> b‘\xc4\xe3\xb9\xfe‘ # gbk b‘\xe4\xbd\xa0\xe5\x93\x88‘ # utf-8 6-2 s = "你哈" s_gbk = s.encode("gbk") print(s_gbk) print(s.encode()) gbk_to_utf8 = s_gbk.decode("gbk").encode("utf-8") print("utf8",gbk_to_utf8) # 先转成 unicode 在转成 utf8 ---> b‘\xc4\xe3\xb9\xfe‘ b‘\xe4\xbd\xa0\xe5\x93\x88‘ utf8 b‘\xe4\xbd\xa0\xe5\x93\x88‘ # 所有的字符集转换都要经过一个 unicode
原文:https://www.cnblogs.com/azxsdcv/p/14217785.html