二分查找真的很简单吗?并不简单。看看 Knuth 大佬(发明 KMP 算法的那位)怎么说的:
Although the basic idea of binary search is comparatively straightforward, the details can be surprisingly tricky...
这句话可以这样理解:思路很简单,细节是魔鬼。
本文就来探究几个最常用的二分查找场景:寻找一个数、寻找左侧边界、寻找右侧边界。而且,我们就是要深入细节,比如不等号是否应该带等号,mid 是否应该加一等等。分析这些细节的差异以及出现这些差异的原因,保证你能灵活准确地写出正确的二分查找算法。
int binarySearch(int[] nums, int target) { int left = 0, right = ...; while(...) { int mid = (right + left) / 2; if (nums[mid] == target) { ... } else if (nums[mid] < target) { left = ... } else if (nums[mid] > target) { right = ... } } return ...; }
分析二分查找的技巧:
不要出现 else,而是把所有情况用 else if 写清楚,这样可以清楚地展现所有细节。
计算 mid 时需要技巧防止溢出( int mid = left + (right - left >> 1) ;)。
这个场景是最简单的,肯能也是大家最熟悉的,即搜索一个数,如果存在,返回其索引,否则返回 -1。
int binarySearch(int[] nums, int target) { int left = 0; int right = nums.length - 1; // 注意 while(left <= right) { // 注意 int mid = (right + left) / 2; if(nums[mid] == target) return mid; else if (nums[mid] < target) left = mid + 1; // 注意 else if (nums[mid] > target) right = mid - 1; // 注意 } return -1; }
?? 为什么 while 循环的条件中是 <=,而不是 < ?
因为初始化 right 的赋值是 nums.length - 1,即最后一个元素的索引,而不是 nums.length。
这二者可能出现在不同功能的二分查找中,区别是:前者相当于两端都闭区间 [left, right],后者相当于左闭右开区间 [left, right),因为索引大小为 nums.length 是越界的。
我们这个算法中使用的是前者 [left, right] 两端都闭的区间。这个区间其实就是每次进行搜索的区间。
什么时候应该停止搜索呢?当然,找到了目标值的时候可以终止:
if (nums[mid] == target)return mid;但如果没找到,就需要 while 循环终止,然后返回 -1。那 while 循环什么时候应该终止?搜索区间为空的时候应该终止,意味着你没得找了,就等于没找到嘛。
while(left <= right)的终止条件是 left == right + 1,写成区间的形式就是 [right + 1, right],或者带个具体的数字进去 [3, 2],可见这时候区间为空,因为没有数字既大于等于 3 又小于等于 2 的吧。所以这时候 while 循环终止是正确的,直接返回 -1 即可。
while(left < right)的终止条件是 left == right,写成区间的形式就是 [left, right],或者带个具体的数字进去 [2, 2],这时候区间非空,还有一个数 2,但此时 while 循环终止了。也就是说这区间 [2, 2] 被漏掉了,索引 2 没有被搜索,如果这时候直接返回 -1 就是错误的。当然,如果你非要用 while(left < right) 也可以,我们已经知道了出错的原因,就打个补丁好了:
//...while (left < right) {// ...}return nums[left] == target ? left : -1;
?? 为什么 left = mid + 1,right = mid - 1?我看有的代码是 right = mid 或者 left = mid,没有这些加加减减,到底怎么回事,怎么判断?
这也是二分查找的一个难点,不过只要你能理解前面的内容,就能够很容易判断。
刚才明确了「搜索区间」这个概念,而且本算法的搜索区间是两端都闭的,即 [left, right]。那么当我们发现索引 mid 不是要找的 target 时,如何确定下一步的搜索区间呢?
当然是 [left, mid - 1] 或者 [mid + 1, right] 对不对?因为 mid 已经搜索过,应该从搜索区间中去除。
?? 此算法有什么缺陷?
至此,你应该已经掌握了该算法的所有细节,以及这样处理的原因。但是,这个算法存在局限性。
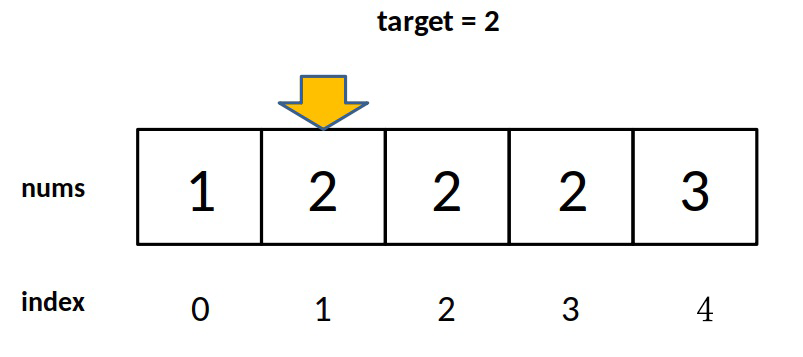
比如说给你有序数组 nums = [1,2,2,2,3],target = 2,此算法返回的索引是 2,没错。但是如果我想得到 target 的左侧边界,即索引 1,或者我想得到 target 的右侧边界,即索引 3,这样的话此算法是无法处理的。
这样的需求很常见。你也许会说,找到一个 target,然后向左或向右线性搜索不行吗?可以,但是不好,因为这样难以保证二分查找对数级的复杂度了。
我们后续的算法就来讨论这两种二分查找的算法。
int left_bound(int[] nums, int target) {
if (nums.length == 0) return -1;
int left = 0;
int right = nums.length; // 注意
while (left < right) { // 注意
int mid = (left + right) / 2;
if (nums[mid] == target) {
right = mid;
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid; // 注意
}
}
return left;
}
?? 为什么 while(left < right) 而不是 <= ?
用相同的方法分析,因为 right = nums.length 而不是 nums.length - 1 。因此每次循环的「搜索区间」是 [left, right) 左闭右开。
while(left < right) 终止的条件是 left == right,此时搜索区间 [left, left) 为空,所以可以正确终止。
?? 为什么没有返回 -1 的操作?如果 nums 中不存在 target 这个值,怎么办?
因为要一步一步来,先理解一下这个「左侧边界」有什么特殊含义:
对于这个数组,算法会返回 1。这个 1 的含义可以这样解读:nums 中小于 2 的元素有 1 个。
比如对于有序数组 nums = [2,3,5,7], target = 1,算法会返回 0,含义是:nums 中小于 1 的元素有 0 个。
再比如说 nums 不变,target = 8,算法会返回 4,含义是:nums 中小于 8 的元素有 4 个。
综上可以看出,函数的返回值(即 left 变量的值)取值区间是闭区间 [0, nums.length],所以我们简单添加两行代码就能在正确的时候 return -1:
while (left < right) { //... } // target 比所有数都大 if (left == nums.length) return -1; // 类似之前算法的处理方式 return nums[left] == target ? left : -1;
?? 为什么 left = mid + 1,right = mid ?和之前的算法不一样?
这个很好解释,因为我们的「搜索区间」是 [left, right) 左闭右开,所以当 nums[mid] 被检测之后,下一步的搜索区间应该去掉 mid 分割成两个区间,即 [left, mid) 或 [mid + 1, right)。
?? 为什么该算法能够搜索左侧边界?
关键在于对于 nums[mid] == target 这种情况的处理:
if (nums[mid] == target)right = mid;可见,找到 target 时不要立即返回,而是缩小「搜索区间」的上界 right,在区间 [left, mid) 中继续搜索,即不断向左收缩,达到锁定左侧边界的目的。
?? 为什么返回 left 而不是 right?
都是一样的,因为 while 终止的条件是 left == right。
寻找右侧边界和寻找左侧边界的代码差不多,只有两处不同,已标注:
int right_bound(int[] nums, int target) { if (nums.length == 0) return -1; int left = 0, right = nums.length; while (left < right) { int mid = (left + right) / 2; if (nums[mid] == target) { left = mid + 1; // 注意 } else if (nums[mid] < target) { left = mid + 1; } else if (nums[mid] > target) { right = mid; } } return left - 1; // 注意 }
?? 为什么这个算法能够找到右侧边界?
类似地,关键点还是这里:
if (nums[mid] == target) {left = mid + 1;当 nums[mid] == target 时,不要立即返回,而是增大「搜索区间」的下界 left,使得区间不断向右收缩,达到锁定右侧边界的目的。
?? 为什么最后返回 left - 1 而不像左侧边界的函数,返回 left?而且我觉得这里既然是搜索右侧边界,应该返回 right 才对。
首先,while 循环的终止条件是 left == right,所以 left 和 right 是一样的,你非要体现右侧的特点,返回 right - 1 好了。
至于为什么要减一,这是搜索右侧边界的一个特殊点,关键在这个条件判断:
if (nums[mid] == target) {left = mid + 1;// 这样想: mid = left - 1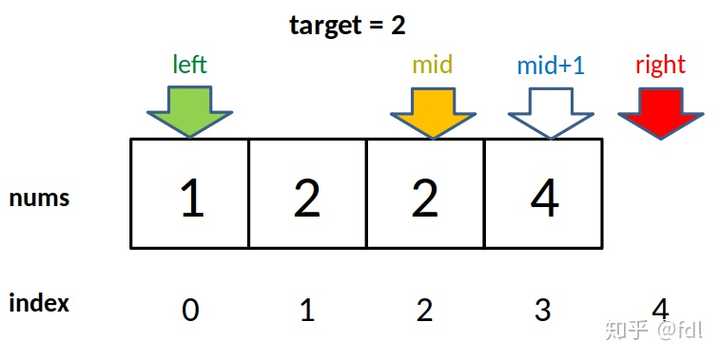
因为我们对 left 的更新必须是 left = mid + 1,就是说 while 循环结束时,nums[left] 一定不等于 target 了,而 nums[left-1] 可能是 target。
至于为什么 left 的更新必须是 left = mid + 1,同左侧边界搜索,就不再赘述。
?? 为什么没有返回 -1 的操作?如果 nums 中不存在 target 这个值,怎么办?
类似之前的左侧边界搜索,因为 while 的终止条件是 left == right,就是说 left 的取值范围是 [0, nums.length],所以可以添加两行代码,正确地返回 -1:
while (left < right) {// ...}if (left == 0)return -1;return nums[left - 1] == target ? (left - 1) : -1;
传送带上的包裹必须在 D 天内从一个港口运送到另一个港口。
传送带上的第 i 个包裹的重量为 weights[i]。每一天,我们都会按给出重量的顺序往传送带上装载包裹。我们装载的重量不会超过船的最大运载重量。
返回能在 D 天内将传送带上的所有包裹送达的船的最低运载能力。
示例 1:
输入:weights = [1,2,3,4,5,6,7,8,9,10], D = 5 输出:15 解释: 船舶最低载重 15 就能够在 5 天内送达所有包裹,如下所示: 第 1 天:1, 2, 3, 4, 5 第 2 天:6, 7 第 3 天:8 第 4 天:9 第 5 天:10 请注意,货物必须按照给定的顺序装运,因此使用载重能力为 14 的船舶并将包装分成 (2, 3, 4, 5), (1, 6, 7), (8), (9), (10) 是不允许的。
示例 2:
输入:weights = [3,2,2,4,1,4], D = 3 输出:6 解释: 船舶最低载重 6 就能够在 3 天内送达所有包裹,如下所示: 第 1 天:3, 2 第 2 天:2, 4 第 3 天:1, 4
示例 3:
输入:weights = [1,2,3,1,1], D = 4 输出:3 解释: 第 1 天:1 第 2 天:2 第 3 天:3 第 4 天:1, 1
提示:
1 <= D <= weights.length <= 50000 1 <= weights[i] <= 500
思路:
??对于一艘承载力为K船来说,我们必然会在不超过其承载力的前提下贪心地往上装载货物,这样才能使得运送包裹所花费的时间最短。
??如果船在承载力为K的条件下可以完成在D天内送达包裹的任务,那么任何承载力大于K的条件下依然也能完成任务。
??我们可以让这个承载力K从max(weights)max(weights)开始(即所有包裹中质量最大包裹的重量,低于这个重量我们不可能完成任务),逐渐增大承载力K,直到K可以让我们在D天内送达包裹。此时K即为我们所要求的最低承载力。
??逐渐增大承载力K的方法效率过低,让我们用二分查找的方法来优化它。
class Solution { public: int shipWithinDays(vector<int>& weights, int D) { //1.最低运载能力必然大于等于序列中的最大值;结果落在[max(weights), sum(weights)] //2.要注意是在D天“内”完成,所以运载能力要尽量小,只要是在D天之内就可以 int left = *max_element(weights.begin(), weights.end()); int right = accumulate(weights.begin(), weights.end(), 0); int mid; int ans = 0x3f3f3f3f; while (left <= right) { mid = left + right >> 1; int temp = 0; int day = 0; for (int i = 0; i < weights.size(); i++) { temp += weights[i]; //当到某个包裹大于运载能力,之前的包裹记为一天 //这个包裹开始记为第二天 if (temp > mid) { day++; temp = weights[i]; } } day++; //剩下的包裹再记一天 if (day > D) //运载能力不够 left = mid + 1; else { //运载能力过剩 right = mid - 1; ans = min(ans, mid); //保存满足条件的运载能力数值 } } return ans; //返回答案 } };
珂珂喜欢吃香蕉。这里有 N 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 H 小时后回来。
珂珂可以决定她吃香蕉的速度 K (单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉 K 根。如果这堆香蕉少于 K 根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉。
珂珂喜欢慢慢吃,但仍然想在警卫回来前吃掉所有的香蕉。
返回她可以在 H 小时内吃掉所有香蕉的最小速度 K(K 为整数)。
示例 1:
输入: piles = [3,6,7,11], H = 8 输出: 4
示例 2:
输入: piles = [30,11,23,4,20], H = 5 输出: 30
示例 3:
输入: piles = [30,11,23,4,20], H = 6 输出: 23
提示:
1 <= piles.length <= 10^4 piles.length <= H <= 10^9 1 <= piles[i] <= 10^9
思路:
??珂珂吃香蕉的速度越小,耗时越多。反之,速度越大,耗时越少,这是这个问题的单调性;
??搜索的是速度。因为题目限制了珂珂一个小时之内只能选择一堆香蕉吃,因此速度最大值就是这几堆香蕉中,数量最多的那一堆。速度的最小值是 11,其实还可以再分析一下下界是多少,由于二分搜索的时间复杂度很低,严格的分析不是很有必要;
??还是因为珂珂一个小时之内只能选择一堆香蕉吃,因此:每堆香蕉吃完的耗时 = 这堆香蕉的数量 / 珂珂一小时吃香蕉的数量,这里的 / 在不能整除的时候,需要 上取整。
class Solution { public: int minEatingSpeed(vector<int>& piles, int H) { int len = piles.size(); // 所有香蕉树 long long sum = 0; for (int i = 0; i < len; i++) sum += piles[i]; // 每小时能吃的香蕉的最多数量 int right = *max_element(piles.begin(), piles.end()); // 每小时能吃的香蕉的最少数量 int left = sum / H + (sum % H ? 1 : 0); int mid; // 先假设每小时要吃最大数量 int ans = right; while (left <= right) { mid = left + (right - left >> 1); int hour = 0; // 每小时吃 mid 个香蕉吃完要 hour 个小时 for (int i = 0; i < len; i++) hour += piles[i] / mid + (piles[i] % mid ? 1 : 0); if (hour > H) // 未在警卫回来前吃掉所有的香蕉 left = mid + 1; else { right = mid - 1; // 在警卫回来前吃掉所有的香蕉 ans = min(ans, mid); // 取吃的香蕉的最少数量 } } return ans; } };
?? 最基本的二分查找算法:
因为我们初始化 right = nums.length - 1所以决定了我们的「搜索区间」是 [left, right]所以决定了 while (left <= right)同时也决定了 left = mid+1 和 right = mid-1因为我们只需找到一个 target 的索引即可所以当 nums[mid] == target 时可以立即返回
?? 寻找左侧边界的二分查找:
因为我们初始化 right = nums.length所以决定了我们的「搜索区间」是 [left, right)所以决定了 while (left < right)同时也决定了 left = mid + 1 和 right = mid因为我们需找到 target 的最左侧索引所以当 nums[mid] == target 时不要立即返回而要收紧右侧边界以锁定左侧边界
?? 寻找右侧边界的二分查找:
因为我们初始化 right = nums.length所以决定了我们的「搜索区间」是 [left, right)所以决定了 while (left < right)同时也决定了 left = mid + 1 和 right = mid因为我们需找到 target 的最右侧索引所以当 nums[mid] == target 时不要立即返回而要收紧左侧边界以锁定右侧边界又因为收紧左侧边界时必须 left = mid + 1所以最后无论返回 left 还是 right,必须减一
修改了部分内容,加入了部分题解应用,如有不当之处欢迎指正??????原文:https://www.cnblogs.com/dreamy-xay/p/14223429.html