外键约束
1.目的:限制表添加信息的类型
2.添加外键的语法:constrain 外键约束名称 foreign key(外键的字段名称) reference 主表的表名(一般管关联主键)
3.一般来说都是在从表中添加外键,指定主表的主键,达到连接的目的
4.格式:alter table 从表表名 add constrain 外键约束的名称 foreign key(外键的字段名称) reference 主表的表名(主键字段名)
5.点击左上角表图标,再点击右下角一个ER图表,点开之后就能阿卡拿到哪些表之间有外键约束
6.删除外键:alter table 从表表名 drop froeign key 外键名称;
7.注意:对于已经存在的表删除外键,必须先删除相关联标的非法数据
8.外键约束代码

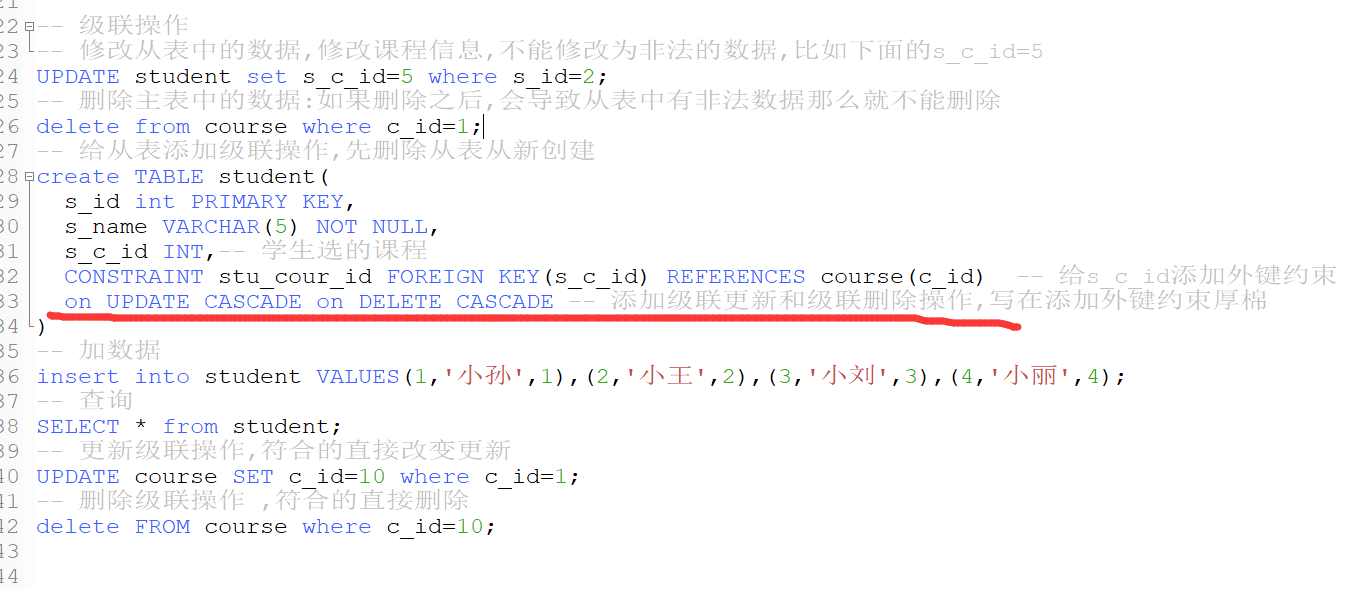
级联操作:两张表之间已经有啦主外键关联
1.概念:在修改或者删除朱标的时候,同时他会更新或者删除从表中的外键值,这种操作称为级联
2.修改表中的数据,修改课程信息,不能修改为非法数据
3.删除主表的数据:如果删除之后导致从表数据会非法,那么就不能被删除调
4.更新级联:on update cascade 只能在创建表的时候创建级联,当更新主表中的主键,从表中的外键会同步更新
5.删除级联:on delete cascade 删除主表中的主键的时候,从表中含有该字段的记录会同步删除
6.级联代码
约束总结:
1.主键约束 primary key 唯一不为空
2.默认约束 defalut 插入数据,字段没有赋值时候 系统,就会自动赋默认值
3.非空约束 not null 不为null
4.唯一约束 unique 该字段在数据在整个表中只能出现一次
5.外键约束 foreign key 从表中加外键关联主表的主键
表与表之间的关系
1.一对一关系:通常写在一个表里面
2.一对多关系:
3.多对多关系:
多对多建表:需要建立中间表

一对多建表:设计的时候先创建主表再创建从表

表与表之间的关系总结
1.一对一建表:
直接把两个表合在一起,非要分开就是互为外键约束
2.多对多建表:
需要建立中间表:中间表内部分别添加外键约束关联各对应的主键
3.一对多建表
在从表的那一方(多的那一方)建立外键被主表的主键约束,先创建主表再创建从表
数据库设计的范式
1.概念:
- 在设计数据库的时候,需要遵从的规范要求,根据这些规范要求设计出合理的数据库,致谢桂芳就成为范式,主要是针对于关系型数据库,目前来说
- 目前关系型数据库的范式有六种:第一,二,三,四,五范式和巴斯-科德范式,第五范式成为完美范式
- 各种范式是呈递次规范:也就是后面的范式是在前面的范式满足的情况下,才会有后面的范式.越高范式的数据库冗余度就越来越低
2.前三种范式的介绍
- 第一范式:1NF:默认遵从的,数据库创建出来就符合
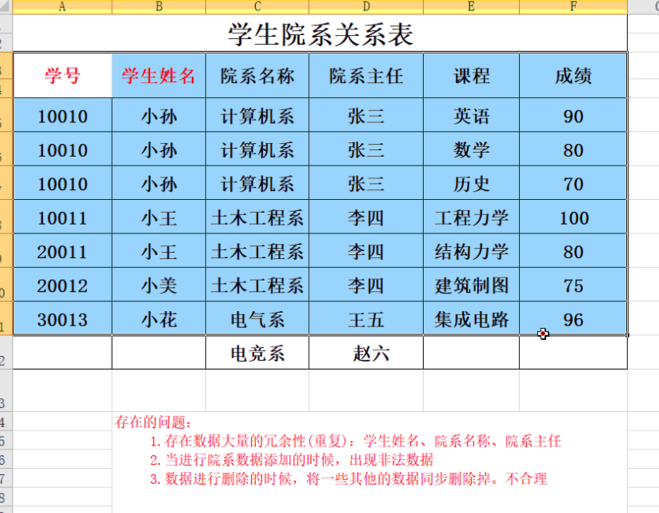
数据库中的每一列不可分割的原子数据项,就是说每一项都是最小的,如果学生信息项=学号+学生姓名 那么学生信息就是可以分割的,那么学生信息项就可以分割,所以不算是第一范式
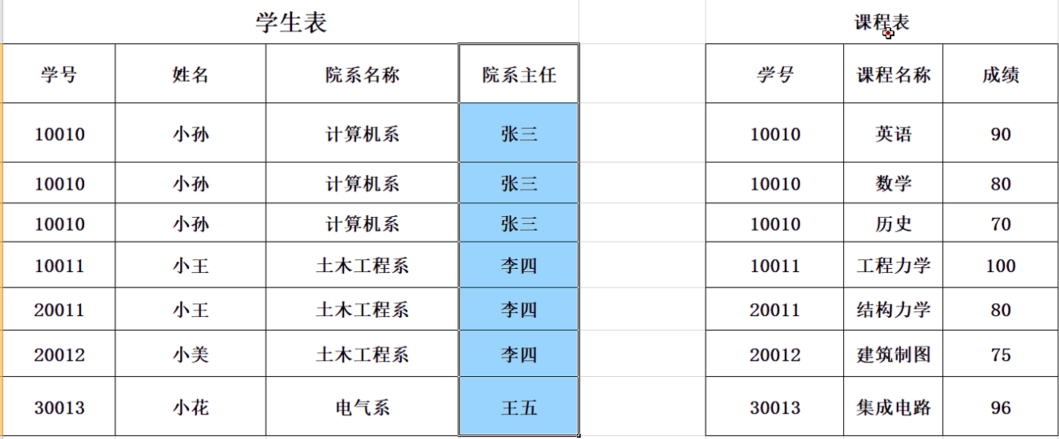
- 第二范式:2NF:在第一范式的基础之上,非码属性必须完全依赖于码,在第一范式基础上消除非主属性对主属性的部分函数对码依赖,就比如说:一张表主属性学号就可以确定学生了,后面的主属性课程只是后面确定成绩会用到,对学生的确定无关,所以就造成了冗余,把课程和成绩从原表中分离出去,剩下的才符合第二范式.分离出去的必须要学号和课程联合才能确定成绩,所以说分离出去的需要关联学号
概念:
- 函数依赖:A--->B 如果通过A属性的值,可以确定唯一的B属性值,可以称B依赖于A,,,,,就相当于通过学号可以找到学生-->学生就依赖于学号.
- 完全函数依赖:A--->B 如果A是一个属性组,则B属性值的确定需要依赖于A属性组中所有的属性值,就相当于学号-->课程---->每个课程的成绩,就会成绩的的确定需要依赖于学号中所有的课程才能得到
- 部分函数依赖:A--->B B属性的确定需要依赖于,A数学组中一个或者部分的数据才能得到
- 传递函数依赖: A--->B ,B--->C如果通过A属性组的值可以唯一确定B属性组属性的值,再通过B属性的值可以唯一确定C属性的值,这时候就可以称C传递函数依赖于A.
- 码:如果在一张表中,一个属性或者属性组,被其他所有属性锁完全依赖,则称这个属性为该表的码.
主属性:码属性组中的所有属性
非主属性:除了主属性之外的其他属性.
第三范式:3NF :如上图所示,还是有很多冗余,比如一个学号对应姓名多次,就没有得到优化,到了第三范式基本上都是单独的表在表决心单独的删除和增加并不会说影响其他表的数据,就大大避免了操作失误.任何非主属性不依赖于其他的非主属性(消除传递函数依赖)
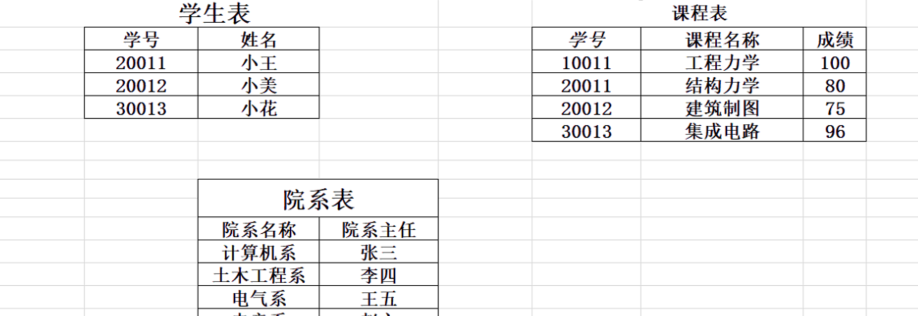
三种范式总结:
- 第一范式(1NF):表中每一列不可分割(一件事最小状态)
- 第二范式(2NF):消除部分函数依赖:一张表只做一件事学生表就描述学生信息,不要再去说成绩
- 第三范式(3NF):消除传递函数依赖,表中每一列都直接依赖于码(主键),非主键和非主键之间没有联系.,中间不需要传递,直接找主键
多表连接查询
分类:内连接(显示内连接和隐式内连接)和外连接(左外连接和右外连接).
-
笛卡尔现象:
- 左表中的每条记录和右表中的每条数据都会产生关联,这种效果就称之为笛卡尔集合
-
消除笛卡尔先行
-
内连接::inner join(可以不写)
- 隐式内连接:就是省略了内连接关键字 inner join
语法:select 字段列表 from 表名1,表名2 where 条件语句 --->不写where就会出现笛卡尔现象
- 显示内连接:
语法: select 字段列表 from 表名1 inner join 表名2 on 条件语句
- 总结:
内连接是运用所有的笛卡尔把所有的都连接起来,所以要在后面加上where条件才能输出准确的数据
- 确定查询哪些表
- 确定表关联的条件
- 使用连接的方式(内还是外)
- 确定查询的字段信息 尽量少用

-
外连接
- 左外连接:使用 left [outer] join......on 条件语句 -----> outer(可以省略)
- select 字段列表 from 左表(以左表为主) left join 右表(辅助的表) on 条件语句(关联语句)
- 注意事项 :是用左表中的记录数据去匹配右表中的记录数据,如果符合条件则显示不符合的就插入null,用来保证左表中的数据全部显示.
- 右外连接:使用 right join
- select 字段列表 from 右表(以左表为主) right join 左表(辅助的表) on 条件语句(关联语句)
- 注意事项 :是用右表中的记录数据去匹配左表中的记录数据,如果符合条件则显示不符合的就插入null,用来保证右表中的数据全部显示
-
子查询
- 一个查询的结果是另一个查询的条件,形成查询嵌套,里面被嵌套的查询称之为子查询
- 子查询三种情况
- 子查询的结果可以是单行单列(一个值)
- 也可以是多行单列,一个字段,这个字段有多个值
- 也可以是多行多列,结果值有多个字段,多个值
- 操作:
- 单行单列查询结果
- select 查询字段列表 from 表名 where 字段 比较运算符 (子查询)
- 多行多列:一般能情况下,作为一张虚拟表,进行关联二次查询,一般需要给这个虚拟表一个别名来实现
- 语法:select 查询字段列表 from 表名,(子查询) as 新表名 where 条件语句;
- 特征:多行多列不能再使用in运算符或者比较运算符,而是需要继续多表关联,给查询出来的多行多列起别名.
- 总结:
- 单行多列:只有一个值,where后面可以使用比较运算符作为条件
- 多行单列:是一个集合值或者数组值,在where后面使用in运算符作为条件
- 多行多列:大多数多列结果值是放在from后面的,作为多表关联的,可以进行二次条件过滤
事务
.概念
- ? 一个业务操作中,要么操作成功,要么被撤销,这个业务操作是一个整体操作不是一个单独的操作.在这个整体中,所有的sql语句要么全部执行成功,要么回滚,回滚就意味着业务执行失败,
- ? 操作:张三给李四转钱10000 两步:1.张三减少10000 2.李四增加10000
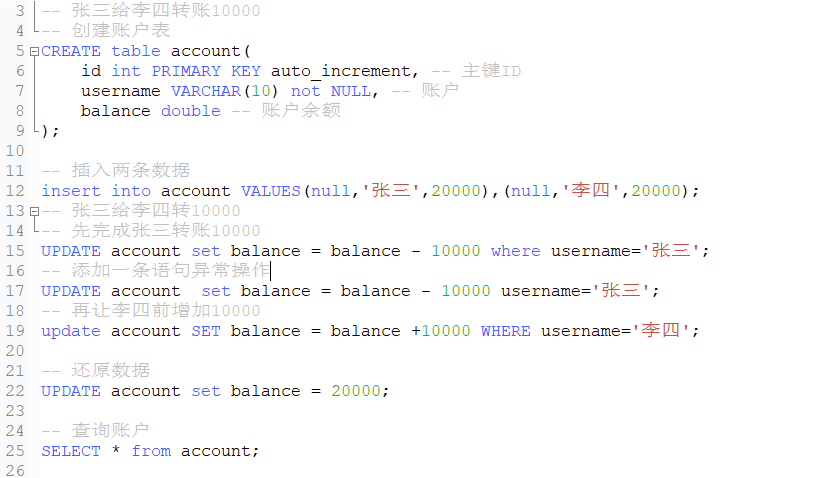
开启事物: satrt transaction ;开启事物,那么后面的sql操作就会不会修改数据库中的数据
提交事物:commit;提交提交事务使得它能改变数据库中的数据
回滚事务:rollbank;在sql语句有错误的时候就不会提交事务,会回滚事务,把数据还原
事务的四大特性:
- 原子性:事务是一个整体,在整体中是不可分割的,就是许多sql语句不可以分开,必须同时指向,意思就是要么完全成功要么完全失败.
- 一致性:事务在执行前和执行后,数据库中的数据状态是一致的.转账前是40000,那么到最后总的钱就是40000,是不会改变的
- 隔离性:一个事务的执行不能被其他事务干扰。
- 持续性/永久性:一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
事务的隔离级别:
-
读未提交-->read uncommited
-
读已提交:-->read commited
-
可重复读---->repeatable read
-
窜行话--->serialzable0 锁表(一般不用,安全性最高,性能最低).
-
由事务隔离级别引发并发事务操作问题:脏读,不可重复读,幻读
2021.1.5.- 外键约束 - 数据库与表之间的关系 - 三大范式 - 多表查询 - 事务 - DCL
原文:https://www.cnblogs.com/tushao/p/14243316.html