背景:
DL训练框架采用Pytorch,推理框架使用Caffe,模型使用的是基于Facebook新出的MaskRCNN改进版,主要使用ADAS的视觉感知,包括OD,车道线,语义分割等网络。
整体框架:

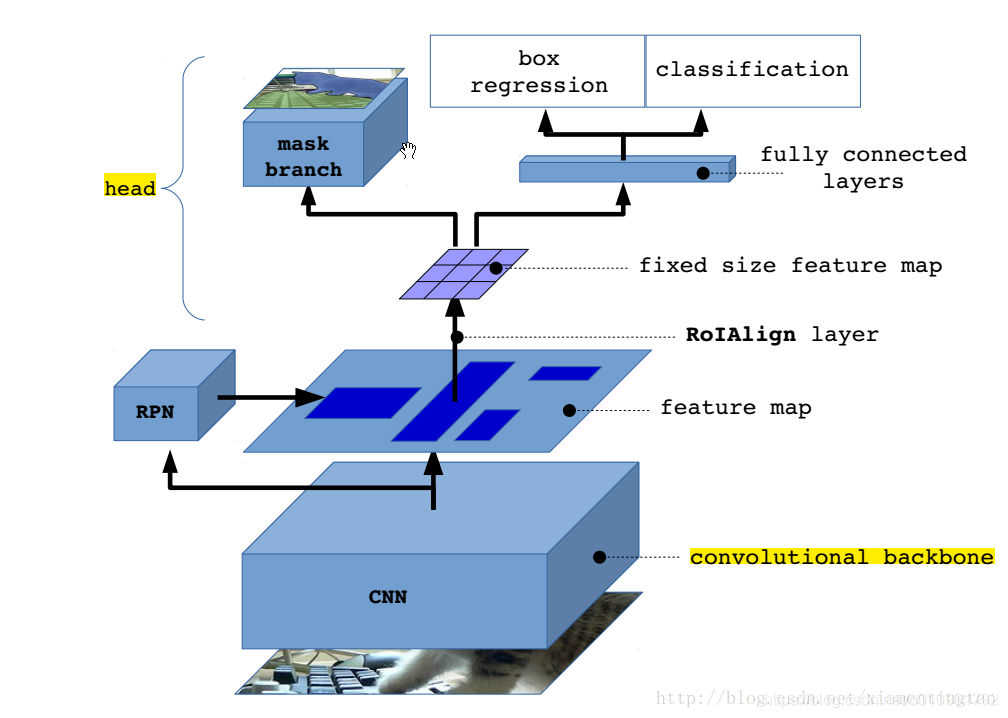
? 图1 Mask R-CNN整体架构
Mask R-CNN是一个非常灵活的框架,可以增加新的分支完成不同任务,如:目标分类、目标检测、语义分割、实例分割、人体姿势识别等多种任务。框架延续Faster-RCNN,在基础特征网络后加入了全连接的分割子网,由原来两个任务变为三个任务,采用和Faster-RCNN相同的两个阶段。
第一阶段有相同的层(RPN),扫描图像生成提议框(proposals,可能包含目标的区域)
第二阶段除分类和bbox回归外,又添加了一个全卷积网络分支,对每个ROI预测对应二值掩码(binary mask),决定像素是否是目标一部分。(所谓掩码,就是当像素属于目标所在位置时标识为1,否则为0)。从而将任务简化为多阶段,解耦多个子任务。
流程如下:
一、输入一张图片,进行相应预处理;
二、将其输入到预训练好的神经网络中,获得对应的feature map;
三、对该feature map中的每个点设定预定好数量的ROI,从而获得多个候选ROI;
四、将这些候选ROI送入RPN网络进行二值分类(前景或背景)和BBOX回归,过滤掉一些候选的ROI;
五、对这些剩下的ROI进行ROIAlign操作;
六、对这些ROI进行分类(N类别分类),BBOX回归和MASK生成(在每个ROI里面进行FCN操作)
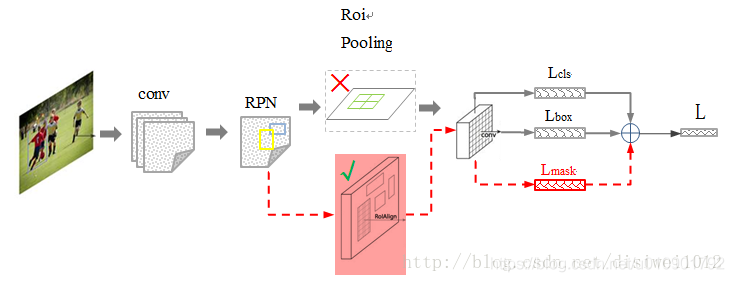
其中虚框里为FasterRCNN部分,下方红框为Maskrcnn新修改部分。
新增部分:
1、ResNet+FPN
替换了VGG网络,转而使用特征表达能力更强的残差网络,为了挖掘多尺度,还使用了FPN结构;
2、将RoI pooling替换为RoiAlign
解决misalign问题,就是对feature map的插值,roi pooling出来会与实际物体有微小偏移;
3、添加并列的FCN层(mask层)
用于语义分割的全卷积网络
架构分解:
一、主干网
采用了深度残差网络,太深的网络会训练效果会退化,Resnet使用了跨层连接,使训练更容易
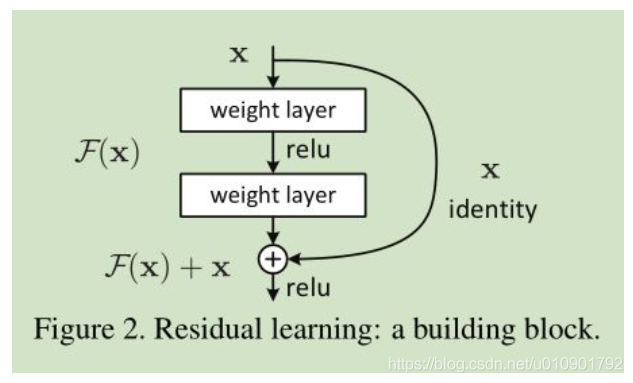
网络输出f(x)+x,网络特别深时残差会趋近于0,从而实现了恒等变换。
采用了两种卷积:跳过三个卷积的identity block和跳过三个卷积并在shortcut上存在卷积的conv block,第三个卷积层与shortcut上在卷积都没激活,而是先相加再激活。
采用1x1的卷积实现降维从而加带卷积运算。
Resnet101分为5个阶段,,这些输出后会接FPN。
二、FPN
为了实现更好的特征整合,最后一层语义强,但位置信息和分辨率较低,容易检测不到小物体,FPN功能就是融合底层到高层的feature map,从而充分利用了提取到的各阶段的特征。
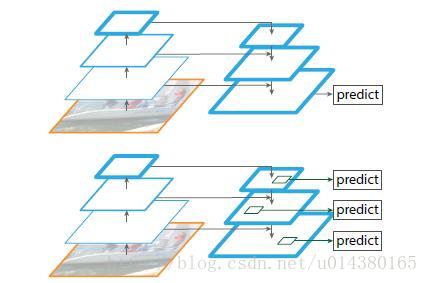
采用了top-down的结构和横向连接,以此融合具有高分辨率的浅层layer和具有丰富语义信息的深层layer,从而实现了从单尺度的输入图像上,快速构建在所有尺度上都具有强语义信息的特征金字塔,同时并不产生明显的开销。
FPN是一个窗口大小固定的滑动窗口检测器,在不同的层滑动可以增加其对尺度变化的鲁棒性。
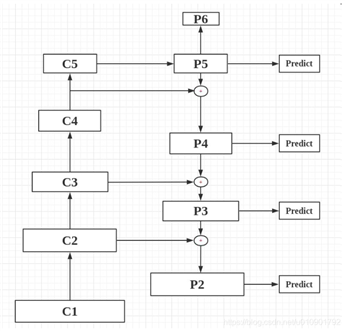
FPN特征融合图
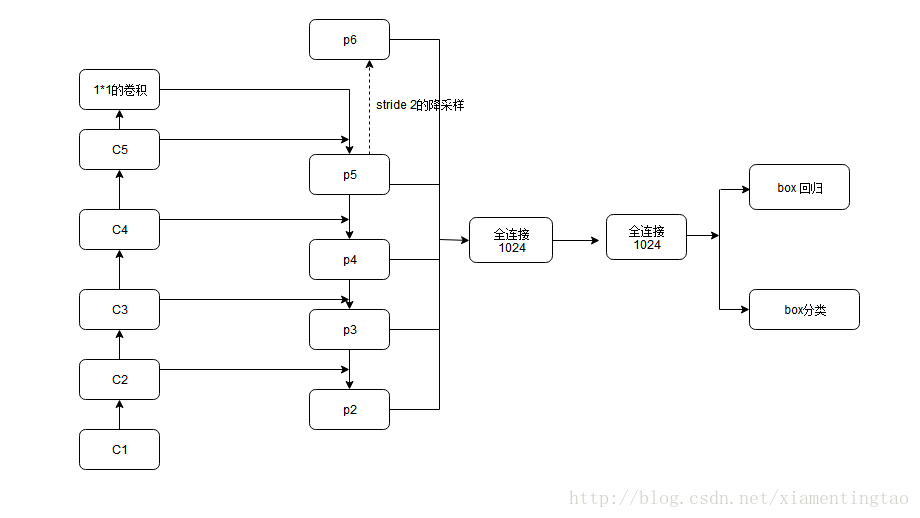
残差模块输出层{C2,C3,C4,C5},对应融合特征层为{P2,P3,P4,P5},对应层间尺寸是相同的。
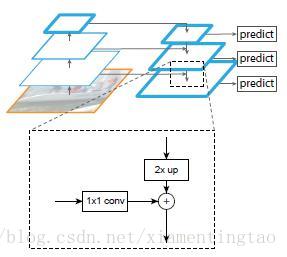
高层做2倍上采样(最邻近上采样,可以参考反卷积),然后与对应的前一层特征结合,前一层要经过1x1卷积,改变通道数,再做像素间加法。
最后采用3x3卷积去处理已经融合好的特征图,是为了消除上采样的混叠效应。
使用P2-P5来预测物体bbox,而P2-P6是用于训练RPN的,即P6只用于RPN中。
三、RPN
RPN是用于区域选择的子网络,在FasterRCNN中,是在13x13x256的特征图上应用9咱不同尺度的anchor。而MaskRCNN,把特征图设置成多尺度的,然后固定每种特征图对应的anchor尺寸,即{P2,P3,P4,P5,P6}分别对应的anchor尺度为{32^2,64^2, 128^2, 256^2, 512^2 },当然目标不可能都是正方形,所以采用了三个比例:{1:2, 1:1, 2:1},所以金字塔结构中共有15种anchors。
RPN结构如下:
 各阶层共享后面的分类网络,所以输出通道数要保持一致。
各阶层共享后面的分类网络,所以输出通道数要保持一致。
正负样本的界定:
如果某个anchor和一个给定的ground truth有最高的IOU或者和任意一个Ground truth的IOU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IOU都小于0.3,则为负样本。
四、ROIAlign
ROI Pooling为了得到固定大小(7X7)的feature map,我们需要做两次量化操作:
1)图像坐标 — feature map坐标,
2)feature map坐标 — ROI feature坐标。
做segment是pixel级别的,但是faster rcnn中roi pooling有2次量化操作导致了没有对齐 .
例:我们输入的是一张800x800的图像,在图像中有两个目标(猫和狗),狗的BB大小为665x665,经过VGG16网络后,我们可以获得对应的feature map,如果我们对卷积层进行Padding操作,我们的图片经过卷积层后保持原来的大小,但是由于池化层的存在,我们最终获得feature map 会比原图缩小一定的比例,这和Pooling层的个数和大小有关。在该VGG16中,我们使用了5个池化操作,每个池化操作都是2Pooling,因此我们最终获得feature map的大小为800/32 x 800/32 = 25x25(是整数),但是将狗的BB对应到feature map上面,我们得到的结果是665/32 x 665/32 = 20.78 x 20.78,结果是浮点数,含有小数,但是我们的像素值可没有小数,那么作者就对其进行了量化操作(即取整操作),即其结果变为20 x 20,在这里引入了第一次的量化误差;然而我们的feature map中有不同大小的ROI,但是我们后面的网络却要求我们有固定的输入,因此,我们需要将不同大小的ROI转化为固定的ROI feature,在这里使用的是7x7的ROI feature,那么我们需要将20 x 20的ROI映射成7 x 7的ROI feature,其结果是 20 /7 x 20/7 = 2.86 x 2.86,同样是浮点数,含有小数点,我们采取同样的操作对其进行取整吧,在这里引入了第二次量化误差。其实,这里引入的误差会导致图像中的像素和特征中的像素的偏差,即将feature空间的ROI对应到原图上面会出现很大的偏差。原因如下:比如用我们第二次引入的误差来分析,本来是2.86,我们将其量化为2,这期间引入了0.86的误差,看起来是一个很小的误差呀,但是你要记得这是在feature空间,我们的feature空间和图像空间是有比例关系的,在这里是1:32,那么对应到原图上面的差距就是0.86 x 32 = 27.52。这个差距不小吧,这还是仅仅考虑了第二次的量化误差。这会大大影响整个检测算法的性能
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法(如上图)。ROI Align的思路很简单:取消量化操作,使用双线性插值的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。如下图所示:
蓝色的虚线框表示卷积后获得的feature map,黑色实线框表示ROI feature,最后需要输出的大小是2x2,那么我们就利用双线性插值来估计这些蓝点(虚拟坐标点,又称双线性插值的网格点)处所对应的像素值,最后得到相应的输出。这些蓝点是2x2Cell中的随机采样的普通点,作者指出,这些采样点的个数和位置不会对性能产生很大的影响,你也可以用其它的方法获得。然后在每一个橘红色的区域里面进行max pooling或者average pooling操作,获得最终2x2的输出结果。我们的整个过程中没有用到量化操作,没有引入误差,即原图中的像素和feature map中的像素是完全对齐的,没有偏差,这不仅会提高检测的精度,同时也会有利于实例分割。

? 双线性插值
遍历每一个候选区域,保持浮点数边界不做量化。
将候选区域分割成k x k个单元,每个单元的边界也不做量化。
在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。
事实上,ROI Align 在遍历取样点的数量上没有ROIPooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。值得一提的是,我在实验时发现,ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。经过分析,造成这种区别的原因是COCO上小目标的数量更多,而小目标受misalignment问题的影响更大(比如,同样是0.5个像素点的偏差,对于较大的目标而言显得微不足道,但是对于小目标,误差的影响就要高很多)。

? ROIAlign技术
如图所示,为了得到为了得到固定大小(7X7)的feature map,ROIAlign技术并没有使用量化操作,即我们不想引入量化误差,比如665 / 32 = 20.78,我们就用20.78,不用什么20来替代它,比如20.78 / 7 = 2.97,我们就用2.97,而不用2来代替它。这就是ROIAlign的初衷。那么我们如何处理这些浮点数呢,我们的解决思路是使用“双线性插值”算法。双线性插值是一种比较好的图像缩放算法,它充分的利用了原图中虚拟点(比如20.56这个浮点数,像素位置都是整数值,没有浮点值)四周的四个真实存在的像素值来共同决定目标图中的一个像素值,即可以将20.56这个虚拟的位置点对应的像素值估计出来。
roi-align总结:
对于每个roi,映射之后坐标保持浮点数,在此基础上再平均切分成k*k个bin,这个时候也保持浮点数。再把每个bin平均分成4个小的空间(bin中更小的bin),然后计算每个更小的bin的中心点的像素点对应的概率值。这个像素点大概率是一个浮点数,实际上图像的浮点是没有像素值的,但这里假设这个浮点数的位置存储一个概率值,这个值由相邻最近的整数像素点存储的概率值经过双线性插值得到,其实也就是根据这个中心点所在的像素值找到所在的大bin对应的4个整数像素存储的值,然后乘以多个参数进行插值。这些参数其实就是那4个整数像素点和中心点的位置距离关系构成参数。最后再在每个大bin中对4个中心点进行max或者mean的pooling。

其实就是对每个格子再次划分四个格子,进行四次采样,每次采样的位置都是四个格子的中心点,由于我知道了它的位置,但是不知道这个中心点位置的具体像素值是多少,所以采用双线性插值法求这个中心点位置的具体像素(利用它周围位置的像素点求),然后对着四个位置的像素值取最大值,得到这个大格子的输出。
原文:https://www.cnblogs.com/jimchen1218/p/14244011.html