这里我们还是基于之前ceph-deploy部署的环境进行测试。直接的部署参考链接:https://www.cnblogs.com/qingbaizhinian/p/14011475.html#_label1_3
之前机器环境参考下面的截图

之前在介绍ceph资源划分和存储过程描述的时候,没有介绍存储池的概念,这边我们来介绍一下
Ceph 存储系统支持“池”概念,它是存储对象的逻辑分区。
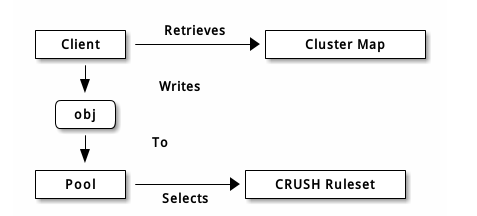
Ceph 客户端从监视器获取一张集群运行图(集群内的所有监视器、 OSD 、和元数据服务器节点分布情况),并把对象写入存储池poll。存储池的 size 或副本数、 CRUSH 规则集和归置组数量决定着 Ceph 如何放置数据。
存储池至少可设置以下参数:
如果你开始部署集群时没有创建存储池, Ceph 会用默认存储池存数据。存储池提供的功能:
要把数据组织到存储池里,你可以列出、创建、删除存储池,也可以查看每个存储池的利用率。
每个存储池都有很多归置组, CRUSH 动态的把它们映射到 OSD 。 Ceph 客户端要存对象时, CRUSH 将把各对象映射到某个归置组。
把对象映射到归置组在 OSD 和客户端间创建了一个间接层。由于 Ceph 集群必须能增大或缩小、并动态地重均衡。如果让客户端“知道”哪个 OSD 有哪个对象,就会导致客户端和 OSD 紧耦合;相反, CRUSH 算法把对象映射到归置组、然后再把各归置组映射到一或多个 OSD ,这一间接层可以让 Ceph 在 OSD 守护进程和底层设备上线时动态地重均衡。下列图表描述了 CRUSH 如何将对象映射到归置组、再把归置组映射到 OSD 。
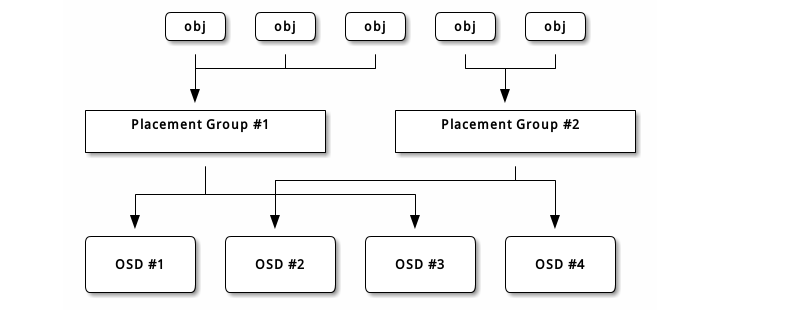
有了集群运行图副本和 CRUSH 算法,客户端就能精确地计算出到哪个 OSD 读、写某特定对象。
在生产中,一个Pool里设置的PG数量是预先设置的,PG的数量不是随意设置,需要根据OSD的个数及副本策略来确定,线上尽量不要更改PG的数量,PG的数量的变更将导致整个集群动起来(各个OSD之间copy数据),大量数据均衡期间读写性能下降严重;
预先规划Pool的规模,设置PG数量;一旦设置之后就不再变更;后续需要扩容就以 Pool 为维度为扩容,通过新增Pool来实现(Pool通过 crushmap实现故障域隔离);
#列出集群中的存储池,在新安装好的集群上,只有一个 rbd 存储池。但是ceph-deploy安装的没有创建创建存储池 [root@ceph-deploy ~]# ceph osd lspools
1.安装ceph客户端
Ceph块设备,以前称为RADOS块设备,为客户机提供可靠的、分布式的和高性能的块存储磁盘。RADOS块设备利用librbd库并以顺序的形式在Ceph集群中的多个osd上存储数据块。RBD是由Ceph的RADOS层支持的,因此每个块设备都分布在多个Ceph节点上,提供了高性能和优异的可靠性。RBD有Linux内核的本地支持,这意味着RBD驱动程序从过去几年就与Linux内核集成得很好。除了可靠性和性能之外,RBD还提供了企业特性,例如完整和增量快照、瘦配置、写时复制克隆、动态调整大小等等。RBD还支持内存缓存,这大大提高了其性能:
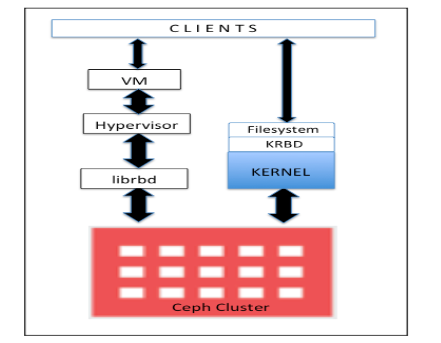
任何普通的Linux主机(RHEL或基于debian的)都可以充当Ceph客户机。客户端通过网络与Ceph存储集群交互以存储或检索用户数据。CephRBD支持已经添加到Linux主线内核中,从2.6.34和以后的版本开始
原文:https://www.cnblogs.com/qingbaizhinian/p/14252878.html