用法:
re.compile() 用于编译正则表达式,生成一个正则表达式模式对象,具有各种操作的方法。re.compile(pattern, flags=0)
示例:
>>> import re
>>> p = re.compile(r‘ab*‘)
>>> p
re.compile(r‘ab*‘)
>>> dir(p)
[‘__class__‘, ‘__copy__‘, ‘__deepcopy__‘, ‘__delattr__‘, ‘__dir__‘, ‘__doc__‘, ‘__eq__‘, ‘__format__‘, ‘__ge__‘, ‘__getattribute__‘, ‘__gt__‘, ‘__hash__‘, ‘__init__‘, ‘__init_subclass__‘, ‘__le__‘, ‘__lt__‘, ‘__ne__‘, ‘__new__‘, ‘__reduce__‘, ‘__reduce_ex__‘, ‘__repr__‘, ‘__setattr__‘, ‘__sizeof__‘, ‘__str__‘, ‘__subclasshook__‘, ‘findall‘, ‘finditer‘, ‘flags‘, ‘fullmatch‘, ‘groupindex‘, ‘groups‘, ‘match‘, ‘pattern‘, ‘scanner‘, ‘search‘, ‘split‘, ‘sub‘, ‘subn‘]能够看到编译成正则表达式对象后,提供了很多的方法来进行匹配操作。
用法:
re.match() 从字符串的起始位置匹配,如果起始位置匹配不成功,则 match() 就返回 none。如果匹配成功,则可通过 group(num) 或 groups()获取匹配结果。re.match(pattern, string, flags=0)
示例:
>>> import re
>>> p = re.compile(r‘[a-z]+‘)
>>> m = p.match(‘123abc‘)
>>> m
>>> print(m)
None
>>>
>>> m = p.match(‘abc‘)
>>> m
<_sre.SRE_Match object; span=(0, 3), match=‘abc‘>
>>> print(m)
<_sre.SRE_Match object; span=(0, 3), match=‘abc‘>
>>> m.group()
‘abc‘
>>> m.start()
0
>>> m.end()
3
>>> m.span()
(0, 3)说明:
group():返回匹配的结果
start():返回匹配开始的位置
end():返回匹配结果的位置
span():返回匹配(开始,结束)位置的元组
用法:
re.search() 对整个字符串进行匹配并返回第一个成功的匹配字符串,否则返回 Nonere.search(pattern, string, flags=0)
示例:
>>> import re
>>> p = re.compile(r‘[a-z]+‘)
>>> s = p.search(‘123abc‘)
>>> print(s)
<_sre.SRE_Match object; span=(3, 6), match=‘abc‘>
>>> s.group()
‘abc‘用法:
在字符串中匹配所有满足正则表达式的字符串,并返回一个列表,如果没有找到匹配的,则返回空列表。re.findall(pattern, string, flags=0)
示例:
>>> import re
>>> p = re.compile(r‘\d+‘)
>>> p.findall(‘12a34b56c‘)
[‘12‘, ‘34‘, ‘56‘]用法:
在字符串中匹配所有满足正则表达式的字符串,但 finditer 把它们作为一个迭代器返回。finditer(pattern, string, flags=0)
示例:
>>> import re
>>> re.compile(r‘1a2b3c‘)
re.compile(‘1a2b3c‘)
>>> p = re.compile(r‘\d+‘)
>>> p.finditer(‘12a34b56c‘)
<callable_iterator object at 0x7f168613bdd8>
>>> for m in p.finditer(‘12a34b56c‘):
... print(m.group(), m.span())
...
12 (0, 2)
34 (3, 5)
56 (6, 8)用法:
re.sub() 用于替换字符串中的匹配项。
re.subn() 与 re.sub() 基本一样,不同的是它返回的是一个元组,包含新的字符串和替换次数re.sub(pattern, repl, string, count=0, flags=0)
re.sub() 参数的解释如下:
pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
示例一:
>>> import re
>>> re.sub(r‘[a-z]+‘, ‘456‘, ‘abc123‘)
‘456123‘
>>>
>>> p = re.compile(r‘[a-z]+‘)
>>> p.sub(‘456‘, ‘abc123‘)
‘456123‘示例二:
>>> import re
>>> p = re.compile(r‘[a-z]+‘)
>>> p.sub(‘456‘, ‘abc123‘)
‘456123‘
>>>
>>> p.subn(‘456‘, ‘abc123‘)
(‘456123‘, 1)
>>> p.subn(‘456‘, ‘abc123abc‘)
(‘456123456‘, 2)用法:
re.split() 方法按正则表达式的匹配拆分字符串。如果在RE中使用捕获括号,则它们的内容也将作为结果列表的一部分返回。re.split(pattern, string, maxsplit=0, flags=0)
re.split() 参数解释如下:
pattern : 正则表达式
string : 字符串
maxsplit : 显示分隔的次数,默认为0,不限制分割次数。
flags : 标志位
示例:
>>> import re
>>> p = re.compile(r‘\W+‘)
>>> p.split(‘This is a test‘)
[‘This‘, ‘is‘, ‘a‘, ‘test‘]
>>> p.split(‘This is a test‘, maxsplit=1)
[‘This‘, ‘is a test‘]flag即标志位,主要是用于控制正则表达式的匹配方式。分别如下:
re.I(全拼:IGNORECASE): 忽略大小写。
re.M(全拼:MULTILINE): 多行模式,改变 ^ 和 $ 的行为。
re.S(全拼:DOTALL): . 能匹配包含换行符在内的任意字符。
re.L(全拼:LOCALE): 使预定字符类 \w \W \b \B \s \S 取决于当前区域设定。
re.U(全拼:UNICODE): 使预定字符类 \w \W \b \B \s \S \d \D 取决于 unicode 定义的字符属性。
re.X(全拼:VERBOSE): 详细模式,主要是提高正则表达式的可读性。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。
re.S 示例:
>>> import re
>>> re_str = ‘This is the first test.\nThis is the second test.‘
>>> p = re.compile(r‘This.*test‘)
>>> p.match(re_str).group()
‘This is the first test‘
>>>
>>>
>>> re_str = ‘This is the first test.\nThis is the second test.‘
>>> p = re.compile(r‘This.*test‘, re.S)
>>> p.match(re_str).group()
‘This is the first test.\nThis is the second test‘re.M 示例:
>>> import re
>>> re_str = ‘This is the first test.\nThis is the second test.‘
This is the first test.
This is the second test.
>>> p = re.compile(r‘^This.*?test\.$‘)
>>> p.findall(re_str)
[]
>>> p = re.compile(r‘^This.*?test\.$‘,re.S)
>>> p.findall(re_str)
[‘This is the first test.\nThis is the second test.‘]
>>>
>>> p = re.compile(r‘^This.*?test\.$‘,re.M)
>>> p.findall(re_str)
[‘This is the first test.‘, ‘This is the second test.‘]从上面的示例中能看到在没有使用 re.M 前, ^ 和 $ 是把整个字符串一次性匹配,在引入 re.M 多行模式后,会把每一行看做单个字符串,逐行用 ^ 和 $ 匹配。
示例:
>>> import re
>>> p = re.compile(r‘[a-z]+‘)
>>> p.match(‘123abc‘)
>>> m = p.match(‘123abc‘)
>>> print(m)
None
>>> s = p.search(‘123abc‘)
>>> print(s)
<_sre.SRE_Match object; span=(3, 6), match=‘abc‘>
>>> s.group()
‘abc‘通过上面的示例可以看到,match() 函数是从字符串开始处匹配,如果起始位置匹配不成功,则 match() 就返回 none,匹配成功,则返回匹配对象,而 search() 则是扫描整个字符串。search() 将扫描整个字符串,并返回它第一个匹配对象。通常 search() 比 match() 更适用。
先通过以下几个简单的示例,来区分一下 group 与 groups 有何不同。
示例一:
>>> import re
>>> p = re.compile(r‘ab‘)
>>> s = p.search(‘abcd‘)
>>> s.group()
‘ab‘
>>> s.groups()
()示例二:
>>> import re
>>> p = re.compile(r‘(a)b‘)
>>> s = p.search(‘abcd‘)
>>> s.group()
‘ab‘
>>> s.group(0)
‘ab‘
>>> s.group(1)
‘a‘
>>> s.groups()
(‘a‘,)示例三:
>>> import re
>>> p = re.compile(r‘(a(b)c)d‘)
>>> s = p.search(‘abcd‘)
>>> s.group()
‘abcd‘
>>> s.group(0)
‘abcd‘
>>> s.group(1)
‘abc‘
>>> s.group(2)
‘b‘
>>> s.groups()
(‘abc‘, ‘b‘)从上面三个示例可以看出,group() 可以对匹配的正则表达式进行分组,组的编号默认从 0 开始,0 是匹配整体。groups() 是默认会返回一个元组,元组中的元素是匹配到的每个小括号中的内容。
另外从示例三中可以看到,分组也可以嵌套使用。
捕获组和非捕获组区别:
捕获组用()作为分组,并对分组中进行匹配并捕获匹配的内容。
非捕获组也是使用()作为分组,只是括号内的格式为 (?:pattern),非捕获组参与匹配但是不捕获匹配的内容,这样的分组就叫非捕获组。
通过以下两个示例进一步理解非捕获组:
示例一:
>>> m = re.match(r"([abc])+", "abc")
>>> m.groups()
(‘c‘,)
>>> m = re.match(r"(?:[abc])+", "abc")
>>> m.groups()
()示例二:
>>> import re
>>> p = re.compile(r‘industr(y|ies)‘)
>>> s = p.search(‘industry‘)
>>> s.group()
‘industry‘
>>> s.groups()
(‘y‘,)
>>>
>>> p = re.compile(r‘industr(?:y|ies)‘)
>>> s = p.search(‘industry‘)
>>> s.group()
‘industry‘
>>> s.groups()
()通过实例二能够明显看到,在使用分组的时候,s.groups() 是能够捕获到匹配的内容,但分组设置为非捕获组后,非捕获组仍参与匹配,只是groups() 并没有捕获分组中匹配的内容。
命令组定义:(?P<name>pattern)
命名组的行为与捕获组完全相同,并且还将命名组的名称与对应组相关联。
示例一:
>>> p = re.compile(r‘(?P<word>\b\w+\b)‘)
>>> m = p.search(‘Lots of punctuation‘)
>>> m.group(‘word‘)
‘Lots‘
>>> m.group(1)
‘Lots‘示例一中,定义了一个命名组叫做 word ,使用 search() 方法匹配一个单词后返回结果。
示例二:
>>> p = re.compile(r‘\b(?P<word>\w+)\s+(?P=word)\b‘)
>>> p.search(‘Paris in the the spring‘).group()
‘the the‘
>>> p = re.compile(r‘\b(?P<word>\w+)\s+(\1)\b‘)
>>> p.search(‘Paris in the the spring‘).group()
‘the the‘示例二中,分别使用了命名组和组编号引用的第一个()中的内容。
re.sub() 方法结合分组来匹配替换
>>> import re
>>> p = re.compile(r‘(hello)\s(abc)\s(123)‘)
>>> p.sub(‘\\1\\2‘, ‘hello abc 123‘)
‘helloabc‘
>>> p.sub(‘\\1‘, ‘hello abc 123‘)
‘hello‘
>>> p.sub(‘\\2‘, ‘hello abc 123‘)
‘abc‘
>>> p.sub(‘\\3‘, ‘hello abc 123‘)
‘123‘
>>> p.sub(‘\\1\\2‘, ‘hello abc 123‘)
‘helloabc‘
>>> p.sub(‘\\1\\3‘, ‘hello abc 123‘)
‘hello123‘re.sub() 方法结合命名组来匹配替换
>>> import re
>>> p = re.compile(r‘(?P<g1>hello)\s(?P<g2>abc)\s(?P<g3>123)‘)
>>> p.sub(‘\g<g1>‘, ‘hello abc 123‘)
‘hello‘
>>> p.sub(‘\g<g2>‘, ‘hello abc 123‘)
‘abc‘
>>> p.sub(‘\g<g3>‘, ‘hello abc 123‘)
‘123‘
>>> p.sub(‘\g<g1>\g<g2>‘, ‘hello abc 123‘)
‘helloabc‘
>>> p.sub(‘\g<g2>\g<g3>‘, ‘hello abc 123‘)
‘abc123‘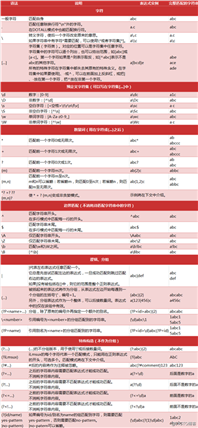
以上涉及到的命令操作环境是 Python 3.6。
参考:
https://docs.python.org/3/howto/regex.html
https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
原文:https://blog.51cto.com/liubin0505star/2585543