1.大数据的概念
维基百科的定义: 大数据是指利用常用软件工具捕获、管理和处理数据所耗时间超过可容忍时间的数据集。
2.大数据主流技术
数据采集:
数据存储与管理:
大数据利用分布式文件系统HDFS、HBase、Hive,实现对结构化、半结构化和非结构化数据的存储和管理。
数据处理与分析:
利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析。
3.场景化解决方案
在面对不同的场景时,会使用不同的大数据组件去解决处理,主要有如下大数据场景化解决方案。
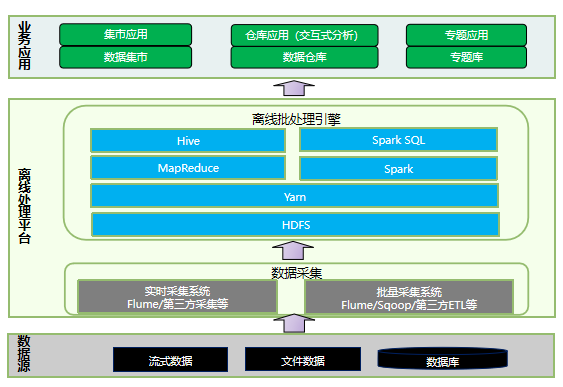
3.1 离线批处理
离线批处理,是指对海量历史数据进处理和分析,生成结果数据,供下一步数据应用使用的过程。离线批处理对数据处理的时延要求不高,但是处理的数据量较大,占用的计算存储资源较多,通常通过MR作业、Spark作业或者HQL作业实现。
离线批处理的特点:
离线处理常用的组件:
HDFS介绍
HDFS(Hadoop Distributed File System)基于Google发布的GFS论文设计开发。 其除具备其它分布式文件系统相同特性外,HDFS还有自己特有的特性:
HDFS适合:大文件存储与访问 流式数据访问
HDFS不适合:大量小文件存储 随机写入 低延迟读取
HDFS回收站机制:
Hive概述
Hive是基于Hadoop的数据仓库软件,可以查询和管理PB级别的分布式数据。
Hive特性:
Hive函数:
查看系统函数的用法:show functions;
显示函数的用法:desc function upper;
详细显示函数的用法:desc function extended upper;
当Hive提供的内置函数无法满足业务处理需要时,此时就可以考虑使用用户自定义函数,编写处理代码并在查询中使用。
Hive调优
数据倾斜
数据倾斜指计算数据的时候,数据的分散度不够,导致大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢。
日常使用过程中,容易造成数据倾斜的原因可以归纳为如下几点:
调优参数:
在map中会做部分聚集操作,效率更高但需要更多的内存。
set hive.map.aggr=true;
此时生成的查询计划会有两个MRJob,可实现数据倾斜时负载均衡。
set hive.groupby.skewindata=true;
当连接一个较小和较大表的时候,把较小的表直接放到内存中去,然后再对较大的表进行map操作。
set hive.auto.convert.join=true;
每个查询会被Hive转化为多个阶段,当有些阶段关联性不大时,可以并行化执行,减少整个任务的执行时间。
开启任务并行执行:
set hive.exec.parallel=true;
设置同一个sql允许并行任务的最大线程数(例如设置为8个):
set hive.exec.parallel.thread.number=8;
数据集市和数据仓库的区别:
数据集市
数据集市(Data Mart) ,也叫数据市场,数据集市就是满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
数据仓库
为满足各类零散分析的需求,通过数据分层和数据模型的方式,并以基于业务和应用的角度将数据进行模块化的存储。
数据仓库分层:
分层的优点:
Spark简介
Spark是基于内存的分布式批处理系统,它把任务拆分,然后分配到多个的CPU上进行处理,处理数据时产生的中间产物(计算结果)存放在内存中,减少了对磁盘的I/O操作,大大的提升了数据的处理速度,在数据处理和数据挖掘方面比较占优势。
Spark应用场景
Spark对比MapReduce
RDD
RDD是分布式弹性数据集,可以理解一个存储数据的数据结构。Spark会把所要操作的数据,加载到RDD上,即RDD所有操作都是基于RDD来进行的。RDD是只读和可分区。要想对RDD进行操作,只能重新生成一个新的RDD。
RDD的存储:
Shuffle
Shuffle 是划分 DAG 中 stage 的标识,同时影响 Spark 执行速度的关键步骤
窄依赖
窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用。 表现为: 一个父RDD的每一个分区对应于一个子RDD分区。
宽依赖
宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用。 表现为: 父RDD的每个分区都被多个子RDD分区使用
Transformation
Transformation是RDD的算子类型,它的返回值还是一个RDD。
Transformation操作属于懒操作(算子),不会真正触发RDD的处理计算。
变换方法的共同点:
例如:map(func),flatMap(func)
Action
Action是RDD的算子,它的返回值不是一个RDD。Action操作是返回结果或者将结果写入存储的操作。Action是Spark应用启动执行的触发动作,得到RDD的相关计算结果或将RDD保存到文件系统中。
SparkConf
SparkConf是用来对Spark进行任务参数配置的对象。 是通过键值对的形式,设置Spark任务执行时所需要的参数。 Spark读取任务参数的优先级是: 代码配置>动态参数>配置文件。
SparkContext
SparkContext是Spark的入口,相当于应用程序的main函数。
SparkContext表示与Spark集群的连接,可用于在该集群上创建RDD,记录计算结果和环境配置等信息。
SparkSession
Spark2.0中引入了SparkSession的概念,为用户提供了一个统一的切入点来使用Spark的各项功能。
封装了SparkConf和SparkContext对象,方便用户使用Spark的各种API。
SparkSQL简介
SparkSQL是Spark用来处理结构化数据的一个模块,可以在Spark应用中直接使用SQL语句对数据进行操作。
SQL语句通过SparkSQL模块解析为RDD执行计划,交给SparkCore执行。
通过SparkSession提交SQL语句。任务像普通Spark应用一样,提交到集群中分布式运行。
JDBC:
DataSet:
SparkSQL使用场景
适合: 结构化数据处理。 对数据处理的实时性要求不高的场景 需要处理PB级的大容量数据。
不适合: 实时数据查询。
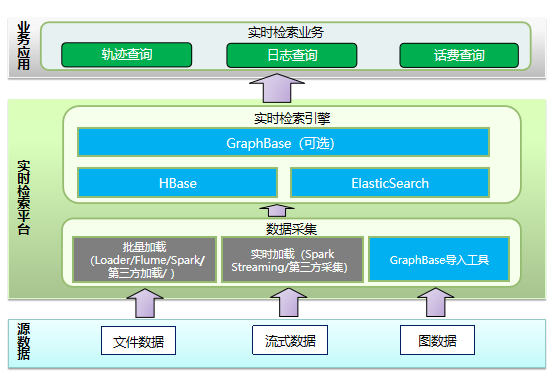
3.2 实时检索
实时检索简而言之就是对系统内的一些信息根据关键词进行即时、快速搜索,实现即搜即得的效果。强调的是实时低延迟。
实时检索的特点:
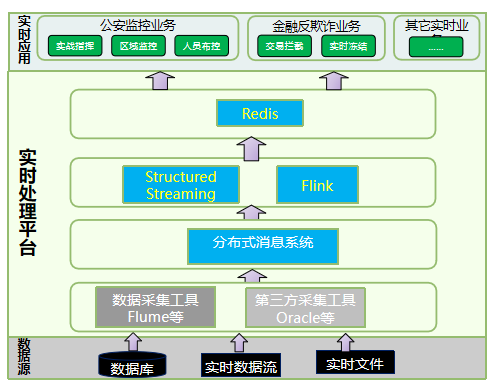
3.3 实时流处理
实时流处理,通常是指对实时数据源进行快速分析,迅速触发下一步动作的场景。实时数据对分析处理速度要求极高,数据处理规模巨大,对CPU和内存要求很高,但是通常数据不落地,对存储量要求不高。实时处理,通常通过Structured Streaming或者Flink任务实现。
实时流处理的特点:
3.4 融合数仓
原文:https://www.cnblogs.com/xiao02fang/p/14253532.html