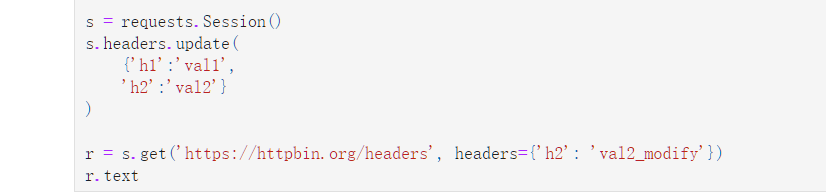
请求头
headers = {
‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.58‘
}
request_params = ‘‘‘
requests 方法 请求参数
? url 请求的URL地址
? params GET请求参数
? data POST请求参数
? json 同样是POST请求参数,要求服务端接收json格式的数据
? headers 请求头字典
? cookies cookies信息(字典或CookieJar)
? files 上传文件
? auth HTTP鉴权信息
? timeout 等待响应时间,单位秒
? allow_redirects 是否允许重定向
? proxies 代理信息
? verify 是否校验证书
? stream 如果为False,则响应内容将直接全部下载
? cert 客户端证书地址
‘‘‘
Response = ‘‘‘
字段
? cookies 返回CookieJar对象
? encoding 报文的编码
? headers 响应头
? history 重定向的历史记录
? status_code 响应状态码,如200
? elaspsed 发送请求到接收响应耗时
? text 解码后的报文主体
? content 字节码,可能在raw的基础上解压
方法
? json() 解析json格式的响应
? iter_content() 需配置stream=True,指定chunk_size大小
? iter_lines() 需配置stream=True,每次返回一行
? raise_for_status() 400-500之间将抛出异常
? close()
‘‘‘
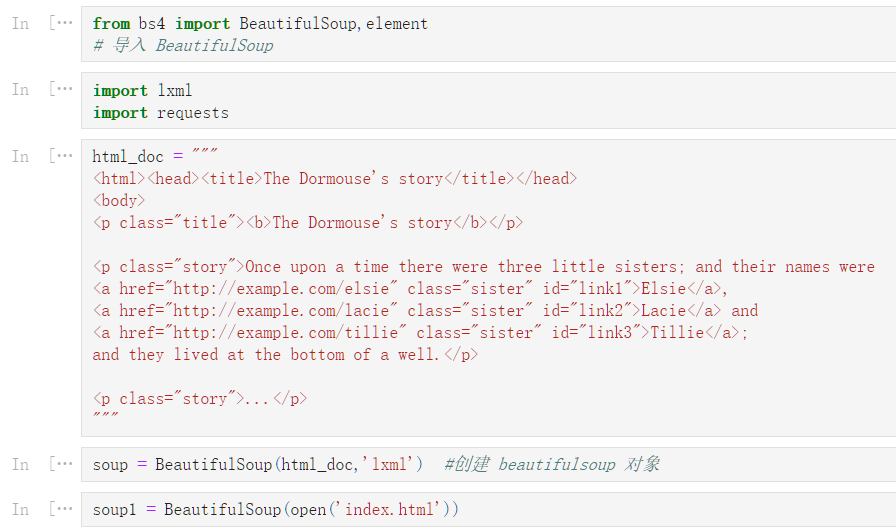
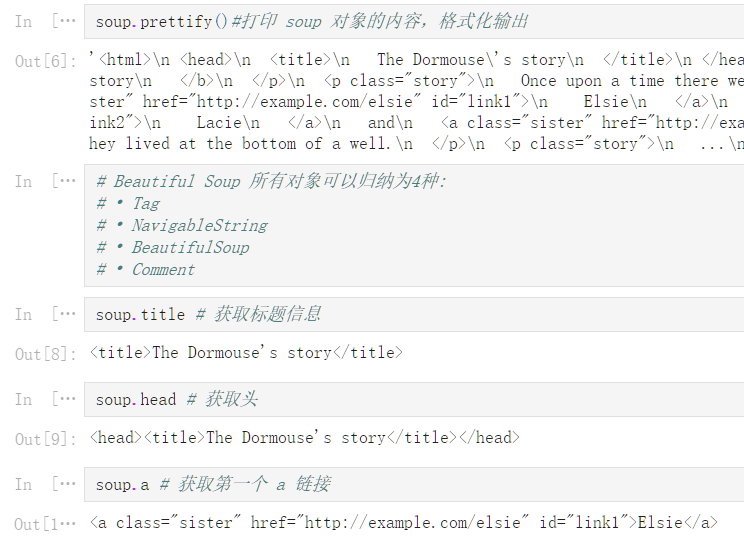
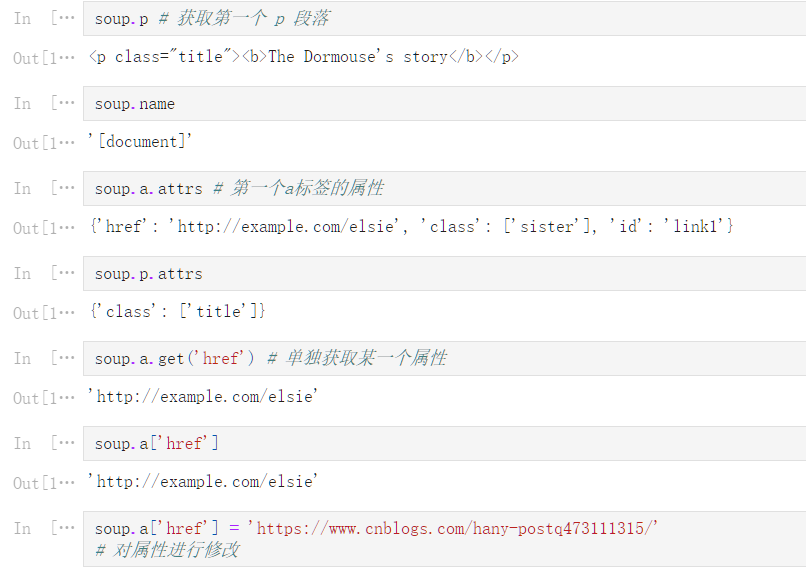

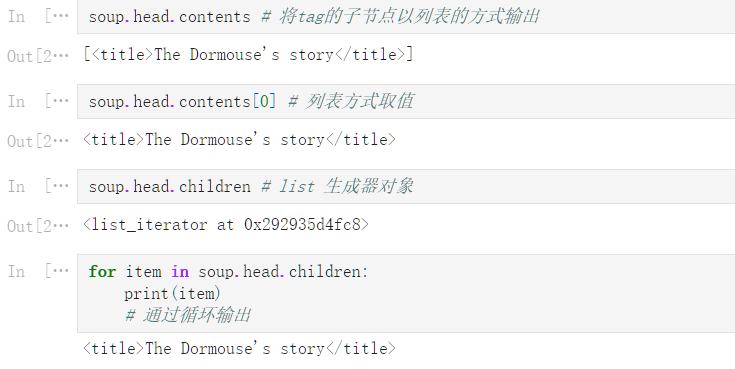
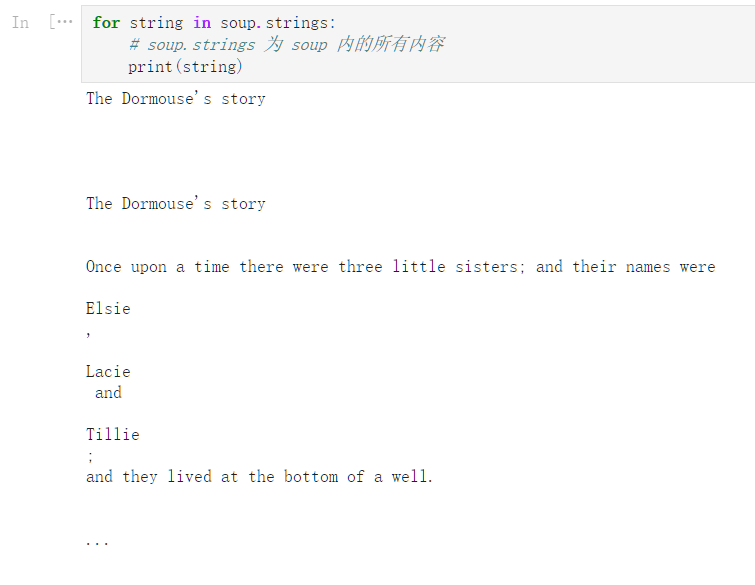
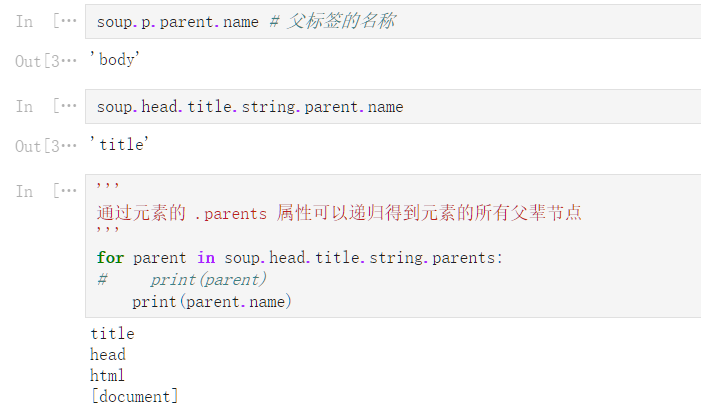
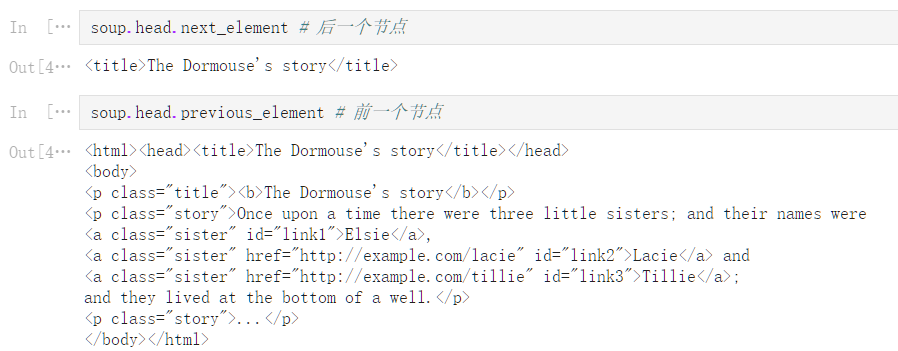
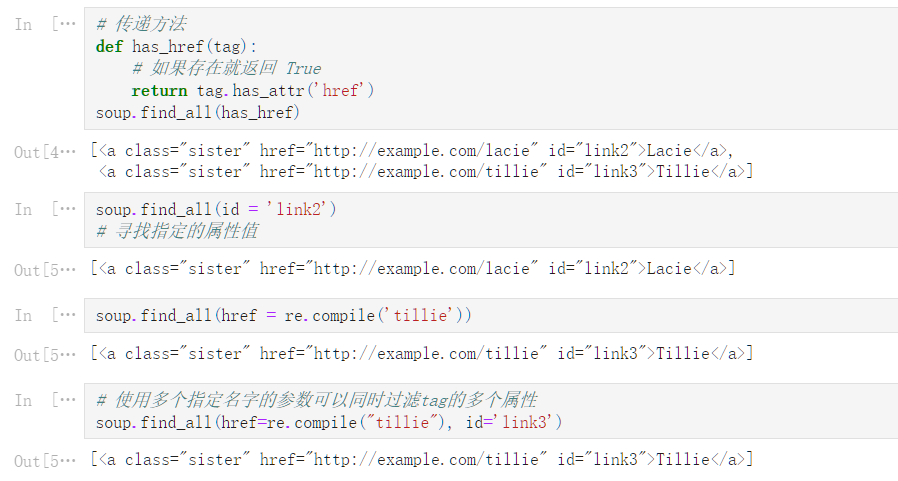
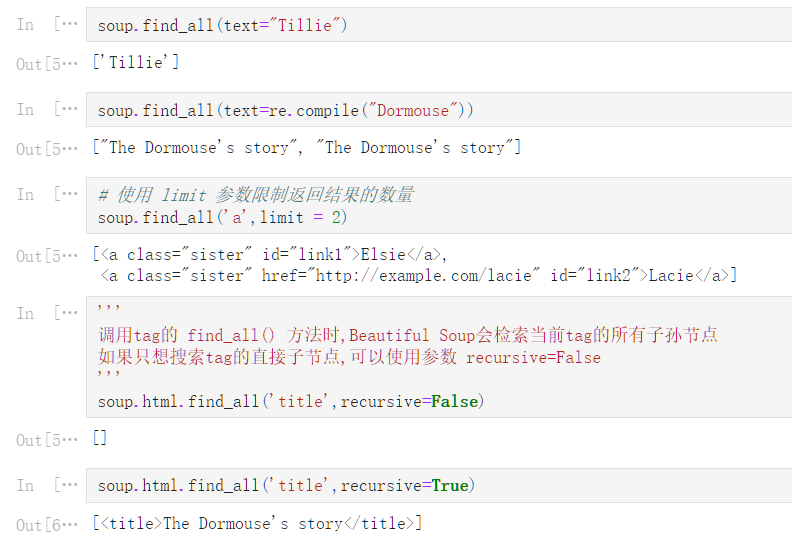
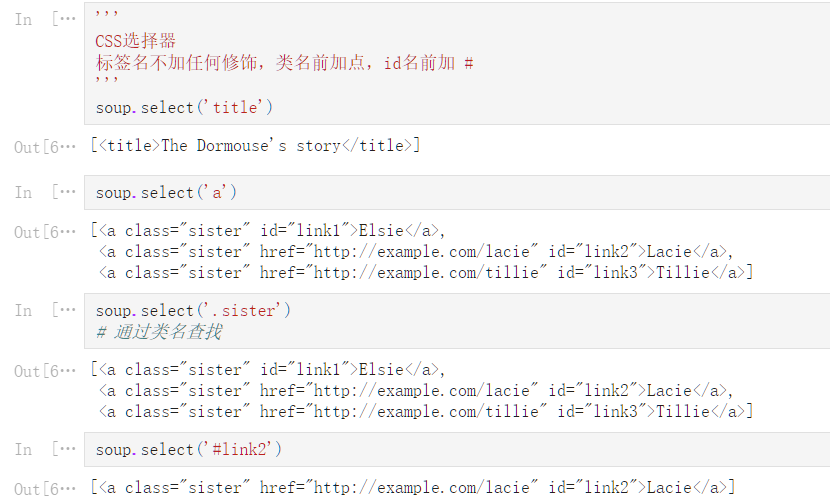
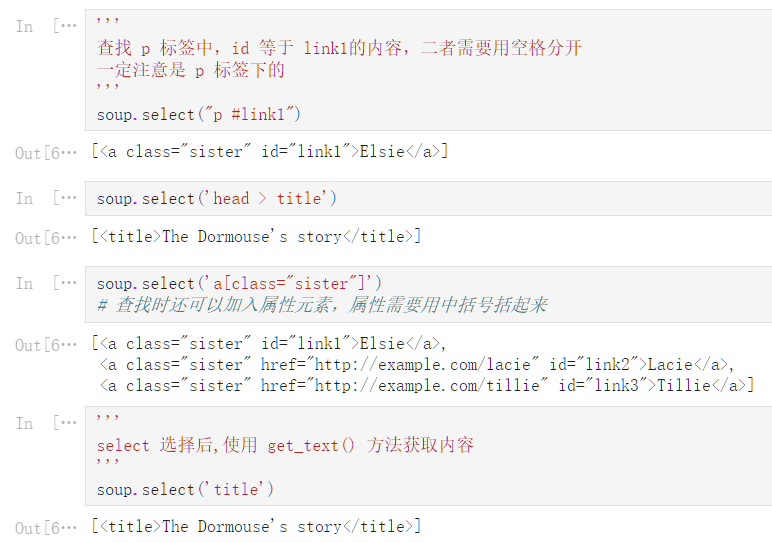
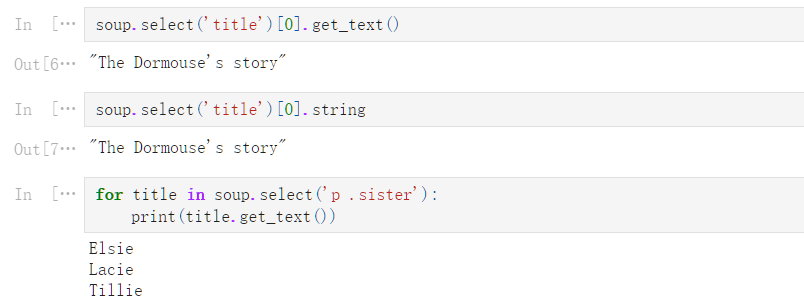
soup
<html><head><title>The Dormouse‘s story</title></head>
<body>
<p class="title"><b>The Dormouse‘s story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>


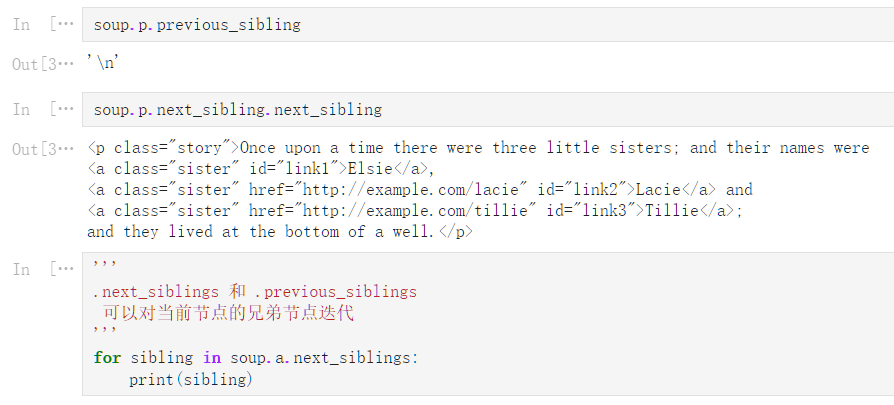
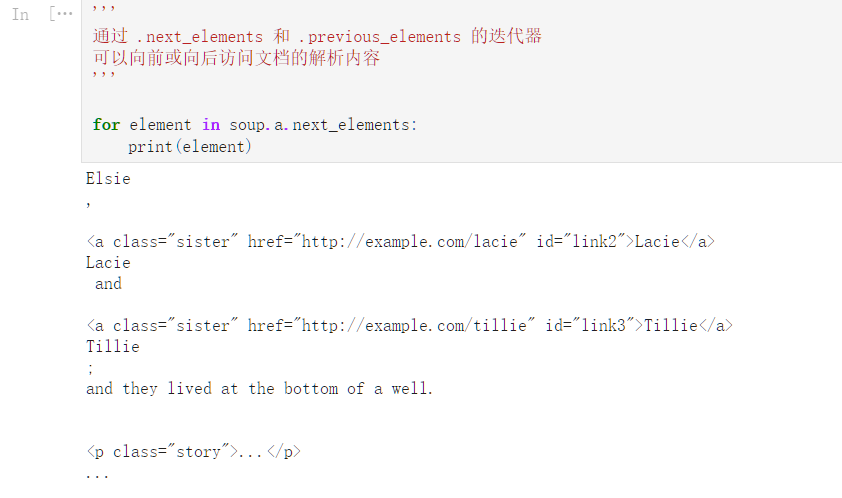
.next_sibling 属性获取了该节点的下一个兄弟节点,
.previous_sibling 属性获取了该节点的上一个兄弟节点,
如果节点不存在,则返回 None
注:
因为空白或者换行也可以被视作一个节点,
所以得到的结果可能是空白或者换行。

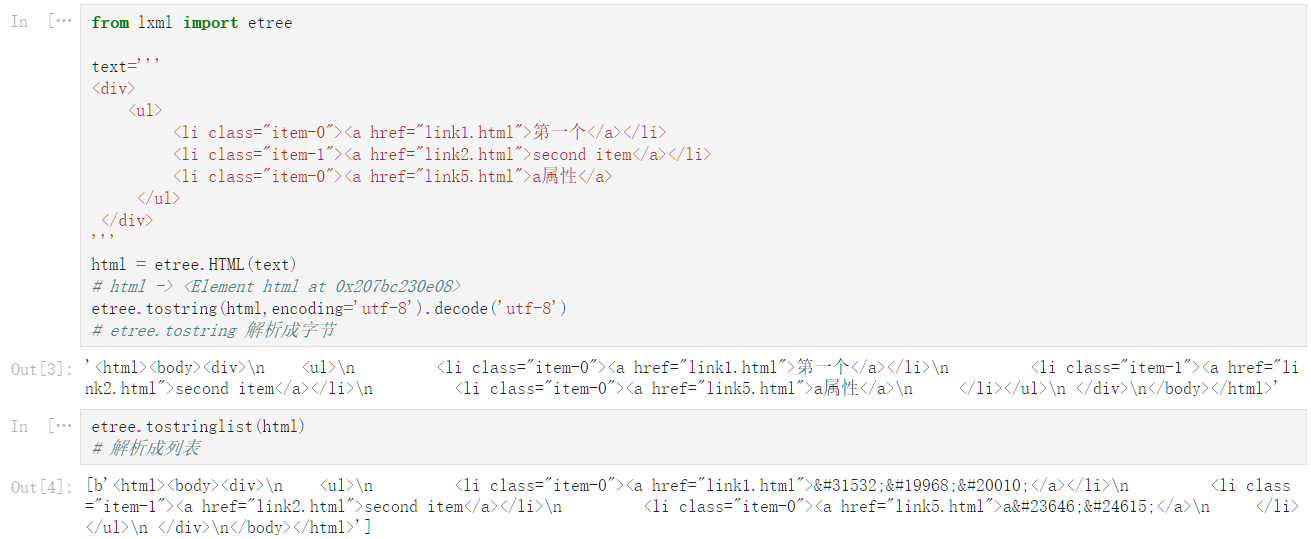
lxml_roles = ‘‘‘
标签名 选取此节点的所有子节点
/ 从当前节点选取直接子节点
// 从当前节点选取子孙节点
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
* 通配符,选择所有元素节点与元素名
@* 选取所有属性
[@attrib] 选取具有给定属性的所有元素
[@attrib=‘value‘] 选取给定属性具有给定值的所有元素
[tag] 选取所有具有指定元素的直接子节点
[tag=‘text‘] 选取所有具有指定元素并且文本内容是 text 节点
‘‘‘
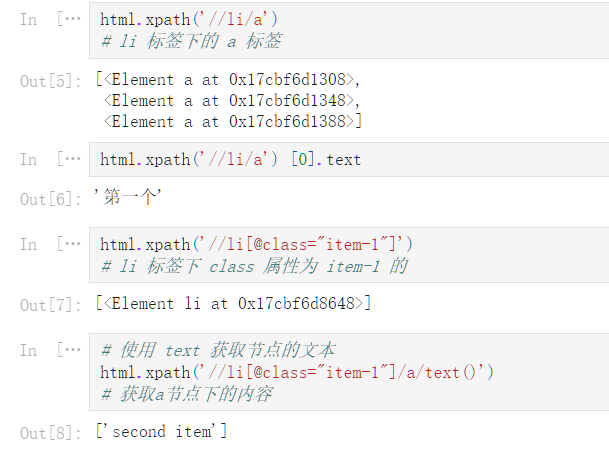
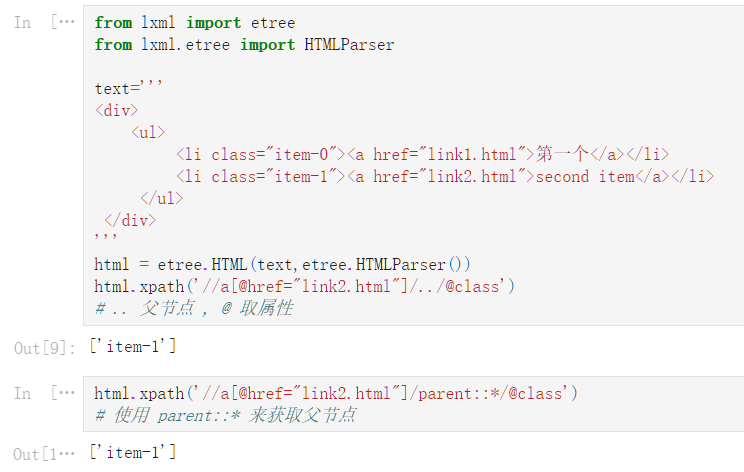
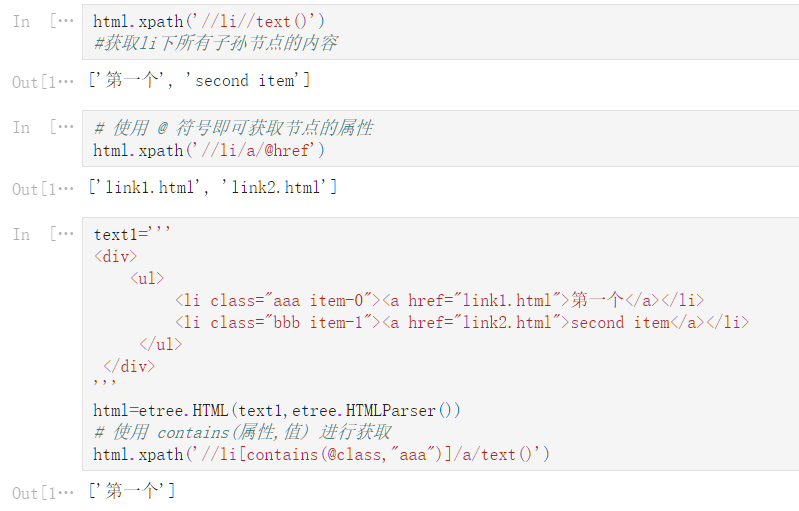
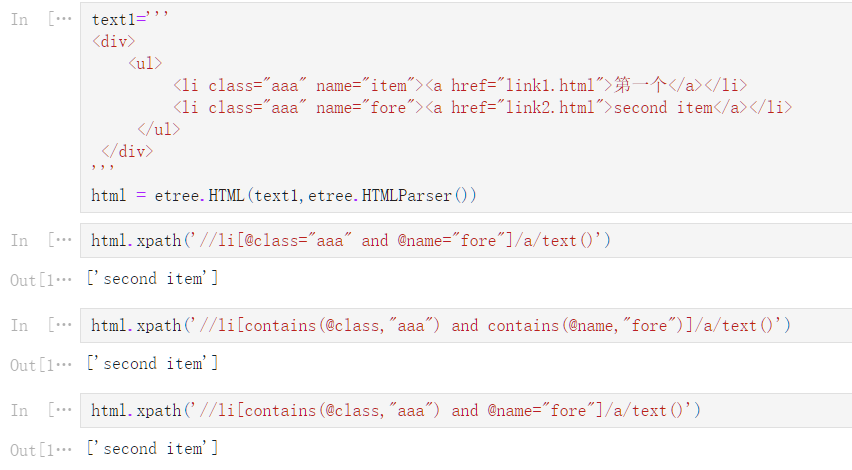
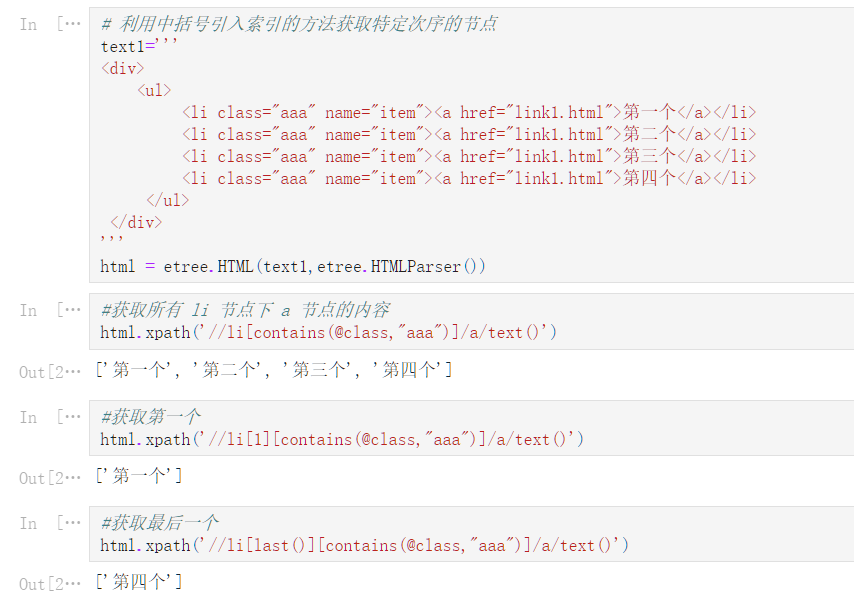
lxml_operators = ‘‘‘
or 或
and 与
mod 取余
| 取两个节点的集合
+ 加 , - 减 , * 乘 , div 除
= 等于 , != 不等于 , < 小于
<= 小于或等于 , > 大于 , >= 大于或等于
‘‘‘
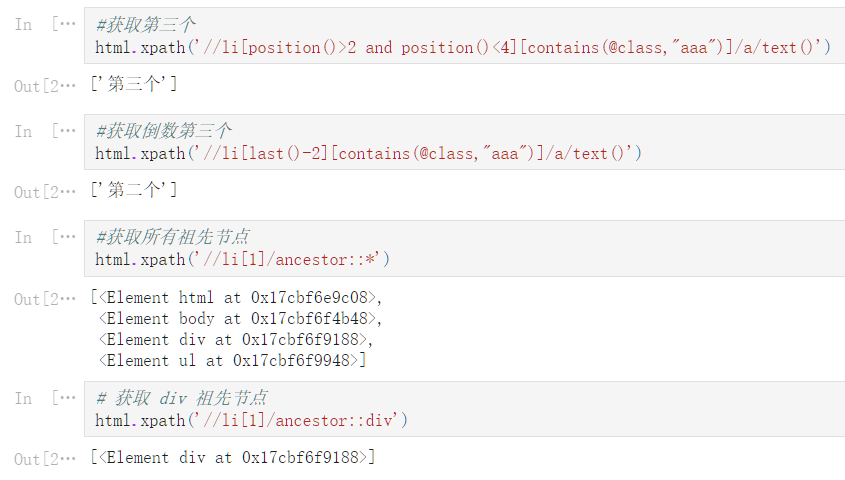
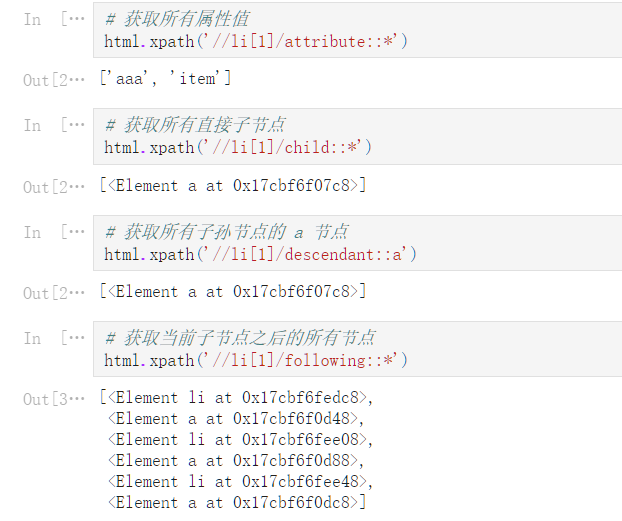
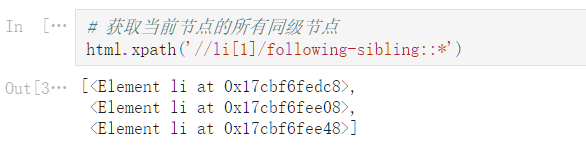
由于 jupyter 复制过来文字会乱,以上为 jupyter 文件转 html 截图
下面为 以上三种库的文本形式
requests 库
原文:https://www.cnblogs.com/hany-postq473111315/p/14256041.html