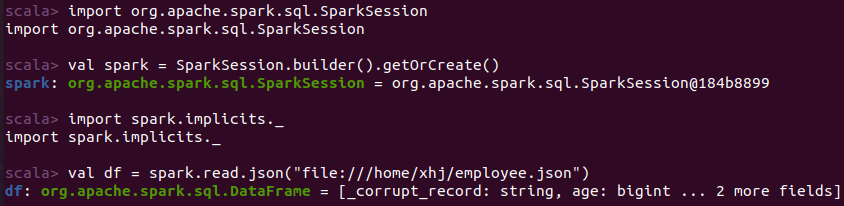
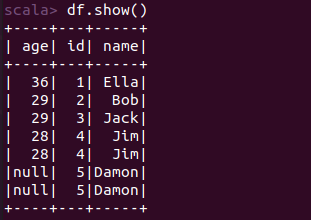
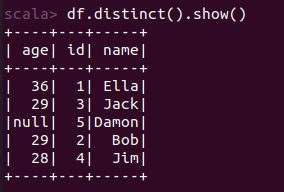
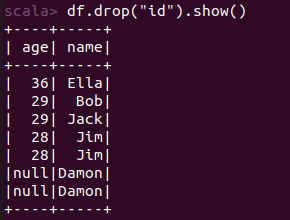
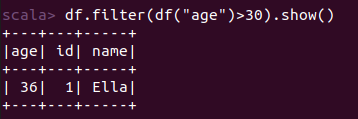
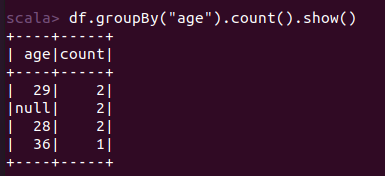
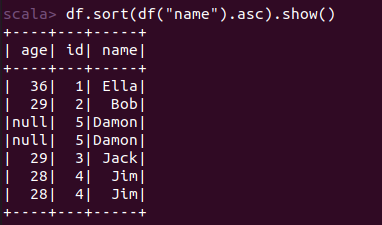

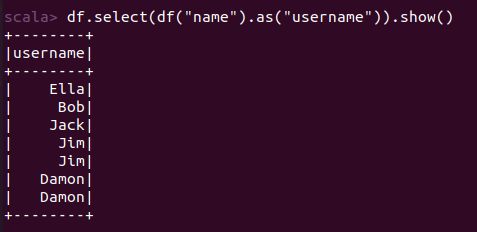


scala> import org.apache.spark.sql.types._ import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row import org.apache.spark.sql.Row scala> val peopleRDD = spark.sparkContext.textFile("file:///home/xhj/employee.txt") peopleRDD: org.apache.spark.rdd.RDD[String] = file:///home/xhj/employee.txt MapPartitionsRDD[1] at textFile at <console>:27 scala> val schemaString = "id name age" schemaString: String = id name age scala> val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true)) fields: Array[org.apache.spark.sql.types.StructField] = Array(StructField(id,StringType,true), StructField(name,StringType,true), StructField(age,StringType,true)) scala> val schema = StructType(fields) schema: org.apache.spark.sql.types.StructType = StructType(StructField(id,StringType,true), StructField(name,StringType,true), StructField(age,StringType,true)) scala> val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim, attributes(2).trim)) rowRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[3] at map at <console>:29 scala> val peopleDF = spark.createDataFrame(rowRDD, schema) peopleDF: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field] scala> peopleDF.createOrReplaceTempView("people") scala> val results = spark.sql("SELECT id,name,age FROM people") results: org.apache.spark.sql.DataFrame = [id: string, name: string ... 1 more field] scala> results.map(attributes => "id: " + attributes(0)+","+"name:"+attributes(1)+","+"age:"+attributes(2)).show() +--------------------+ | value| +--------------------+ |id: 1,name:Ella,a...| |id: 2,name:Bob,ag...| |id: 3,name:Jack,a...| +--------------------+
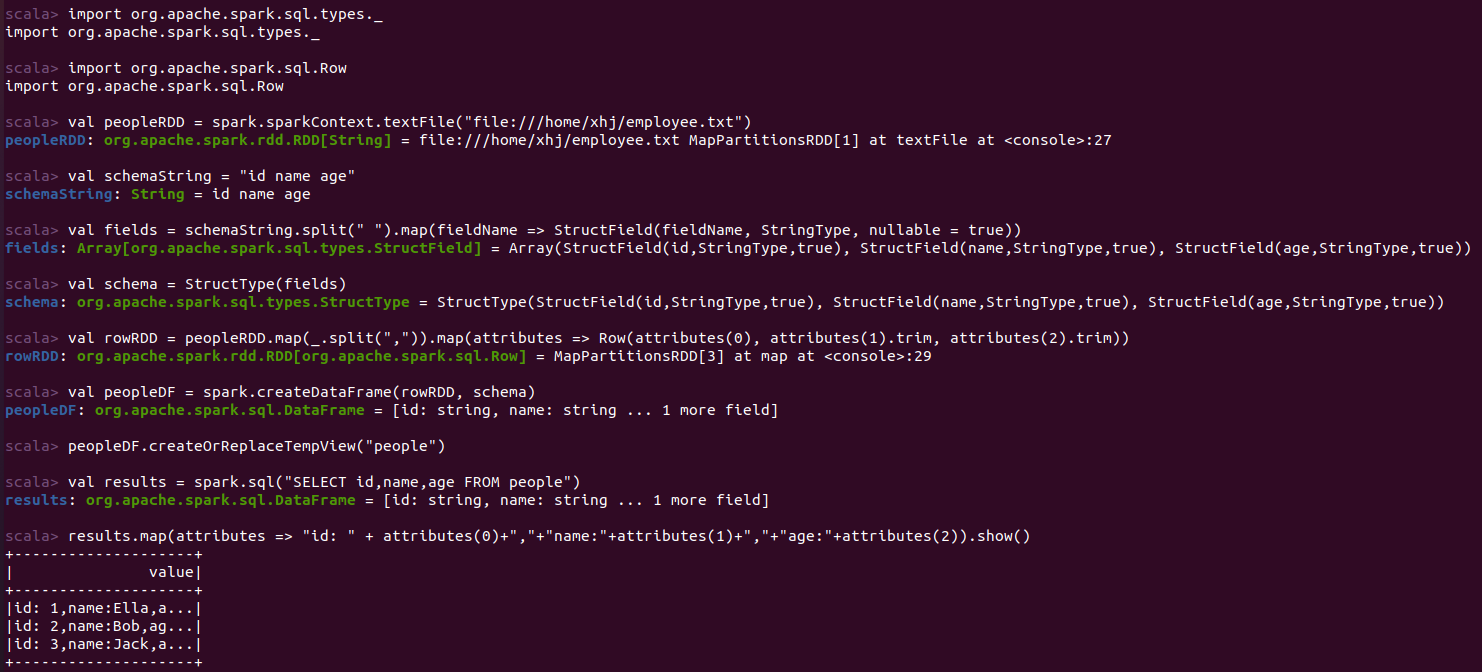
实验结果:



实验代码:
import java.util.Properties import com.sun.org.apache.xalan.internal.xsltc.compiler.util.IntType import org.apache.spark.sql.types._ import org.apache.spark.sql.{Row, SparkSession} object exercise03 { val spark: SparkSession = SparkSession.builder().getOrCreate() def main(args: Array[String]): Unit = { val jdbcDF = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/sparktest?serverTimezone=UTC") .option("driver", "com.mysql.cj.jdbc.Driver").option("dbtable", "employee") .option("user", "root").option("password", "root").load() jdbcDF.show() val studentRDD=spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")) .map(x=>x.split(" ")) val ROWRDD=studentRDD.map(x=>Row(x(0).toInt,x(1).trim,x(2).trim,x(3).toInt)) ROWRDD.foreach(print) //设置模式信息 val schema=StructType(List(StructField("id",IntegerType,true),StructField("name",StringType,true),StructField("gender",StringType,true),StructField("age", IntegerType, true))) val studentDF=spark.createDataFrame(ROWRDD,schema) val parameter=new Properties() parameter.put("user","root") parameter.put("password","root") parameter.put("driver","com.mysql.cj.jdbc.Driver") studentDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest?serverTimezone=UTC","employee",parameter) jdbcDF.show() } }
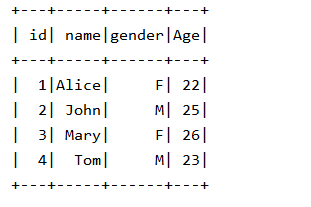
实验结果:
原文:https://www.cnblogs.com/xhj1074376195/p/14257838.html