编程的目的:
计算机的发明,是为了用机器取代/解放人力,而编程的目的则是将人类的思想流程按照某种能给被计算机识别的表达方式传递狗日计算机,从而达到让计算机能够像人脑/电脑一样自动执行的效果
什么是编程语言
能够被计算机识别的表达方式即编程语言,语言是沟通的介质,而编程语言是程序员与计算机沟通的介质。在编程的世界里,计算机更像是人的奴隶,人类编程的目的就命令奴隶去工作。
什么是编程?
编程即程序员根据需要把自己的思想流程按照某种编程语言的语法风格编写下来,产出的结果就是包含一堆字符的文件。
强调:程序在未运行前跟普通文件无异,只有程序在运行时,文件内所写的字符才有特定的语法意义。
编程语言的发展经历
#机器语言:站在计算机角度,说计算机能听懂的语言,就是直接用二进制编程,直接操作硬件;
优点:最底层,执行速度最快;
缺点:最复杂,开发效率最低
#汇编语言:站在计算机的角度,简写的英文标识符取代二进制去编写程序,本质仍然是直接操作硬件; 优点:比较底层,执行速度快;
缺点:复杂,开发效率低
#高级语言:站在人的角度说人话,即用人类的字符去编写程序,屏蔽了硬件操作
编译型:执行速度快,不依赖语言环境运行,跨平台差;
解释型:跨平台好,一份代码,到处使用,缺点是执行速度慢,依赖解释器运行;
编译类:编译是指在应用源程序执行之前,就将程序源代码“翻译”成目标代码(机器语言),因此其目标程序可以脱离其语言环境独立执行(编译后生成的可执行文件,是cpu可以理解的2进制的机器码组成的),使用比较方便、效率较高。
但应用程序一旦需要修改,必须先修改源代码,再重新编译生成新的目标文件(* .obj,也就是OBJ文件)才能执行,只有目标文件而没有源代码,修改很不方便。编译后程序运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如C、C++、Delphi等
解释类:执行方式类似于我们日常生活中的“同声翻译”,应用程序源代码一边由相应语言的解释器“翻译”成目标代码(机器语言),一边执行,因此效率比较低,而且不能生成可独立执行的可执行文件,应用程序不能脱离其解释器(想运行,必须先装上解释器,就像跟老外说话,必须有翻译在场),但这种方式比较灵活,可以动态地调整、修改应用程序。如Python、Java、PHP、Ruby等语言。
高级语言更贴近人类语言,因而造成了:它必须被翻译成计算机能读懂二进制后,才能被执行,按照翻译方式分为:
#1. 编译型(需要编译器,相当于用谷歌翻译):如C,执行速度快,调试麻烦 #2.解释型(需要解释器,相当于同声传译):如Python,执行速度慢,调试方便
#C语言 C语言是一种计算机程序设计语言,它既具有高级语言的特点,又具有汇编语言的特点。它由美国贝尔研究所设计,它可以作为工作系统设计语言,编写系统应用程序,也可以作为应用程序设计语言,编写不依赖计算机硬件的应用程序。它的应用范围广泛,具备很强的数据处理能力,不仅仅是在软件开发上,而且各类科研都需要用到C语言,适于编写系统软件,三维,二维图形和动画,具体应用比如单片机以及嵌入式系统开发。 #C++: C++是C语言的继承的扩展,它既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象的程序设计,还可以进行以继承和多态为特点的面向对象的程序设计。C++擅长面向对象程序设计的同时,还可以进行基于过程的程序设计,因而C++就适应的问题规模而论,大小由之。 C++不仅拥有计算机高效运行的实用性特征,同时还致力于提高大规模程序的编程质量与程序设计语言的问题描述能力。 #JAVA: Java是一种可以撰写跨平台应用软件的面向对象的程序设计语言,是由Sun Microsystems公司于1995年5月推出的Java程序设计语言和Java平台(即JavaSE, JavaEE, JavaME)的总称。Java 技术具有卓越的通用性、高效性、平台移植性和安全性,广泛应用于个人PC、数据中心、游戏控制台、科学超级计算机、移动电话和互联网,同时拥有全球最大的开发者专业社群。在全球云计算和移动互联网的产业环境下,Java更具备了显著优势和广阔前景。 #PHP: PHP(外文名:PHP: Hypertext Preprocessor,中文名:“超文本预处理器”)是一种通用开源脚本语言。语法吸收了C语言、Java和Perl的特点,利于学习,使用广泛,主要适用于Web开发领域 Ruby: Ruby 是开源的,在Web 上免费提供,但需要一个许可证。[4] Ruby 是一种通用的、解释的编程语言。 Ruby 是一种真正的面向对象编程语言。 Ruby 是一种类似于 Python 和 Perl 的服务器端脚本语言。 Ruby 可以用来编写通用网关接口(CGI)脚本。 Ruby 可以被嵌入到超文本标记语言(HTML)。 Ruby 语法简单,这使得新的开发人员能够快速轻松地学习 Ruby #GO: Go 是一个开源的编程语言,它能让构造简单、可靠且高效的软件变得容易。 Go是从2007年末由Robert Griesemer, Rob Pike, Ken Thompson主持开发,后来还加入了Ian Lance Taylor, Russ Cox等人,并最终于2009年11月开源,在2012年早些时候发布了Go 1稳定版本。现在Go的开发已经是完全开放的,并且拥有一个活跃的社区。 由其擅长并发编程 #Python: Python是一门优秀的综合语言, Python的宗旨是简明、优雅、强大,在人工智能、云计算、金融分析、大数据开发、WEB开发、自动化运维、测试等方向应用广泛,已是全球第4大最流行的语言。 几个主流的编程语言介绍
Python可以应用于众多领域,如:数据分析、组件集成、网络服务、图像处理、数值计算和科学计算等众多领域。目前业内几乎所有大中型互联网企业都在使用Python,如:Youtube、Dropbox、BT、Quora(中国知乎)、豆瓣、知乎、Google、Yahoo!、Facebook、NASA、百度、腾讯、汽车之家、美团等。
Python的应用领域
#1. WEB开发——最火的Python web框架Django, 支持异步高并发的Tornado框架,短小精悍的flask,bottle, Django官方的标语把Django定义为the framework for perfectionist with deadlines(大意是一个为完全主义者开发的高效率web框架) #2. 网络编程——支持高并发的Twisted网络框架, py3引入的asyncio使异步编程变的非常简单 #3. 爬虫——爬虫领域,Python几乎是霸主地位,Scrapy\Request\BeautifuSoap\urllib等,想爬啥就爬啥 #4. 云计算——目前最火最知名的云计算框架就是OpenStack,Python现在的火,很大一部分就是因为云计算 #5. 人工智能——谁会成为AI 和大数据时代的第一开发语言?这本已是一个不需要争论的问题。如果说三年前,Matlab、Scala、R、Java 和 Python还各有机会,局面尚且不清楚,那么三年之后,趋势已经非常明确了,特别是前两天 Facebook 开源了 PyTorch 之后,Python 作为 AI 时代头牌语言的位置基本确立,未来的悬念仅仅是谁能坐稳第二把交椅。 #6. 自动化运维——问问中国的每个运维人员,运维人员必须会的语言是什么?10个人相信会给你一个相同的答案,它的名字叫Python #7. 金融分析——我个人之前在金融行业,10年的时候,我们公司写的好多分析程序、高频交易软件就是用的Python,到目前,Python是金融分析、量化交易领域里用的最多的语言 #8. 科学运算—— 你知道么,97年开始,NASA就在大量使用Python在进行各种复杂的科学运算,随着NumPy, SciPy, Matplotlib, Enthought librarys等众多程序库的开发,使的Python越来越适合于做科学计算、绘制高质量的2D和3D图像。和科学计算领域最流行的商业软件Matlab相比,Python是一门通用的程序设计语言,比Matlab所采用的脚本语言的应用范围更广泛 #9. 游戏开发——在网络游戏开发中Python也有很多应用。相比Lua or C++,Python 比 Lua 有更高阶的抽象能力,可以用更少的代码描述游戏业务逻辑,与 Lua 相比,Python 更适合作为一种 Host 语言,即程序的入口点是在 Python 那一端会比较好,然后用 C/C++ 在非常必要的时候写一些扩展。Python 非常适合编写 1 万行以上的项目,而且能够很好地把网游项目的规模控制在 10 万行代码以内。另外据我所知,知名的游戏<文明> 就是用Python写的
Python在一些公司应用
# 谷歌:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发 # CIA: 美国中情局网站就是用Python开发的 # NASA: 美国航天局(NASA)大量使用Python进行数据分析和运算 # YouTube:世界上最大的视频网站YouTube就是用Python开发的 # Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载 # Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发 # Facebook:大量的基础库均通过Python实现的 # Redhat: 世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的 # 豆瓣: 公司几乎所有的业务均是通过Python开发的 # 知乎: 国内最大的问答社区,通过Python开发(国外Quora) # 春雨医生:国内知名的在线医疗网站是用Python开发的 # 除上面之外,还有搜狐、金山、腾讯、盛大、网易、百度、阿里、淘宝 、土豆、新浪、果壳等公司都在使用Python完成各种各样的任务。
如何定义变量
#变量名(相当于门牌号,纸箱值所在的空间),等号,变量值 name = ‘eron‘ sex=‘male‘ age=18 level=10
变量的定义规范
#1. 变量名只能是 字母、数字或下划线的任意组合 #2. 变量名的第一个字符不能是数字 #3. 关键字不能声明为变量名[‘and‘, ‘as‘, ‘assert‘, ‘break‘, ‘class‘, ‘continue‘, ‘def‘, ‘del‘, ‘elif‘, ‘else‘, ‘except‘, ‘exec‘, ‘finally‘, ‘for‘, ‘from‘, ‘global‘, ‘if‘, ‘import‘, ‘in‘, ‘is‘, ‘lambda‘, ‘not‘, ‘or‘, ‘pass‘, ‘print‘, ‘raise‘, ‘return‘, ‘try‘, ‘while‘, ‘with‘, ‘yield‘]
定义变量会有:id,type,value
#1 等号比较的是value, #2 is比较的是id #强调: #1. id相同,意味着type和value必定相同 #2. value相同type肯定相同,但id可能不同,如下 >>> x=‘Info Egon:18‘ >>> y=‘Info Egon:18‘ >>> id(x) 4376607152 >>> id(y) 4376607408 >>> >>> x == y True >>> x is y False
小整数池
#1、在交互式模式下 Python实现int的时候有个小整数池。为了避免因创建相同的值而重复申请内存空间所带来的效率问题, Python解释器会在启动时创建出小整数池,范围是[-5,256],该范围内的小整数对象是全局解释器范围内被重复使用,永远不会被GC回收 每创建一个-5到256之间的整数,都是直接从这个池里直接拿走一个值,例如 >>> y=4 >>> id(y) 4297641184 >>> >>> x=3 >>> x+=1 >>> id(x) 4297641184 #在pycharm中 但在pycharm中运行python程序,pycharm出于对性能的考虑,会扩大小整数池的范围,其他的字符串等不可变类型也都包含在内一便采用相同的方式处理了,我们只需要记住这是一种优化机制,至于范围到底多大,无需细究 小整数池
变量的修改与内存管理(引用计数与垃圾回收机制)
常量
常量即指不变的量,如pai 3.141592653..., 或在程序运行过程中不会改变的量 举例,假如老男孩老师的年龄会变,那这就是个变量,但在一些情况下,他的年龄不会变了,那就是常量。在Python中没有一个专门的语法代表常量,程序员约定俗成用变量名全部大写代表常量 AGE_OF_OLDBOY = 56 #ps:在c语言中有专门的常量定义语法,const int count = 60;一旦定义为常量,更改即会报错
#在python3中 input:用户输入任何值,都存成字符串类型 #在python2中 input:用户输入什么类型,就存成什么类型 raw_input:等于python3的input
注释
代码注释分单行和多行注释, 单行注释用#,多行注释可以用三对双引号""" """
代码注释的原则:
#1. 不用全部加注释,只需要在自己觉得重要或不好理解的部分加注释即可 #2. 注释可以用中文或英文,但不要用拼音
文件头
#!/usr/bin/env python # -*- coding: utf-8 -*-
概括地说,编程语言的划分方式有以下三种 1、编译型or解释型 2、强类型or弱类型 2.1 强类型语言: 数据类型不可以被忽略的语言 即变量的数据类型一旦被定义,那就不会再改变,除非进行强转。 在python中,例如:name = ‘egon‘,这个变量name在被赋值的那一刻,数据类型就被确定死了,是字符型,值为‘egon‘。 2.2 弱类型语言:数据类型可以被忽略的语言 比如linux中的shell中定义一个变量,是随着调用方式的不同,数据类型可随意切换的那种。 3、动态型or静态型 3.1 动态语言 :运行时才进行数据类型检查 即在变量赋值时,就确定了变量的数据类型,不用事先给变量指定数据类型 3.2 静态语言:需要事先给变量进行数据类型定义 所以综上所述,Python是一门解释型的强类型动态语言
数字
#int 整型 定义:age= 10 #age = int(10) 用于标识:年龄、等级,身份证号,QQ号,个数 #float浮点型 用于标识:工资、身高、体重
#int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647 在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807 #long(长整型) 跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。 注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。 注意:在Python3里不再有long类型了,全都是int >>> a= 2**64 >>> type(a) #type()是查看数据类型的方法 <type ‘long‘> >>> b = 2**60 >>> type(b) <type ‘int‘> #complex复数型 >>> x=1-2j >>> x.imag -2.0 >>> x.real 1.0 其他数据类型(了解部分)
字符串
#在Python中,加了引号的字符就是字符串类型 定义:name=‘alex‘ #name= str(‘alex‘) 用于标识:描述的内容,如姓名,性别,国籍,种族 #单引号、双引号、多引号有什么区别?没有区别 #多引号什么作用?作用就是多行字符串必须用多引号 #数字可以进行加减乘除等运算,字符串呢?让我大声告诉你,也能?what ?是的,但只能进行"相加"和"相乘"运算。 >>> name=‘egon‘ >>> age=‘18‘ >>> name+age #相加其实就是简单拼接 ‘egon18‘ >>> name*5 ‘egonegonegonegonegon‘ #注意1:字符串相加的效率不高 字符串1+字符串3,并不会在字符串1的基础上加字符串2,而是申请一个全新的内存空间存入字符串1和字符串3,相当字符串1与字符串3的空间被复制了一次, #注意2:只能字符串加字符串,不能字符串加其他类型
列表
#在【】内用逗号分隔,可以存放N个人以类型的值 定义: 用于识别:存储N多个值得情况,比如一个人有多个爱好 #存放多个学生的信息:姓名,年龄,爱好 >>> students_info=[[‘egon‘,18,[‘play‘,]],[‘alex‘,18,[‘play‘,‘sleep‘]]] >>> students_info[0][2][0] #取出第一个学生的第一个爱好 ‘play‘
字典
#为何还要用字典? 存放一个人的信息:姓名,性别,年龄,很明显是多个值,既然是存多个值,我们完全可以基于刚刚学习的列表去存放,如下 >>> info=[‘egon‘,‘male‘,18] 定义列表的目的不单单是为了存,还要考虑取值,如果我想取出这个人的年龄,可以用 >>> info[2] 18 但这是基于我们已经知道在第3个位置存放的是年龄的前提下,我们才知道索引2对应的是年龄 即: #name, sex, age info=[‘egon‘,‘male‘,18] 而这完全只是一种假设,并没有真正意义上规定第三个位置存放的是年龄,于是我们需要寻求一种,即可以存放多个任意类型的值,又可以硬性规定值的映射关系的类型,比如key=value,这就用到了字典
#在{}内用逗号分隔,可以存放多个key:value的值,value可以是任意类型 定义:info={‘name‘:‘egon‘,‘age‘:18,‘sex‘:18} #info=dict({‘name‘:‘egon‘,‘age‘:18,‘sex‘:18}) 用于标识:存储多个值的情况,每个值都有唯一一个对应的key,可以更为方便高效地取值
info={ ‘name‘:‘egon‘, ‘hobbies‘:[‘play‘,‘sleep‘], ‘company_info‘:{ ‘name‘:‘Oldboy‘, ‘type‘:‘education‘, ‘emp_num‘:40, } } print(info[‘company_info‘][‘name‘]) #取公司名 students=[ {‘name‘:‘alex‘,‘age‘:38,‘hobbies‘:[‘play‘,‘sleep‘]}, {‘name‘:‘egon‘,‘age‘:18,‘hobbies‘:[‘read‘,‘sleep‘]}, {‘name‘:‘wupeiqi‘,‘age‘:58,‘hobbies‘:[‘music‘,‘read‘,‘sleep‘]}, ] print(students[1][‘hobbies‘][1]) #取第二个学生的第二个爱好 字典相关的嵌套、取值
布尔
#布尔值,一个True一个False #计算机俗称电脑,即我们编写程序让计算机运行时,应该是让计算机无限接近人脑,或者说人脑能干什么,计算机就应该能干什么,人脑的主要作用是数据运行与逻辑运算,此处的布尔类型就模拟人的逻辑运行,即判断一个条件成立时,用True标识,不成立则用False标识 >>> a=3 >>> b=5 >>> >>> a > b #不成立就是False,即假 False >>> >>> a < b #成立就是True, 即真 True 接下来就可以根据条件结果来干不同的事情了: if a > b print(a is bigger than b ) else print(a is smaller than b ) 上面是伪代码,但意味着, 计算机已经可以像人脑一样根据判断结果不同,来执行不同的动作。
布尔类型的重点知识!!!:
#所有数据类型都自带布尔值 1、None,0,空(空字符串,空列表,空字典等)三种情况下布尔值为False 2、其余均为真
重点:
#1.可变类型:在id不变的情况下,value可以变,则称为可变类型,如列表,字典 #2. 不可变类型:value一旦改变,id也改变,则称为不可变类型(id变,意味着创建了新的内存空间)
程序中经常会有这样场景:要求用户输入信息,然后打印成固定的格式
比如要求用户输入用户名和年龄,然后打印如下格式:
My name is xxx,my age is xxx.
很明显,用逗号进行字符串拼接,只能把用户输入的名字和年龄放到末尾,无法放到指定的xxx位置,而且数字也必须经过str(数字)的转换才能与字符串进行拼接。
这就用到了占位符,如:%s、%d
#%s字符串占位符:可以接收字符串,也可接收数字 print(‘My name is %s,my age is %s‘ %(‘egon‘,18)) #%d数字占位符:只能接收数字 print(‘My name is %s,my age is %d‘ %(‘egon‘,18)) print(‘My name is %s,my age is %d‘ %(‘egon‘,‘18‘)) #报错 #接收用户输入,打印成指定格式 name=input(‘your name: ‘) age=input(‘your age: ‘) #用户输入18,会存成字符串18,无法传给%d print(‘My name is %s,my age is %s‘ %(name,age)) #注意: #print(‘My name is %s,my age is %d‘ %(name,age)) #age为字符串类型,无法传给%d,所以会报错
练习:用户输入姓名、年龄、工作、爱好 ,然后打印成以下格式 ------------ info of Egon ----------- Name : Egon Age : 22 Sex : male Job : Teacher ------------- end ----------------- 小练习 Name=input(‘Name : ‘) Age=input(‘Age : ‘) Sex=input(‘Sex : ‘) Job=input(‘Job : ‘) print(‘-‘*10+‘info of Egon‘+‘-‘*10) print(‘Name : %s‘ %Name) print(‘Age : %s‘ %Age) print(‘Sex : %s‘ %Sex) print(‘Job : %s‘ %Job) print(‘-‘*10 + ‘ end ‘+‘-‘*10)
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算
算术运算
+ - * / %(取模,余数) **幂 // 取整数
比较运算--结果都是布尔值
== != <> > < >= <=
赋值运算
= += -= *= /= %= **= //=
逻辑运算
and or not
#1、三者的优先级关系:not>and>or,同一优先级默认从左往右计算。 >>> 3>4 and 4>3 or 1==3 and ‘x‘ == ‘x‘ or 3 >3 False #2、最好使用括号来区别优先级,其实意义与上面的一样 ‘‘‘ 原理为: (1) not的优先级最高,就是把紧跟其后的那个条件结果取反,所以not与紧跟其后的条件不可分割 (2) 如果语句中全部是用and连接,或者全部用or连接,那么按照从左到右的顺序依次计算即可 (3) 如果语句中既有and也有or,那么先用括号把and的左右两个条件给括起来,然后再进行运算 ‘‘‘ >>> (3>4 and 4>3) or (1==3 and ‘x‘ == ‘x‘) or 3 >3 False #3、短路运算:逻辑运算的结果一旦可以确定,那么就以当前处计算到的值作为最终结果返回 >>> 10 and 0 or ‘‘ and 0 or ‘abc‘ or ‘egon‘ == ‘dsb‘ and 333 or 10 > 4 我们用括号来明确一下优先级 >>> (10 and 0) or (‘‘ and 0) or ‘abc‘ or (‘egon‘ == ‘dsb‘ and 333) or 10 > 4 短路: 0 ‘‘ ‘abc‘ 假 假 真 返回: ‘abc‘ #4、短路运算面试题: >>> 1 or 3 1 >>> 1 and 3 3 >>> 0 and 2 and 1 0 >>> 0 and 2 or 1 1 >>> 0 and 2 or 1 or 4 1 >>> 0 or False and 1 False
身份运算
#is比较的是id
#而==比较的是值
既然我们编程的目的是为了控制计算机能够像人脑一样工作,那么人脑能做什么,就需要程序中有相应的机制去模拟。人脑无非是数学运算和逻辑运算,对于数学运算在上一节我们已经说过了。对于逻辑运算,即人根据外部条件的变化而做出不同的反映,比如
#在表白的基础上继续: #如果表白成功,那么:在一起 #否则:打印。。。 age_of_girl=18 height=171 weight=99 is_pretty=True success=False if age_of_girl >= 18 and age_of_girl < 22 and height > 170 and weight < 100 and is_pretty == True: if success: print(‘表白成功,在一起‘) else: print(‘什么爱情不爱情的,爱nmlgb的爱情,爱nmlg啊...‘) else: print(‘阿姨好‘)
if 条件1: 缩进的代码块 elif 条件2: 缩进的代码块 elif 条件3: 缩进的代码块 ...... else: 缩进的代码块
# 如果:今天是Monday,那么:上班 # 如果:今天是Tuesday,那么:上班 # 如果:今天是Wednesday,那么:上班 # 如果:今天是Thursday,那么:上班 # 如果:今天是Friday,那么:上班 # 如果:今天是Saturday,那么:出去浪 # 如果:今天是Sunday,那么:出去浪 #方式一: today=input(‘>>: ‘) if today == ‘Monday‘: print(‘上班‘) elif today == ‘Tuesday‘: print(‘上班‘) elif today == ‘Wednesday‘: print(‘上班‘) elif today == ‘Thursday‘: print(‘上班‘) elif today == ‘Friday‘: print(‘上班‘) elif today == ‘Saturday‘: print(‘出去浪‘) elif today == ‘Sunday‘: print(‘出去浪‘) else: print(‘‘‘必须输入其中一种: Monday Tuesday Wednesday Thursday Friday Saturday Sunday ‘‘‘) #方式二: today=input(‘>>: ‘) if today == ‘Saturday‘ or today == ‘Sunday‘: print(‘出去浪‘) elif today == ‘Monday‘ or today == ‘Tuesday‘ or today == ‘Wednesday‘ or today == ‘Thursday‘ or today == ‘Friday‘: print(‘上班‘) else: print(‘‘‘必须输入其中一种: Monday Tuesday Wednesday Thursday Friday Saturday Sunday ‘‘‘) #方式三: today=input(‘>>: ‘) if today in [‘Saturday‘,‘Sunday‘]: print(‘出去浪‘) elif today in [‘Monday‘,‘Tuesday‘,‘Wednesday‘,‘Thursday‘,‘Friday‘]: print(‘上班‘) else: print(‘‘‘必须输入其中一种: Monday Tuesday Wednesday Thursday Friday Saturday Sunday ‘‘‘) 练习三
1 为何要用循环
#上节课我们已经学会用if .. else 来猜年龄的游戏啦,但是只能猜一次就中的机率太小了,如果我想给玩家3次机会呢?就是程序启动后,玩家最多可以试3次,这个怎么弄呢?你总不会想着把代码复制3次吧。。。。 age_of_oldboy = 48 guess = int(input(">>:")) if guess > age_of_oldboy : print("猜的太大了,往小里试试...") elif guess < age_of_oldboy : print("猜的太小了,往大里试试...") else: print("恭喜你,猜对了...") #第2次 guess = int(input(">>:")) if guess > age_of_oldboy : print("猜的太大了,往小里试试...") elif guess < age_of_oldboy : print("猜的太小了,往大里试试...") else: print("恭喜你,猜对了...") #第3次 guess = int(input(">>:")) if guess > age_of_oldboy : print("猜的太大了,往小里试试...") elif guess < age_of_oldboy : print("猜的太小了,往大里试试...") else: print("恭喜你,猜对了...") #即使是小白的你,也觉得的太low了是不是,以后要修改功能还得修改3次,因此记住,写重复的代码是程序员最不耻的行为。 那么如何做到不用写重复代码又能让程序重复一段代码多次呢? 循环语句就派上用场啦
2 条件循环:while,语法如下
while 条件: # 循环体
# 如果条件为真,那么循环体则执行,执行完毕后再次循环,重新判断条件。。。 # 如果条件为假,那么循环体不执行,循环终止
#打印0-10 count=0 while count <= 10: print(‘loop‘,count) count+=1 #打印0-10之间的偶数 count=0 while count <= 10: if count%2 == 0: print(‘loop‘,count) count+=1 #打印0-10之间的奇数 count=0 while count <= 10: if count%2 == 1: print(‘loop‘,count) count+=1
3 死循环
import time num=0 while True: print(‘count‘,num) time.sleep(1) num+=1
4 循环嵌套与tag
tag=True while tag: ...... while tag: ........ while tag: tag=False
5 break与continue
#break用于退出本层循环 while True: print "123" break print "456" #continue用于退出本次循环,继续下一次循环 while True: print "123" continue print "456"
6 while + else
#与其它语言else 一般只与if 搭配不同,在Python 中还有个while ...else 语句,while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句 count = 0 while count <= 5 : count += 1 print("Loop",count) else: print("循环正常执行完啦") print("-----out of while loop ------") 输出 Loop 1 Loop 2 Loop 3 Loop 4 Loop 5 Loop 6 循环正常执行完啦 -----out of while loop ------ #如果执行过程中被break啦,就不会执行else的语句啦 count = 0 while count <= 5 : count += 1 if count == 3:break print("Loop",count) else: print("循环正常执行完啦") print("-----out of while loop ------") 输出 Loop 1 Loop 2 -----out of while loop ------
6 while循环练习题
#1. 使用while循环输出1 2 3 4 5 6 8 9 10
count=1
while count <=10:
if count ==7 :
print(‘ ‘,end=‘ ‘)
else:
print(count,end=‘ ‘)
count += 1
#2. 求1-100的所有数的和
count=1
sum=0
while count <=100:
sum += count
count += 1
print(sum)
#3. 输出 1-100 内的所有奇数
count=0
while count <=100:
if count%2 == 1:
print(count)
count += 1
#4. 输出 1-100 内的所有偶数
count=0
while count <=100:
if count%2 == 0:
print(count)
count += 1
#5. 求1-2+3-4+5 ... 99的所有数的和
count=0
sum=0
while count <100:
if count%2 == 0:
sum += count
else:
sum += -count
count +=1
print(sum)
#6. 用户登陆(三次机会重试)
count=1
name=‘lingling‘
password=‘123‘
still_count=3
while count <4:
in_name=input(‘名字: ‘)
in_pass=input(‘密码: ‘)
if in_name!=name or in_pass!=password:
still_count = still_count - 1
if still_count > 0:
print(‘名字或密码错误,请再次输入名字和密码,仍有%s次机会‘ %still_count)
else:
print(‘已超过3次机会,账户将被锁定‘)
count +=1
#7:猜年龄游戏 要求: 允许用户最多尝试3次,3次都没猜对的话,就直接退出,如果猜对了,打印恭喜信息并退出 #8:猜年龄游戏升级版 要求: 允许用户最多尝试3次
每尝试3次后,如果还没猜对,就问用户是否还想继续玩,如果回答Y或y, 就继续让其猜3次,以此往复,如果回答N或n,就退出程序 如何猜对了,就直接退出
import sys
answer = 1
while answer == 1: ##确定后续的反复循环
count=1
name=‘lingling‘
password=‘123‘
still_count=3
while count <4: ##确定密码循环次数
in_name=input(‘名字: ‘)
in_pass=input(‘密码: ‘)
if in_name!=name or in_pass!=password:
still_count = still_count - 1
if still_count > 0:
print(‘名字或密码错误,请再次输入名字和密码,仍有%s次机会‘ %still_count)
else:
to_answer=input(‘已超过3次机会,你是否继续玩,请给出你的答案(Y/N):‘) ###确定是否继续循环,需要回到循环条件
if to_answer in [‘y‘,‘Y‘]:
answer=1
else:
answer=0
else:
print(‘恭喜你答对了,退出‘)
sys.exit()
count +=1
age = 73
count=0
while True:
if count == 3:
choice = input(‘Y OR N‘)
if choice == ‘Y‘ or choice == ‘y‘:
count=0
else:
break
guess = int(input(‘你猜的数字: ‘))
if guess == age:
print(‘你猜对了‘)
break
count +=1
1 迭代式循环:for,语法如下
for i in range(10):
缩进的代码块
2 break与continue(同上)
3 循环嵌套
for i in range(10): for j in range(1,i+1): print(‘%s * %s = %s‘%(i,j,i*j),end=‘ ‘) print()
for i in range(1,6): for j in range(6-i): print(‘ ‘,end=‘‘) for m in range(2*i - 1): print(‘*‘,end=‘‘) for j in range(6-i): print(‘ ‘,end=‘‘) print(‘‘) i +=1
一、循环bai的结构不du同
for循环的表达式为:for(单次表达式;条件表dao达式;末尾循环体zhuan){中间循环体;}。
while循环的表达式为:while(表达式){循环体}。
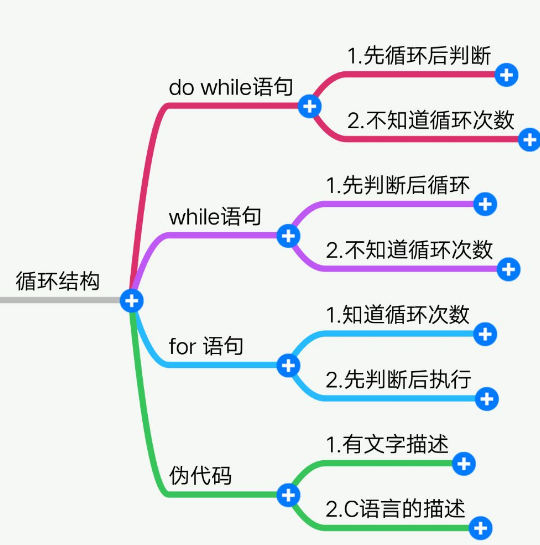
二、执行条件的判断方式不同
for循环执行末尾循环体后将再次进行条件判断,若条件还成立,则继续重复上述循环,当条件不成立时则跳出当下for循环。
while循环当满足条件时进入循环,进入循环后,当条件不满足时,执行完循环体内全部语句后再跳出(而不是立即跳出循环)。
三、使用的目的不同
for循环的目的是为了限制循环体的执行次数,使结果更精确。
while循环的目的是为了反复执行语句或代码块。
四、语法不同
for循环的语法为:for (变量 = 开始值;变量 <= 结束值;变量 = 变量 + 步进值) {需执行的代码 }。
while循环的语法为:while (<条件>) {需执行的代码 }。
1 为何要用IDE
到现在为止,我们也是写过代码的人啦,但你有没有发现,每次写代码要新建文件、写完保存时还要选择存放地点,执行时还要切换到命令行调用python解释器,好麻烦呀,能否一气呵成,让我简单的写代码?此时开发工具IDE上场啦,一个好的IDE能帮你大大提升开发效率。
很多语言都有比较流行的开发工具,比如JAVA 的Eclipse, C#,C++的VisualStudio, Python的是啥呢? Pycharm,最好的Python 开发IDE
2 安装
1 练习题
简述编译型与解释型语言的区别,且分别列出你知道的哪些语言属于编译型,哪些属于解释型
编译型:编译后程序运行时不需要重新翻译,直接使用编译的结果就行了。程序执行效率高,依赖编译器,跨平台性差些。如C、C++、Delphi等解释类:
解释型:执行方式类似于我们日常生活中的“同声翻译”,应用程序源代码一边由相应语言的解释器“翻译”成目标代码(机器语言),一边执行,因此效率比较低,
而且不能生成可独立执行的可执行文件,应用程序不能脱离其解释器(想运行,必须先装上解释器,就像跟老外说话,必须有翻译在场),
但这种方式比较灵活,可以动态地调整、修改应用程序。如Python、Java、PHP、Ruby等语言。
#进入解释器的交互式模式:调试方便,无法永久保存代码
#脚本文件的方式(使用nodpad++演示):永久保存代码
单行:单引号或者双引号
多行:三引号
#布尔值,一个True一个False
#计算机俗称电脑,即我们编写程序让计算机运行时,应该是让计算机无限接近人脑,或者说人脑能干什么,计算机就应该能干什么,人脑的主要作用是数据运行与逻辑运算,此处的布尔类型就模拟人的逻辑运行,即判断一个条件成立时,用True标识,不成立则用False标识
y=54 print(id(y))
#!/usr/bin/env python
#-*- coding:utf-8 -*-
#author:Amily wang
‘‘‘
让用户输入用户名密码
认证成功后退出
输入错误有三次机会再输入
‘‘‘
count = 1
while count <=3:
name = input(‘请输入用户名: ‘)
password = input(‘请输入密码: ‘)
if name==‘seven‘ and password==‘123‘:
print(‘succuss!‘)
break
else:
if count <3:
count +=1
print(‘fail!,您可继续输入密码‘)
else:
print(‘您已连续输入3次错误密码,暂时不可登录‘)
break
写代码
a. 使用while循环实现输出2-3+4-5+6...+100 的和
b. 使用 while 循环实现输出 1,2,3,4,5, 7,8,9, 11,12 使用 while 循环实现输出 1-100 内的所有奇数
e. 使用 while 循环实现输出 1-100 内的所有偶数
现有如下两个变量,请简述 n1 和 n2 是什么关系?
n1 = 123456
n2 = n1
2 作业:编写登陆接口
基础需求:
# !/usr/bin/env python # -*- coding:utf-8 -*- # Author:Hiuhung Wan ‘‘‘ 让用户输入用户名密码 认证成功后显示欢迎信息 用户3次认证失败后,退出程序,再次启动程序尝试登录时,还是锁定状态 ‘‘‘ dic_user_info = { "usera": {"pw": "123", "err_count": 0}, "userb": {"pw": "123", "err_count": 0}, "userc": {"pw": "123", "err_count": 0}, "userd": {"pw": "123", "err_count": 0}, "usere": {"pw": "123", "err_count": 0}, } # 创建一个黑名单文件,这里把usera列入黑名单 try: with open(‘blacklist.txt‘, ‘r‘) as f: if not f.read(): # 没有内容,就写入 with open(‘blacklist.txt‘, ‘a‘) as f: f.write("usera,") except FileNotFoundError as e: # 没有这个文件,就创建并写入内容 with open(‘blacklist.txt‘, ‘a‘) as f: f.write("usera,") finally: f.close() # 关闭文件。 for i in range(100): username = input("请输入用户名(按q退出程序):") # 按q退出程序 if username == ‘q‘: exit() # 用户名不在字典中 elif username not in dic_user_info: print("无此账户,请检查您的输入") continue # 用户在字典中,但被锁定 with open(‘blacklist.txt‘, ‘r‘) as f: user_locked_list = f.read().split(",") if username in user_locked_list: print("账户%s已被锁定。。。请更换另一个账户" % username) f.close() continue f.close() # 用户在字典中,也未被锁定,则提示输入密码 password = input("请输入密码:") if password == dic_user_info[username]["pw"]: # 密码正确 print("欢迎【%s】登录系统。。。" % username) break else: # 密码错 dic_user_info[username]["err_count"] += 1 # 记录错误次数 if dic_user_info[username]["err_count"] < 3: print("密码不对,您已经输错%d次密码了,输错3次账户将被锁定" % dic_user_info[username]["err_count"]) else: # dic_user_info[username]["err_count"] >= 3: # 输错3次,录入黑名单数据库 with open(‘blacklist.txt‘, ‘a‘) as f: f.write("%s," % username) f.close() print("输错3次密码,此账户已加入黑名单") break
原文:https://www.cnblogs.com/amilywang/p/14237395.html