lines.flatMap(_.split(" "))将一个数据一对多的转换为另外的形式, 规则通过传入函数指定
批量计算

流计算

Netcat 的使用
目标:使用 Spark Streaming 程序和 Socket server 进行交互, 从 Server 处获取实时传输过来的字符串, 拆开单词并统计单词数量, 最后打印出来每一个小批次的单词数量

步骤:
package cn.itcast.streaming import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} object StreamingWordCount { def main(args: Array[String]): Unit = { //1.初始化 val sparkConf=new SparkConf().setAppName("streaming").setMaster("local[2]") val ssc=new StreamingContext(sparkConf,Seconds(5)) ssc.sparkContext.setLogLevel("WARN") val lines: ReceiverInputDStream[String] = ssc.socketTextStream( hostname = "192.168.31.101", port = 9999, storageLevel = StorageLevel.MEMORY_AND_DISK_SER ) //2.数据处理 //2.1把句子拆单词 val words: DStream[String] =lines.flatMap(_.split(" ")) val tuples: DStream[(String, Int)] =words.map((_,1)) val counts: DStream[(String, Int)] =tuples.reduceByKey(_+_) //3.展示 counts.print() ssc.start() ssc.awaitTermination() } }
开始进行交互:
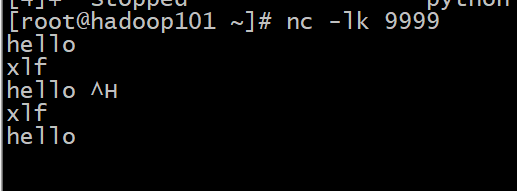

注意:
Spark Streaming 并不是真正的来一条数据处理一条
Spark Streaming 的处理机制叫做小批量, 英文叫做 mini-batch, 是收集了一定时间的数据后生成 RDD, 后针对 RDD 进行各种转换操作, 这个原理提现在如下两个地方
RDD 去统计呢? 由 new StreamingContext(sparkConf, Seconds(1)) 这段代码中的第二个参数指定批次生成的时间Spark Streaming 中至少要有两个线程
在使用 spark-submit 启动程序的时候, 不能指定一个线程
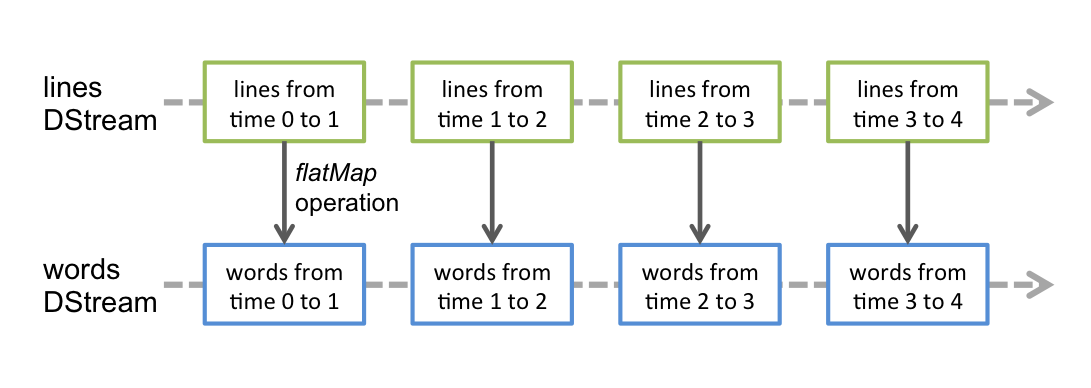
这些算子类似 RDD, 也会生成新的 DStream
这些算子操作最终会落到每一个 DStream 生成的 RDD 中
| 算子 | 释义 |
|---|---|
|
|
将一个数据一对多的转换为另外的形式, 规则通过传入函数指定 |
|
|
一对一的转换数据 |
|
|
这个算子需要特别注意, 这个聚合并不是针对于整个流, 而是针对于某个批次的数据 |
| 编程模型 | 解释 |
|---|---|
|
|
|
|
|
|
|
|
|
Spark Streaming 时代

Spark Streaming 其实就是 RDD 的 API 的流式工具, 其本质还是 RDD, 存储和执行过程依然类似 RDD
Structured Streaming 时代
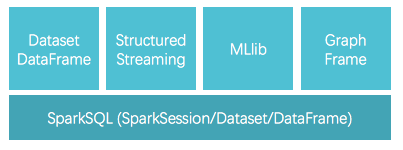
Structured Streaming 其实就是 Dataset 的 API 的流式工具, API 和 Dataset 保持高度一致
Spark Streaming 和 Structured Streaming
Structured Streaming 相比于 Spark Streaming 的进步就类似于 Dataset 相比于 RDD 的进步
另外还有一点, Structured Streaming 已经支持了连续流模型, 也就是类似于 Flink 那样的实时流, 而不是小批量, 但在使用的时候仍然有限制, 大部分情况还是应该采用小批量模式
在 2.2.0 以后 Structured Streaming 被标注为稳定版本, 意味着以后的 Spark 流式开发不应该在采用 Spark Streaming 了
需求
编写一个流式计算的应用, 不断的接收外部系统的消息
对消息中的单词进行词频统计
统计全局的结果
步骤:
package cn.itcast.structured import org.apache.spark.sql.streaming.OutputMode import org.apache.spark.sql.{DataFrame, Dataset, SparkSession} object SocketWordCount { def main(args: Array[String]): Unit = { //1.创建SparkSession val spark=SparkSession.builder().master("local[5]") .appName("structured") .getOrCreate() spark.sparkContext.setLogLevel("WARN") import spark.implicits._ //2.数据集的生成,数据读取 val source: DataFrame =spark.readStream .format("socket") .option("host","192.168.31.101") .option("port",9999) .load() val sourceDS: Dataset[String] = source.as[String] //3.数据的处理 val words=sourceDS.flatMap(_.split(" ")) .map((_,1)) .groupByKey(_._1) .count() //4.结果集的生成和输出 words.writeStream .outputMode(OutputMode.Complete()) .format("console") .start() .awaitTermination() } }
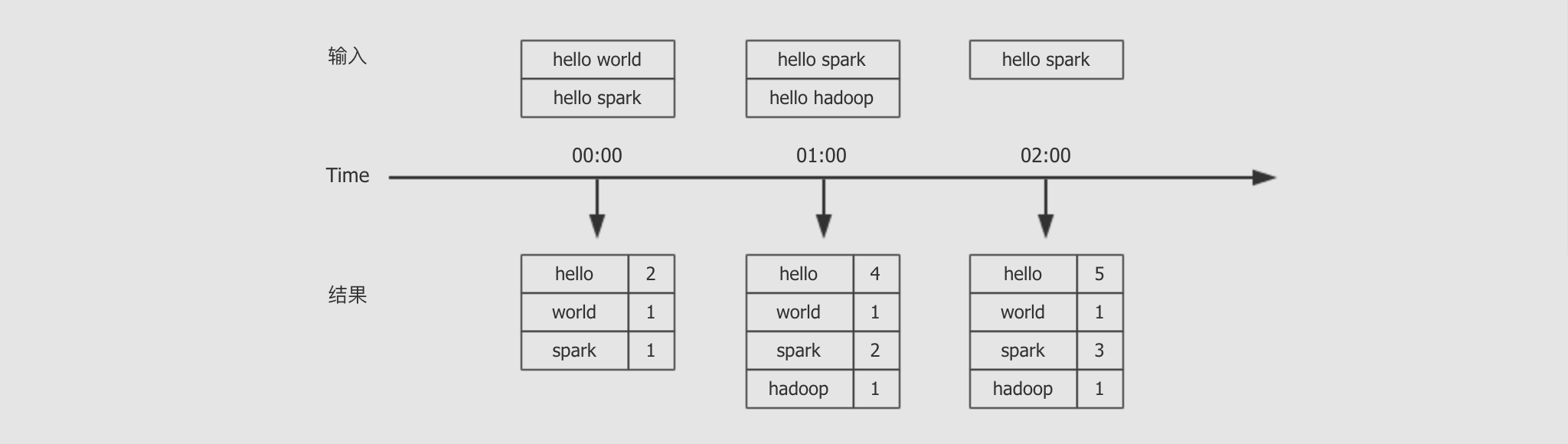
交互结果:
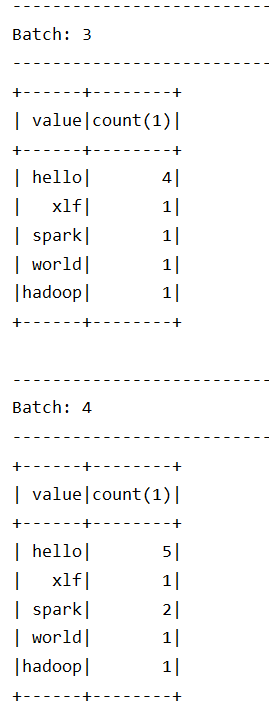
从结果集中可以观察到以下内容
Structured Streaming 依然是小批量的流处理
Structured Streaming 的输出是类似 DataFrame 的, 也具有 Schema, 所以也是针对结构化数据进行优化的
从输出的时间特点上来看, 是一个批次先开始, 然后收集数据, 再进行展示, 这一点和 Spark Streaming 不太一样
使用 Structured Streaming 整合 HDFS, 从其中读取数据的能力
步骤
案例结构
产生小文件并推送到 HDFS
流式计算统计 HDFS 上的小文件
运行和总结
实验步骤:
Step1:利用py产生文件源源不断向hdfs上传文件
Step2:编写 Structured Streaming 程序处理数据
py代码:
import os for index in range(100): content = """ {"name": "Michael"} {"name": "Andy", "age": 30} {"name": "Justin", "age": 19} """ file_name = "/export/dataset/text{0}.json".format(index) with open(file_name, "w") as file: file.write(content) os.system("/export/servers/hadoop-2.7.5/bin/hdfs dfs -mkdir -p /dataset/dataset/") os.system("/export/servers/hadoop-2.7.5/bin/hdfs dfs -put {0} /dataset/dataset/".format(file_name))
spark处理流式文件
package cn.itcast.structured import org.apache.spark.SparkContext import org.apache.spark.sql.SparkSession import org.apache.spark.sql.streaming.OutputMode import org.apache.spark.sql.types.{StructField, StructType} object HDFSSource { def main(args: Array[String]): Unit = { System.setProperty("hadoop.home.dir","C:\\winutil") //1.创建SparkSession val spark=SparkSession.builder() .appName("hdfs_source") .master("local[6]") .getOrCreate() //2.数据读取 val schema=new StructType() .add("name","string") .add("age","integer") val source=spark.readStream .schema(schema) .json("hdfs://hadoop101:8020/dataset/dataset") //3.输出结果 source.writeStream .outputMode(OutputMode.Append()) .format("console") .start() .awaitTermination() } }
总结

Python 生成文件到 HDFS, 这一步在真实环境下, 可能是由 Flume 和 Sqoop 收集并上传至 HDFS
Structured Streaming 从 HDFS 中读取数据并处理
Structured Streaming 讲结果表展示在控制台
Spark学习进度11-Spark Streaming&Structured Streaming
原文:https://www.cnblogs.com/xiaofengzai/p/14284502.html