

#-*- codeing = utf-8 -*-
#@Time : 2021/1/15 20:19
#@Author : 杨晓
#@File : cv_demo.py
#@Software: PyCharm
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# 1、获取数据
iris = load_iris()
# 2、数据处理
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,test_size=0.2,random_state=222)
# 3、特征工程
# 3.1 实例转化器
transfer = StandardScaler()
# 3.2调用fit_transform
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4、机器学习
# 4.1 实例化预估器类
estimator = KNeighborsClassifier()
# 4.2 模型选择与调优——网格搜索和交叉验证
param_dict = {"n_neighbors":[1,3,5,7]}
estimator = GridSearchCV(estimator,param_grid=param_dict,cv=5)
# 4.3 训练模型
estimator.fit(x_train,y_train)
# 5、模型评估
y_predict = estimator.predict(x_test)
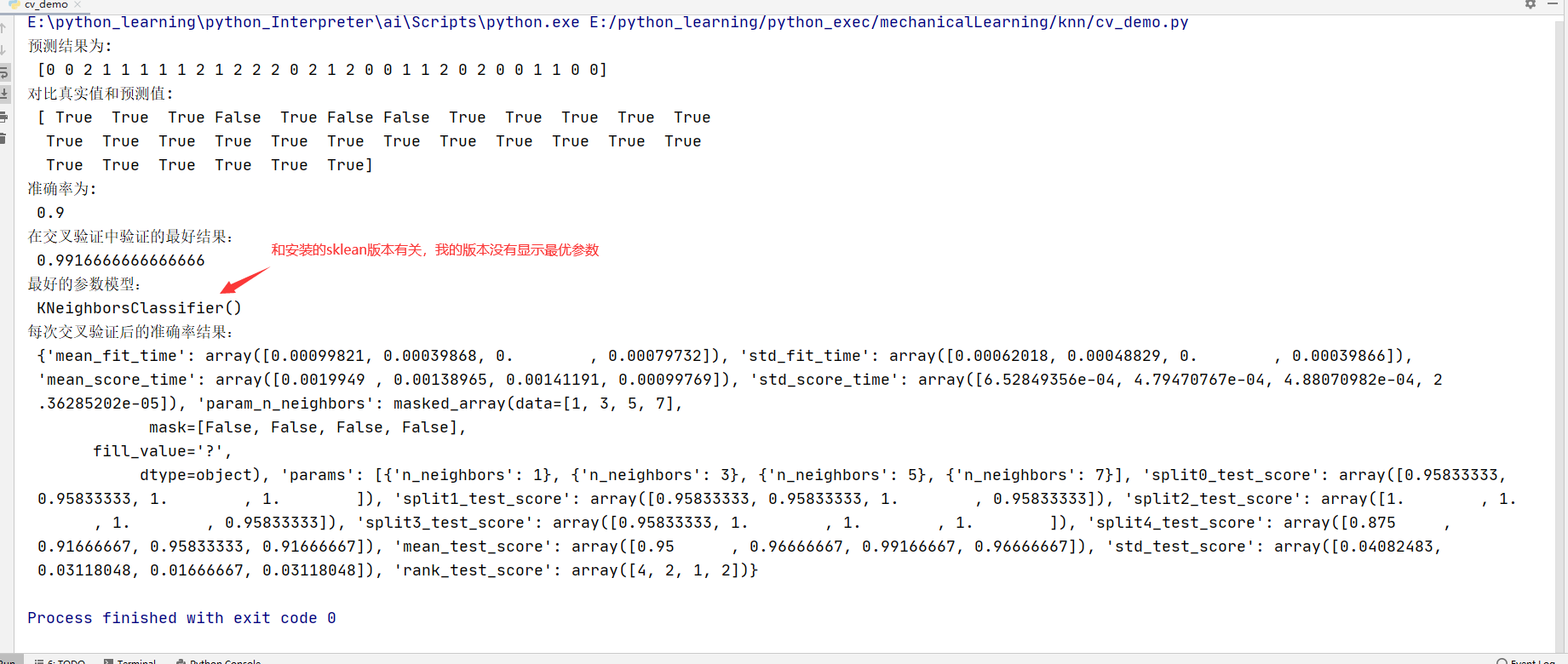
print("预测结果为:\n",y_predict)
print("对比真实值和预测值:\n",y_predict == y_test)
score = estimator.score(x_test,y_test)
print("准确率为:\n",score)
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
print("每次交叉验证后的准确率结果:\n", estimator.cv_results_)
原文:https://www.cnblogs.com/yangxiao-/p/14284394.html