base适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正是因为Hbase良好的扩展性(存储在HDFS),才为海量数据的存储提供了便利。
特点
1.海量存储:适合存储PB级别的海量数据
2.列式存储:列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3.极易扩展:Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)(通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。)
4.高并发:由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5.稀疏:稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
HBASE的应用场景
不适合:需要数据分析,比如报表。 因为会存在行数据不完整情况
单表数据在千万级别以下
适合: 单表唱过千万,并发量很高,数据分析需求弱,或者不需要那么灵活和实时。
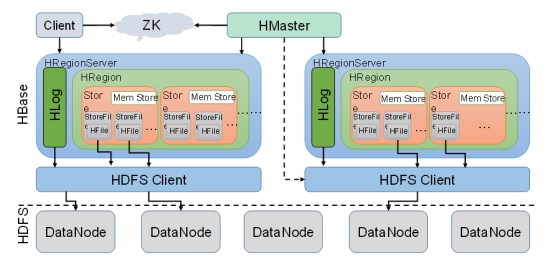
HBASE: 弱化HMaster功能,让HMaster管理多个RegionServer.元数据在HMaster中。将元数据注册到zookepeer中,客户端访问时候直接访问zookepeer。如果HMaster宕机,我们从zookepeer中拿取元数据,然后通过元数据去RegionServer拿到数据。所以当HMaster宕机是不影响整个过程。HBASE安装需要zookepeer工具提供。
安装前提:hdfs zookepeer已经安装完毕。
下载hbase
解压
tar -zxvf hbase-1.2.6-bin.tar.gz
更改conf下hbase-env.sh环境
cd hbase-1.2.6/conf/
vim hbase-env.sh
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64/
# 将内部的zookepeer关掉,使用自己的
export HBASE_MANAGES_ZK=false
配置hbase-site.xml 文件
vim hbase-site.xml
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://linux01:9000/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>linux01:2181,linux02:2181,linux03:2181</value>
</property>
</configuration>
配置regionserver 集群的机器
linux01
linux02
linux03
时间同步,HBASE数据同步,时间要求一致
配置HBASE环境变量
vim /etc/profile
export HBASE_HOME=/opt/hdp/hbase-1.2.6
export PATH=$HADOOP_HOME/sbin:$HBASE_HOME/bin
source /etc/profile
安装完的hbase分发linux02 linux03
scp -r hbase-1.2.6 linux02:$PWD
scp -r hbase-1.2.6 linux03:$PWD
启动zookepeer
/opt/zookeeper-3.4.6/bin/zkServer.sh start /opt/zookeeper-3.4.6/conf/zoo.cfg
启动dfs
[root@linux01 bin]# start-dfs.sh
linux01---->master启动hbase
hbase-daemon.sh start master
启动linux01 regionserver
hbase-daemon.sh start regionserver
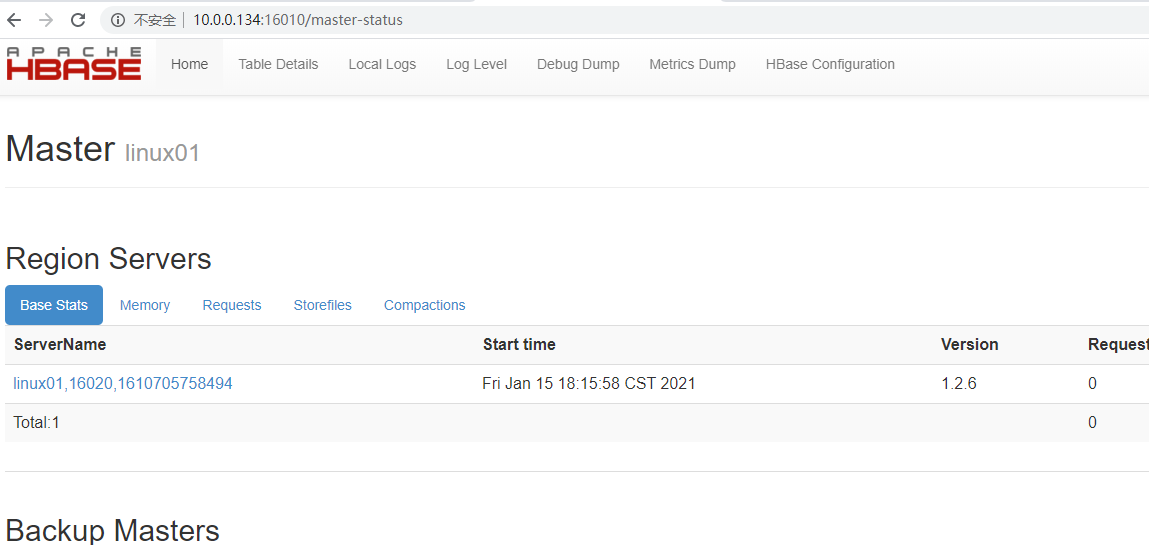
输入网址http://10.0.0.134:16010/master-status如下图启动完毕
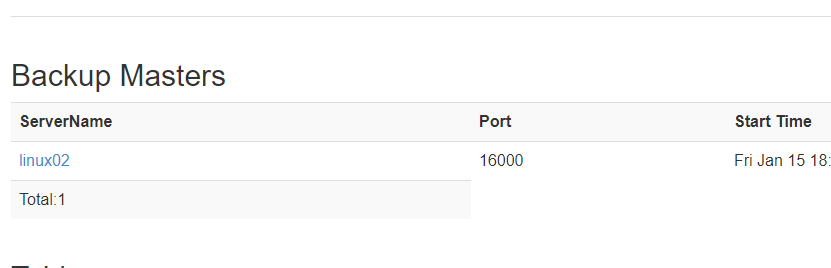
在linux02启动master,会将其作为备用master
hbase-daemon.sh start master
单节点启动
# region停止
hbase-daemon.sh stop regionserver
# region启动
hbase-daemon.sh start regionserver
# master停止
hbase-daemon.sh stop master
# master启动
hbase-daemon.sh start master
一键启停
会加载regionservers文件配置的节点启动resionserver
start-hbase.sh
stop.hbase.sh
注意出现如下警告:

解决:
vim /opt/hdp/hbase-1.2.6/conf/hbase-env.sh
删除如下两行:
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
# 仅仅是针对JDK7 JDK8中做了优化。所以这两行可以删除
如果启动失败:1检查时间是否同步,2检查zookepeer和hdfs是否启动成功
hbase的表模型跟mysql之类的关系型数据库的表模型差别巨大.
hbase的表模型种有:行的概念,列族的概念,但没有字段的概念.
行种村的都是key-value对,每行种的key-value对中的key可以是各种各样的,每行中的key-value对的数量也可以是各种各样.
Hbase表模型要点:
1.一个表,有表名
2.一个表可以分为多个列族.(不同列族的数据会存储在不同文件中)
3.表中的每一行有一个 "行键rowkey" 行键在表中不能重复(类似mysql主键),它是定长的.
4.表中每一对kv数据称位一个cell
5.hbase可以对数据存储多个历史版本(历史版本数量可配置)
6.整张表由于数据量过大,会被横向切分成若干个region(用rowkey范围标识),不同region数据也存储在不同文件中.
7.hbase会对插入数据按顺序存储.
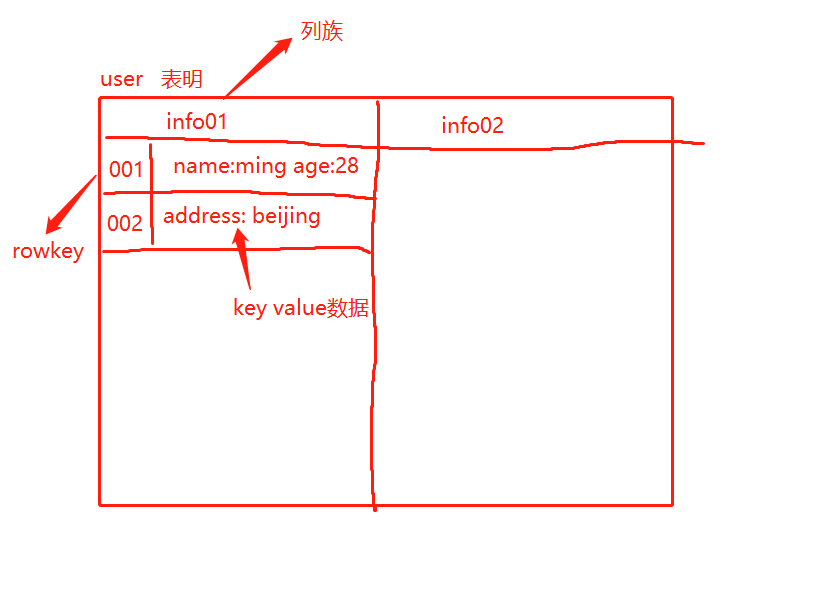
存储示例:
rowkey|columnFamily|key|value
而且hbase会对存入的keyvalue数据自动排序,排序规则如下:
先按行键,再按列族名,再按key名 进行排序(字典顺序逐,字节比较)
如下图:
hbase连接客户端
hbase shell
xshell配置(xshell操作客户端无法删除,需要对xshell配置)
文件 -->属性-->终端-->键盘
在 DELETE键序列 和 BACKSPACE键序列 中都选择 ASCII 127
1.查看版本
version
2.查看hbase的状态
staus
3.查看当前用户信息
whoami
4.查看表的帮助信息
table_help
# 创建tb_user表,列族为info
create ‘tb_user‘ , ‘info‘
create ‘tb_user2‘ , ‘info1‘, ‘info2‘
hbase(main):010:0> list
TABLE
tb_user
1 row(s) in 0.0530 seconds
=> ["tb_user"]
# 正则查询(匹配tb开头的表)
list "tb.*"
hbase(main):012:0> desc ‘tb_user‘
Table tb_user is ENABLED #表示可用的
tb_user
COLUMN FAMILIES DESCRIPTION
{NAME => ‘info‘, BLOOMFILTER => ‘ROW‘, VERSIONS => ‘1‘, IN_MEMORY => ‘false‘, KEEP_DELETED
_CELLS => ‘FALSE‘, DATA_BLOCK_ENCODING => ‘NONE‘, TTL => ‘FOREVER‘, COMPRESSION => ‘NONE‘,
MIN_VERSIONS => ‘0‘, BLOCKCACHE => ‘true‘, BLOCKSIZE => ‘65536‘, REPLICATION_SCOPE => ‘0‘
}
1 row(s) in 4.2550 seconds
# 字段意义
NAME 列族名
TTL 过期时间
BLOCKSIZE 大小
put ‘tb_user‘ , ‘rowkey001‘ , ‘info:age‘, 25
put ‘tb_user‘ , ‘rowkey001‘ , ‘info:name‘ , ‘ming‘
表名 行键 列族:属性(列) 值
# 扫描全表的内容
hbase(main):019:0> scan "tb_user"
ROW COLUMN+CELL
rowkey001 column=info:age, timestamp=1610722955208, value=25
rowkey001 column=info:name, timestamp=1610722885973, value=ming
1 row(s) in 0.0250 seconds
# 显示tb_user前2行数据
scan "tb_user" , {LIMIT=>2}
# 显示tb_user前2行数据 从rowkey002开始
scan "tb_user" , {STARTROW=>‘rowkey002‘,LIMIT=>2}
# 显示tb_user 从 rowkey002 到 rowkey005 数据 不包含rowkey005
scan "tb_user" , {STARTROW=>‘rowkey002‘,STOPROW=>"rowkey005"}
hbase(main):027:0> flush ‘tb_user‘
# 获取表tb_user 键为rowkey001数据
get "tb_user" , "rowkey001"
# 获取表tb_user 键为rowkey001的name数据
get "tb_user" , "rowkey001" , "info:name"
# 获取表tb_user 键为rowkey001,列族info的数据
get "tb_user" , "rowkey001" , "info"
# tb_user表下新增info2列族
alter "tb_user" , "info2"
alter "tb_user" ,"delete"=> "info2"
delete "tb_user2", "rowkey002" , "info2:name"
disable "tb_user2"
disable "tb_user2"
is_disabled "tb_user2"
# 删除tb开头表
drop_all "tb.*"
# 停用tb开头表
disable_all "tb.*"
drop "tb_user2"
# 删除表前先将表停用
enable "tb_user2"
# 将tb_user2 新建名为info快照
snapshot "tb_user2", "info"
list_snapshots
# 先禁用
disable "tb_user"
restore_snapshot "info" #info为快照名
enable "tb_user"
scan "tb_user"
clone_snapshot "info" , "t_test2"
快照名 表名(新表没有创建过的)
count "tb_user2"
exists "tb_user2"
locate_region "tb_user", "info"
我们知道数据存储在RegionServer 中,当一个RegionServer存储数据是有限制的,一旦超出限制会对数据进行拆分,存储到其他机器中(Regionserver)中,当然一个RegionServer内有多个Region (比如有user表,order表...),数据真正存储在Store(Store可以认为是一个列族)中,刚开始数据不到128M会存储在内存中(memStore,memStore可以有效帮助我们提高查询速度),而数据在内存中一旦宕机可能会引起数据丢失,通过日志(logfile)可解决此问题。它会先写在一个叫Write-Ahead logfile的文件中,然后再写到内存中。一旦数据占用空间到128M会flush刷入文件(HFile)中.当然你也可以人为去flush,所有的关键在于rowKey范围,rowKey范围决定了我们数据存储在不同机器上,如果rowkey设计不合理,则会导致数据倾向。
其内部优化:当你执行大量flush会形成大量小文件,它的内部会进行文件合并,同样当你进行大量删除,它也会进行相同操作。
package xjk.com.hbase;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
public class TestClient {
static Connection conn = null;
static {
try {
// 创建初始化的配置对象
Configuration conf = HBaseConfiguration.create();
// 设置ZK集群位置
conf.set("hbase.zookeeper.quorum", "10.0.0.134:2181,10.0.0.131:2181,10.0.0.132:2181");
// 获取连接对象
conn = ConnectionFactory.createConnection(conf);
// 管理对象 对表操作
} catch (Exception e) {
e.printStackTrace();
}
}
/*
* 判断表是否存在
* @param tbName 表名
* */
public static boolean tableExists(String tbName) throws Exception {
Admin admin = conn.getAdmin();
return admin.tableExists(TableName.valueOf(tbName));
}
/*
* 创建表
* @param tbName 表名
* @param cfs String ... 方法可变参数:列族
* */
public static void createTable(String tbName, String ...cfs) throws Exception {
Admin admin = conn.getAdmin();
if (!tableExists(tbName)) {
// 创建表描述对象
HTableDescriptor tbd = new HTableDescriptor(TableName.valueOf(tbName));
// 遍历创建列族
for (String cf : cfs) {
HColumnDescriptor family = new HColumnDescriptor(cf.getBytes());
// 添加列族
tbd.addFamily(family);
}
// 生成表
admin.createTable(tbd);
System.out.println(tbName + "创建成功");
} else {
System.out.println(tbName + "表已经存在");
}
}
/*
* 删除表
* @param tbName 表名
* */
public static void deleteTable(String tbName) throws Exception {
Admin admin = conn.getAdmin();
if (tableExists(tbName)) {
// 禁用表
admin.disableTable(TableName.valueOf(tbName));
admin.deleteTable(TableName.valueOf(tbName));
System.out.println("删除" + tbName + "成功");
} else {
System.out.println("删除" + tbName + "失败");
}
}
/*
* 添加一行数据 (windows本地要配置hosts文件否则插入数据阻塞)
* @param tbName 表名
* @param rk 行键
* @param cf 列族
* @param key 键
* @param value 值
* */
public static void addValue(String tbName, String rk, String cf, String key, String value) throws Exception {
Table table = conn.getTable(TableName.valueOf(tbName));
Put put = new Put(rk.getBytes());;
// 参数1:列族, 参数2:key 参数3:value
put.addColumn(cf.getBytes(), key.getBytes(), value.getBytes());
table.put(put);
System.out.println("创建数据成功");
}
/*
* 查询获取表数据(按照行范围)
* @param tbName 表名
* */
public static void getAllData(String tbName, String start, String end) throws Exception {
Table table = conn.getTable(TableName.valueOf(tbName));
// 创建Scan对象
Scan scan = new Scan();
// 设置起始行
scan.setStartRow(Bytes.toBytes(start));
// 设置结束行(不包含当前行)
scan.setStopRow(Bytes.toBytes(end));
// 将数据转换成字节
// byte[] bytes = Bytes.toBytes("");
// 全表扫描
ResultScanner scanner = table.getScanner(scan);
// 遍历每行单元格
for (Result result : scanner) {
// 获取行单元格 行的单元格个数不一定一致
Cell[] rawCells = result.rawCells();
for (Cell cell: rawCells) {
// 行键
System.out.print(new String(CellUtil.cloneRow(cell)) + "--");
// 列族
System.out.print(new String(CellUtil.cloneFamily(cell)) + "--");
// 键(属性)
System.out.print(new String(CellUtil.cloneQualifier(cell)) + "--");
// 值
System.out.print(new String(CellUtil.cloneValue(cell)));
System.out.println();
}
}
}
public static void addValues(String tbName, String rk, String cf, String key, String value) throws Exception {
Table table = conn.getTable(TableName.valueOf(tbName));
Put put2 = new Put(rk.getBytes());
// 参数1:列族, 参数2:key 参数3:value
put2.addColumn(cf.getBytes(), key.getBytes(), value.getBytes());
List<Put> list = new ArrayList<>();
list.add(put2);
table.put(list);
System.out.println("创建数据成功");
}
/*
* 查询表的某个行的列族数据
* @param tbName 表名
* @param rk 行键
* @param cf 列族
* */
public static void getDataByRkAndCf(String tbName, String rk, String cf) throws Exception {
Table table = conn.getTable(TableName.valueOf(tbName));
// 获取行get对象
Get get = new Get(rk.getBytes());
// 指定列族
get.addFamily(cf.getBytes());
Result result = table.get(get);
Cell[] rawCells = result.rawCells();
// 遍历
for (Cell cell : rawCells) {
// 行键
System.out.print(new String(CellUtil.cloneRow(cell)) + "--");
// 列族
System.out.print(new String(CellUtil.cloneFamily(cell)) + "--");
// 键(属性)
System.out.print(new String(CellUtil.cloneQualifier(cell)) + "--");
// 值
System.out.print(new String(CellUtil.cloneValue(cell)));
System.out.println();
}
}
/*
* 查询某个具体属性值
* @param tbName 表名
* @param rk 行键
* @param cf 列族
* @param cf 键
* */
public static void getDataByKey(String tbName, String rk, String cf, String key) throws Exception {
Table table = conn.getTable(TableName.valueOf(tbName));
Get get = new Get(rk.getBytes());
// 设置列族和属性
get.addColumn(cf.getBytes(), key.getBytes());
Result result = table.get(get);
Cell[] rawCells = result.rawCells();
// 遍历
for (Cell cell : rawCells) {
// 行键
System.out.print(new String(CellUtil.cloneRow(cell)) + "--");
// 列族
System.out.print(new String(CellUtil.cloneFamily(cell)) + "--");
// 键(属性)
System.out.print(new String(CellUtil.cloneQualifier(cell)) + "--");
// 值
System.out.print(new String(CellUtil.cloneValue(cell)));
System.out.println();
}
}
/*
* 删除某个行数据
* @param tbName 表名
* @param rk 行键
* */
public static void deleteByRow(String tbName,String rk) throws Exception {
Table table = conn.getTable(TableName.valueOf(tbName));
Delete d = new Delete(rk.getBytes());
table.delete(d);
}
/*
* 删除多个行数据
* @param tbName 表名
* @param rk 行键
* */
public static void deleteByRows(String tbName,String... rks) throws Exception {
Table table = conn.getTable(TableName.valueOf(tbName));
List <Delete> list = new ArrayList<>();
for (String rk : rks) {
Delete d = new Delete(rk.getBytes());
list.add(d);
}
table.delete(list);
}
public static void main(String[] args) throws Exception {
// 判断表是否存在
// System.out.println(tableExists("tb_user"));
// 创建表
// createTable("demo2", "info1","info2");
// 删除表
// deleteTable("demo2");
// 创建数据
// addValue("demo2", "rowkey005", "info1", "address", "beijing");
// 获取全表数据
// getAllData("demo2", "rowkey002", "rowkey004");
// 查询表的某个行的列族数据
// getDataByRkAndCf("demo2", "rowkey002", "info1");
// 查询某个具体属性值
// getDataByKey("demo2", "rowkey002", "info1", "name");
// 删除行数据
// deleteByRow("demo2", "rowkey005");
// 删除多个行数据
deleteByRows("demo2", "rowkey004", "rowkey003");
}
}
基础API中查询操作在面对大数据时候比较苍白,这里Hbase提供高级的查询方法:Filter,它可以根据簇,列,版本等更多的条件来对数据进行过滤,基于Hbase本身提供三维有序(主键有序,列有序,版本有序),这些Filter可以高效完成查询过滤的任务,带有Filter条件的RPC查询请求会把Filter分发各个RegionServer,是一个服务端的过滤器,这样可以降低网络传输的压力。
要完成一个过滤的操作,至少需要两个参数,一个是抽象的操作复,Hbase提供了枚举类型的变量来标识这些抽象操作符:LESS/LESS_OR_EQUAL/EQUAL/NOT_EQUAL等。另外一个就是具体的比较器。代表具体的比较逻辑,如可以提高字节级的比较,字符串级比较等,有了这两个参数,我们就可以清除的定义筛选的条件,过滤数据。
抽象操作符(比较运算符)
LESS <
LESS_OR_EQUAL <=
EQUAL =
NOT_EQUAL <>
GREATER_OR_EQUAL >=
GREATER >
NO_OP 排除所有
比较器(指定比较机制)
BinaryComparator 按字节索引顺序比较指定字节数组,采用 Bytes.compareTo(byte[])
BinaryPrefixComparator 跟前面相同,只是比较左端的数据是否相同
NullComparator 判断给定是否为空
BitComparator 按位比较
RegexStringComparator 提供一个正则的比较器 仅支持EQUAL 和 非EQUAL
SubstringComparator 判断提供的子串是否出现在value中
过滤器种类:
过滤 判断子串行键是否包含rk
Filter filter = new RowFilter(CompareOp.EQUAL, new SubstringComparator("rk"));
Filter filter = new FamilyFilter(CompareOp.EQUAL, new BinaryComparator("info1".getBytes()));
Filter filter = new QualifierFilter(CompareOp.EQUAL, new BinaryComparator("age".getBytes()));
Filter filter = new ValueFilter(CompareOp.EQUAL, new BinaryComparator("xjk".getBytes()));
Filter filter = new SingleColumnValueFilter("info2".getBytes(), "name".getBytes(),CompareOp.EQUAL, new BinaryComparator("xjk".getBytes()));
//rk开头
Filter filter = new PrefixFilter("rk".getBytes());
// 所有有name的列(key)
Filter filter = new ColumnPrefixFilter("name".getBytes());
读取数据
master注册元数据到zookpeer,客户端请求去zookepeer找到元数据,然后根据元数据去找到对应存储数据的region,在region中先从内存中找(memStore),没有找到会再去缓存中找(CacheStore),缓存中没有才会去文件中找(HFile),当从HFile找到数据时候,它会将找到数据再放到CacheStore,下次找的时候更快。当然缓存中保存数据方式是堆外内存,因为堆内内存会存在溢出现象,但堆外内存不好管理,它内部做了一个优化-->(堆外内存+固态磁盘内存)。
写数据
向hbase表中添加数据,首先master将元数据注册到zookepeer中,master管理着多个RegionServer,master中有一个meta它记录每张表存储范围。 当客户端向zookepeer请求写操作,会返回meta,meta告诉往哪写,客户端会往region写数据,而region会有Hlog,Hlog会操作HDFS客户端进行持久化操作。同时数据也往内存中写(memstore),当你文件到达128M时候会触发flush。flush会生成一个HFile,生成HFile操作HDFS客户端进行持久化。当HDFS将数据持久化后,它会将刷新成功后数据的Hlog记录删掉。将当然一个Region有多个列族(Store),
因HDFS不支持随机访问,所有数据都是写操作(追加),当你执行删除,也是执行添加操作,
# put rk001 "abc"
# 删除: rk001 "" [delete]
***当我们执行查询时候,发现会根据墓碑标记的数据,进行合并。修改操作特使一样会维护内部一个版本。
设计要根据维度查询频率进行设计,设计rowkey要定长且唯一。比如如下:
我们对rowkey设计 (userID(6位) + time(8位) + fileID(6位))
000001 20180501 000001
000001 20180501 000002
000001 20180502 000003
000001 20180503 000003
000002 20180501 000001
000002 20180501 000002
...
当用户id相同我们可以根据用户 + 时间进行查询排序,当用户和时间相同我们可以进行用户+时间+文件id进行查询排序
? 在建立一个scan对象后,我们setStartRow(0000012018050 000001),setEndRow(000001 20180503 000003).这样,scan时只扫描userID=1的数据,且时间范围限定在这个指定时间段内,满足按用户以及按时间范围对结果的筛选,并且由于记录集中存储,性能会很好。
? 然后使用SingleColumnValueFilter 分别约束name的上下限,于category的上下限,满足按同时按文件名以及分类名的前缀匹配。
Phoenix由saleforce.com开源的一个项目,后又捐给了Apache。它相当于一个Java中间件,帮助开发者像使用JDBC访问关系型数据库一样,访问NoSQL数据库HBase.
下载
http://phoenix.apache.org/download.html
安装:
tar -zxvf apache-phoenix-4.14.0-HBase-1.2-bin.tar.gz
将phoenix-4.14.0-HBase-1.2-server.jar赋值hbase 的lib下
cp phoenix-4.14.0-HBase-1.2-server.jar /opt/hdp/hbase-1.2.6/lib
将phoenix-4.14.0-HBase-1.2-server.jar 包发送给其他节点的lib目录下
scp phoenix-4.14.0-HBase-1.2-server.jar linux02:/opt/hdp/hbase-1.2.6/lib
scp phoenix-4.14.0-HBase-1.2-server.jar linux03:/opt/hdp/hbase-1.2.6/lib
重启HBASE
stop-hbase.sh
start-hbase.sh
连接phoenix
# 到 /root/apache-phoenix-4.14.0-HBase-1.2-bin/bin 目录下
# 连接
./sqlline.py 10.0.0.134,10.0.0.131,10.0.0.132:2181
这样你可以像操作mysql一样操作hbase了
常用指令
1.显示所有表
!table
2. 退出
!quit
3.查看表结构
!describe "表名"
4.创建表
create table user(name varchar not null primary key, age varchar)salt_buckets=16;
5.插入数据
upsert into user values(‘liutao‘,‘25‘);
6.查询
select * from user;
7.删除
delete from user where name = ‘liutao‘;
查询数据支持:union all, group by, order by, limit 都支持
原文:https://www.cnblogs.com/xujunkai/p/14287418.html