CountVectorizer作用:对文本数据进行特征值化
sklearn.feature_extraction.text.CountVectorizer(stop_words=[])
我们对以下数据进行特征提取
["life is short,i like python",
"life is too long,i dislike python"]
具体步骤:
def count_demo():
"""
文本特征抽取:CountVectorizer
:return: None
"""
data = ["life is short,i like like python", "life is too long,i dislike python"]
#实例化转换器
transfer=CountVectorizer(stop_words=["is","too"])
#调用fit_transform
data_new=transfer.fit_transform(data)
print("data_new:\n",data_new.toarray())
print("返回特征名字:\n", transfer.get_feature_names())
return None
返回结果:

接下来将英文换成中文
def count_chinese_demo():
"""
中文文本特征抽取:CountVectorizer
:return: None
"""
data = ["我 爱 北京 天安门", "天安门 上 太阳 升"]
#实例化转换器
transfer=CountVectorizer()
#调用fit_transform
data_new=transfer.fit_transform(data)
print("data_new:\n",data_new.toarray())
print("返回特征名字:\n", transfer.get_feature_names())
return None
结果是:

可见不支持单个中文,需用空格分割,如若不进行分割,会把整个句子来作为特征处理
然后手动分词实现是不太可能的,我们采用jieba进行分词
jieba分词:
def cut_word(text):
text=" ".join(list(jieba.cut(text)))
return text
def count_chinese_demo2():
"""
中文文本特征抽取,自动分词
:return: None
"""
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
text_new=[]
for item in data:
text_new.append(cut_word(item))
#实例化转换器
transfer=CountVectorizer(stop_words=["一种","所以"])
#调用fit_transform
data_new=transfer.fit_transform(text_new)
print("data_new:\n",data_new.toarray())
print("返回特征名字:\n", transfer.get_feature_names())
return None
实例化容器中加入:stop_words的目的是去除没有太大意义的词
结果为:

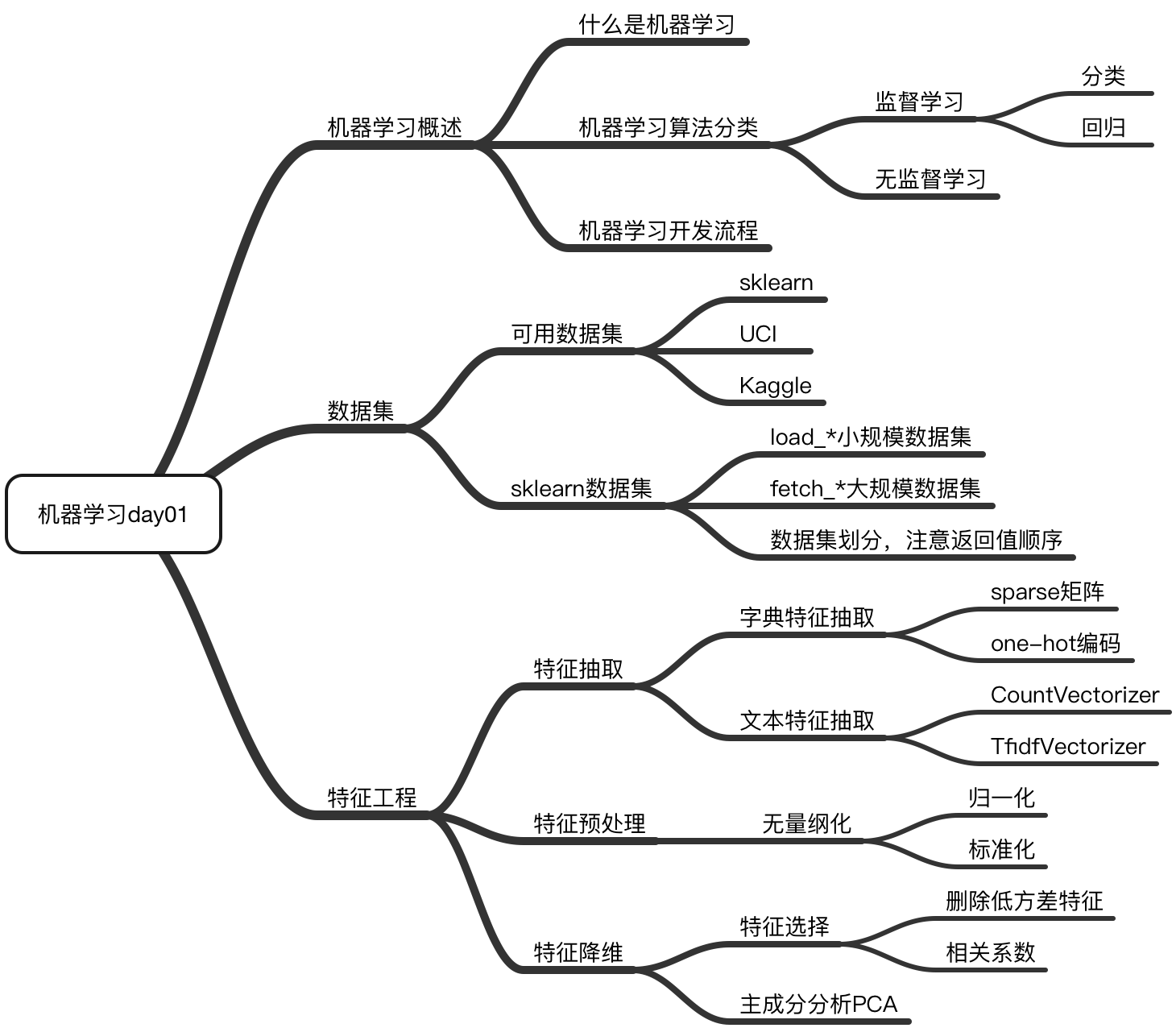
公式
案例
def tfidf():
"""
用TF-IDF的方法进行文本特征抽取
"""
data = ["一种还是一种今天很残酷,明天更残酷,后天很美好,但绝对大部分是死在明天晚上,所以每个人不要放弃今天。",
"我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。",
"如果只用一种方式了解某样事物,你就不会真正了解它。了解事物真正含义的秘密取决于如何将其与我们所了解的事物相联系。"]
text_new = []
for item in data:
text_new.append(cut_word(item))
# 实例化转换器
transfer = TfidfVectorizer(stop_words=["一种", "所以"])
# 调用fit_transform
data_new = transfer.fit_transform(text_new)
print("data_new:\n", data_new.toarray())
print("返回特征名字:\n", transfer.get_feature_names())
return None
结果如下:

总结
他所反映的是这些词的重要性,主要应用于机器学习算法进行文章分类中前期数据处理方式
from sklearn.preprocessing import MinMaxScaler,StandardScaler
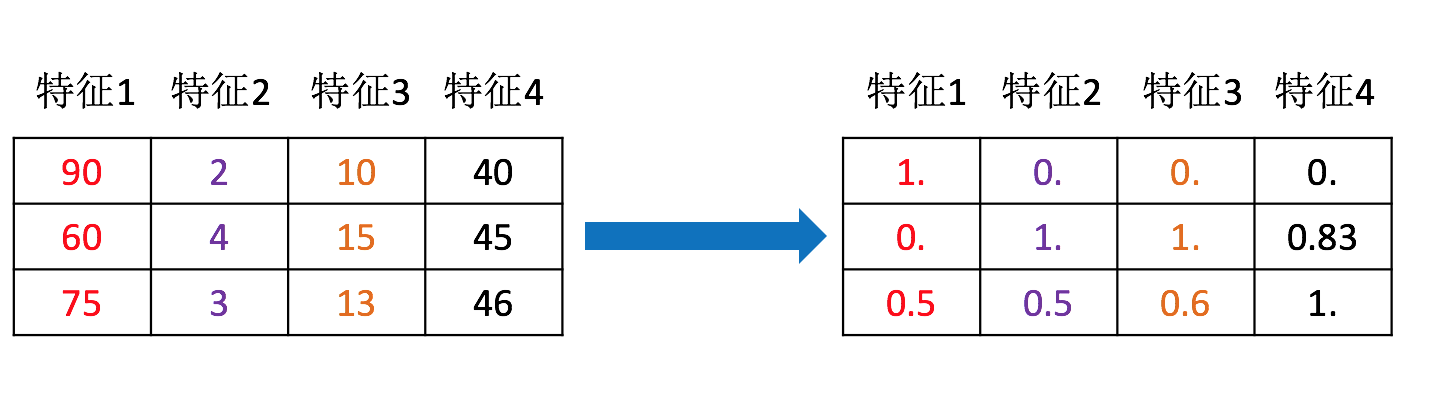
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
通过对原始数据进行变换把数据映射到(默认为[0,1])之间
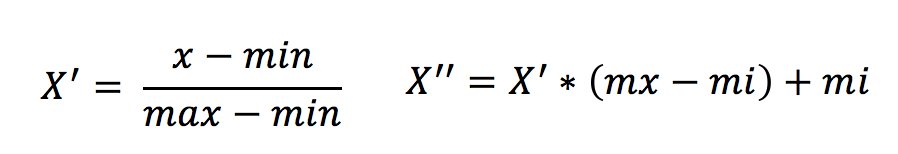
作用于每一列,max为一列的最大值,min为一列的最小值,那么X’’为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
def minmax_demo():
"""
归一化
"""
#1.获取数据
data=pd.read_csv("datingTestSet2.txt", sep=‘,‘)
data=data.iloc[:,:3]
#2.实例化一个转换器,范围在0-1
transfer = MinMaxScaler(feature_range=[0,1])
#3.调用fit_transform
data_new=transfer.fit_transform(data)
print("data_new:\n",data_new)
print("特征:\n",data.columns)
return None
结果如下:
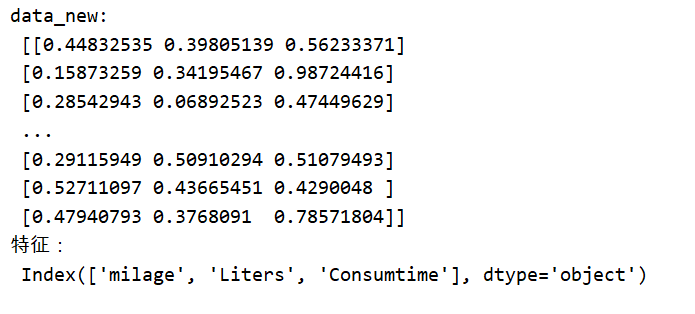
注意最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景。
通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内
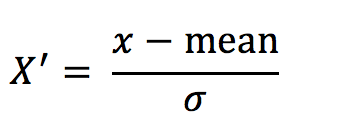
作用于每一列,mean为平均值,σ为标准差
所以回到刚才异常点的地方,我们再来看看标准化
def stand_demo():
"""
归一化
"""
#1.获取数据
data=pd.read_csv("datingTestSet2.txt", sep=‘,‘)
data=data.iloc[:,:3]
#2.实例化一个转换器
transfer = StandardScaler()
#3.调用fit_transform
data_new=transfer.fit_transform(data)
print("data_new:\n",data_new)
print("每一列特征的平均值:\n", transfer.mean_)
print("每一列特征的方差:\n", transfer.var_)
return None
结果如下:

在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
数据中包含冗余或无关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。
from sklearn.feature_selection import VarianceThreshold
删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度。
难点:在于掌握阈值的大小,来进行合理的控制低方差的过滤
反映变量之间相关关系密切程度的统计指标
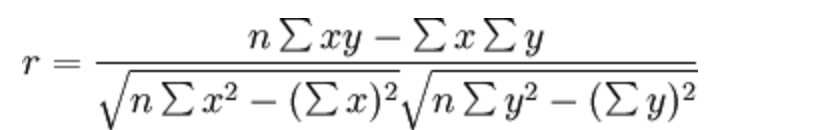
相关系数的值介于–1与+1之间,即–1≤ r ≤+1。
一般可按三级划分:|r|<0.4为低度相关;0.4≤|r|<0.7为显著性相关;0.7≤|r|<1为高度线性相关
#低方差过滤
def variance_demo():
"""
删除低方差特征——特征选择
:return: None
"""
data = pd.read_csv("factor_returns.csv")
data=data.iloc[:,1:-2]
print("data:\n",data)
# 1、实例化一个转换器类
transfer = VarianceThreshold(threshold=10)
# 2、调用fit_transform
data_new = transfer.fit_transform(data)
print("date_new:\n", data_new)
print("形状:\n", data_new.shape)
#计算两个变量之间的相关系数
r=pearsonr(data["pe_ratio"],data["pb_ratio"])
print("相关系数:\n",r)
r2=pearsonr(data["revenue"],data["total_expense"])
print("revenue与total_expense之间的相关性:\n",r2)
plt.figure(figsize=(20,8),dpi=100)
plt.scatter(data["revenue"],data["total_expense"])
plt.show()
return None
定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。

假设对于给定5个点,数据如下
(-1,-2)
(-1, 0)
( 0, 0)
( 2, 1)
( 0, 1)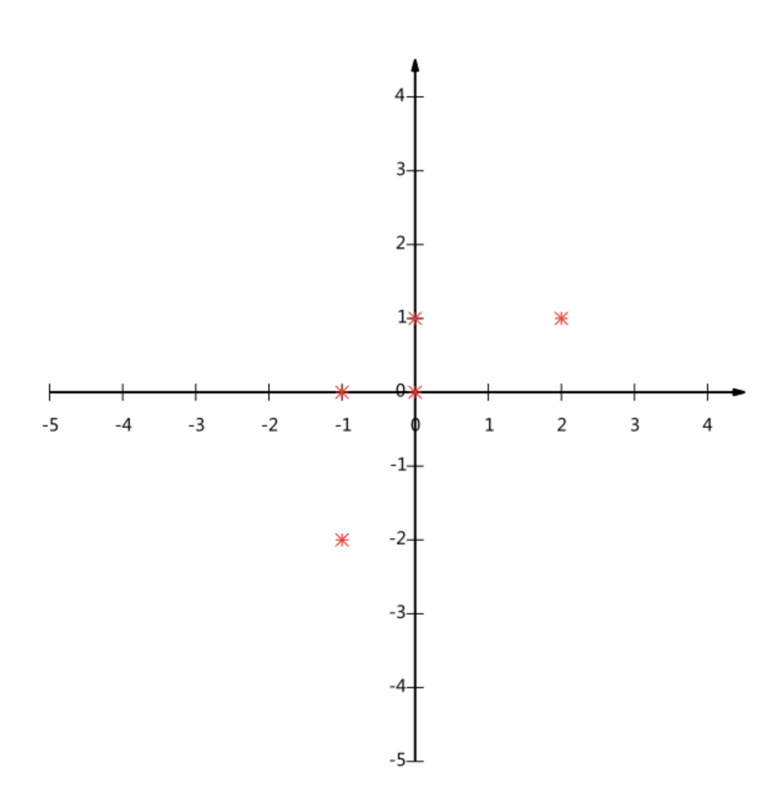
要求:将这个二维的数据简化成一维? 并且损失少量的信息
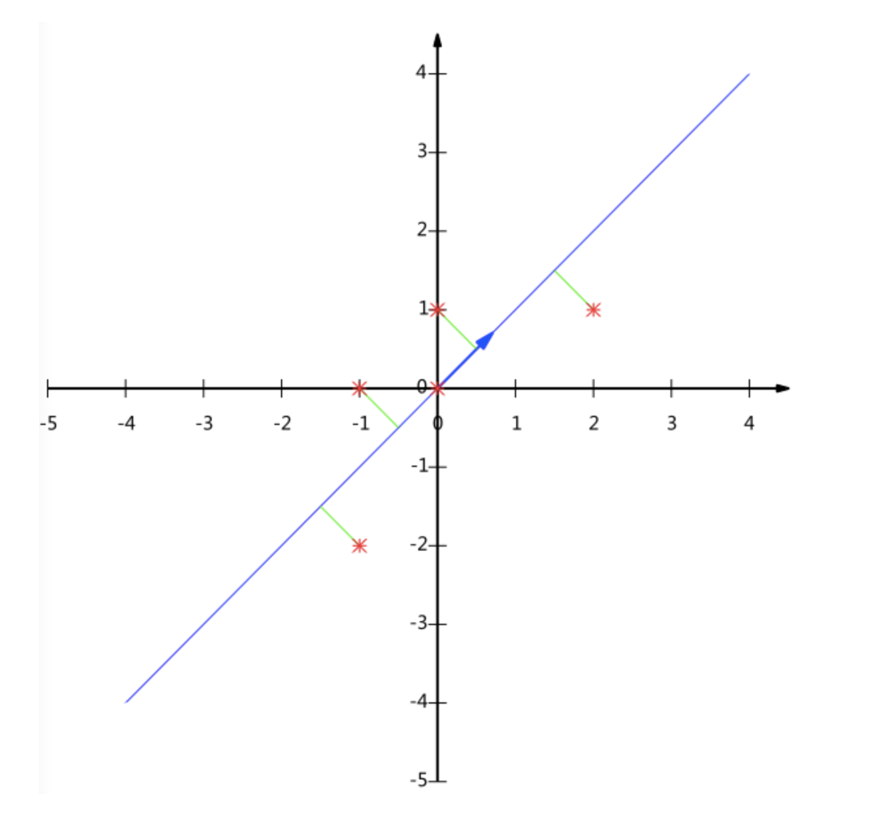
这个过程如何计算的呢?找到一个合适的直线,通过一个矩阵运算得出主成分分析的结果(不需要理解)

def pca_demo():
"""
pca降维
"""
data=[[2,8,4,5],[6,3,0,8],[5,4,9,1]]
#实例化一个转换器
transfer=PCA(n_components=0.95)
#调用fit_transform
data_new=transfer.fit_transform(data)
print("保留95%的信息,降维结果为:\n",data_new)
# 1、实例化PCA, 整数——指定降维到的维数
transfer2 = PCA(n_components=3)
# 2、调用fit_transform
data2 = transfer2.fit_transform(data)
print("降维到3维的结果:\n", data2)
return None
结果如下:

原文:https://www.cnblogs.com/xiaofengzai/p/14290458.html