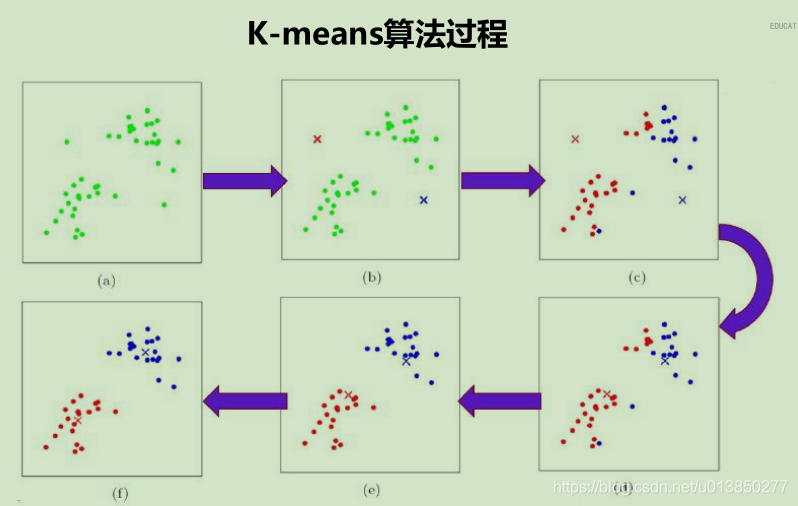
由上述Demo可知,对于KMean算法来说有三个比较重要的因素要考虑,分别如下所述;
K值的选择: k 值对最终结果的影响至关重要,而它却必须要预先给定。给定合适的 k 值,需要先验知识,凭空估计很困难,或者可能导致效果很差。
异常点的存在:K-means算法在迭代的过程中使用所有点的均值作为新的质点(中心点),如果簇中存在异常点,将导致均值偏差比较严重。 比如一个簇中有2、4、6、8、100五个数据,那么新的质点为24,显然这个质点离绝大多数点都比较远;在当前情况下,使用中位数6可能比使用均值的想法更好,使用中位数的聚类方式叫做K-Mediods聚类(K中值聚类)。
初值敏感:K-means算法是初值敏感的,选择不同的初始值可能导致不同的簇划分规则。为了避免这种敏感性导致的最终结果异常性,可以采用初始化多套初始节点构造不同的分类规则,然后选择最优的构造规则。针对这点后面因此衍生了:二分K-Means算法、K-Means++算法、K-Means||算法、Canopy算法等。
通常情况下,在聚类算法中,样本的属性主要由其在特征空间中的相对距离来表示。
这就使得距离这个概念,对于聚类非常重要。以下是几种最常见的距离计算方法。
欧式距离(又称 2-norm 距离)
在欧几里德空间中,点 x=(x1,…,xn) 和 y=(y1,…,yn) 之间的欧氏距离为: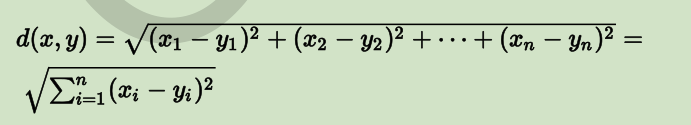
在欧几里德度量下,两点之间线段最短。
余弦距离(又称余弦相似性)
两个向量间的余弦值可以通过使用欧几里德点积公式求出:
a?b=∥a∥∥b∥cosθ
所以: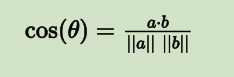
也就是说,给定两个属性向量 A 和 B,其余弦距离(也可以理解为两向量夹角的余弦)由点积和向量长度给出,如下所示: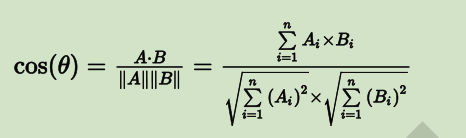
这里的 Ai 和 Bi 分别代表向量 A 和 B 的各分量。
曼哈顿距离(Manhattan Distance, 又称 1-norm 距离)
曼哈顿距离的定义,来自于计算在规划为方型建筑区块的城市(如曼哈顿)中行车的最短路径。
假设一个城市是完备的块状划分,从一点到达另一点必须要按照之间所隔着的区块的边缘走,没有其他捷径(如下图):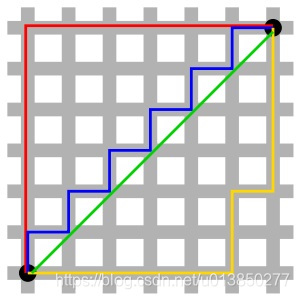
因此,曼哈顿距离就是:在直角坐标系中,两点所形成的线段对 x 和 y 轴投影的长度总和。
从点 (x1,y1) 到点 (x2,y2),曼哈顿距离为:
|x1?x2|+|y1?y2|
import matplotlib.pyplot as plt from sklearn.datasets import make_blobs # 导入产生模拟数据的方法 from sklearn.cluster import KMeans # 1. 产生模拟数据 k = 5 X, Y = make_blobs(n_samples=1000, n_features=2, centers=k, random_state=1) # 2. 模型构建 km = KMeans(n_clusters=k, init=‘k-means++‘, max_iter=30) km.fit(X) # 获取簇心 centroids = km.cluster_centers_ # 获取归集后的样本所属簇对应值 y_kmean = km.predict(X) # 呈现未归集前的数据 plt.scatter(X[:, 0], X[:, 1], s=50) plt.yticks(()) plt.show() plt.scatter(X[:, 0], X[:, 1], c=y_kmean, s=50, cmap=‘viridis‘) plt.scatter(centroids[:, 0], centroids[:, 1], c=‘black‘, s=100, alpha=0.5) plt.show()
代码运行结果: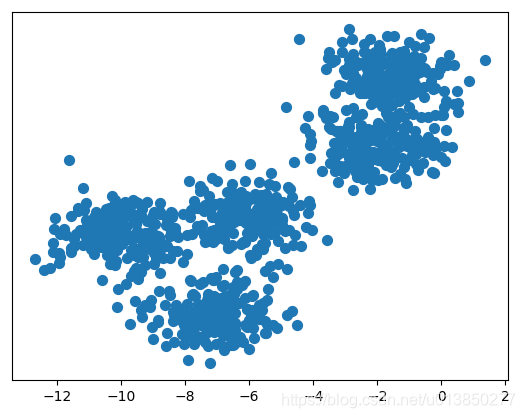
归集后的数据图: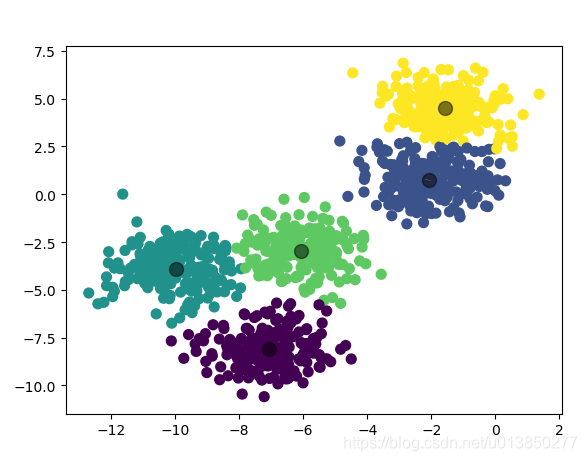
优点:
缺点:
KMeans 初始值敏感示例图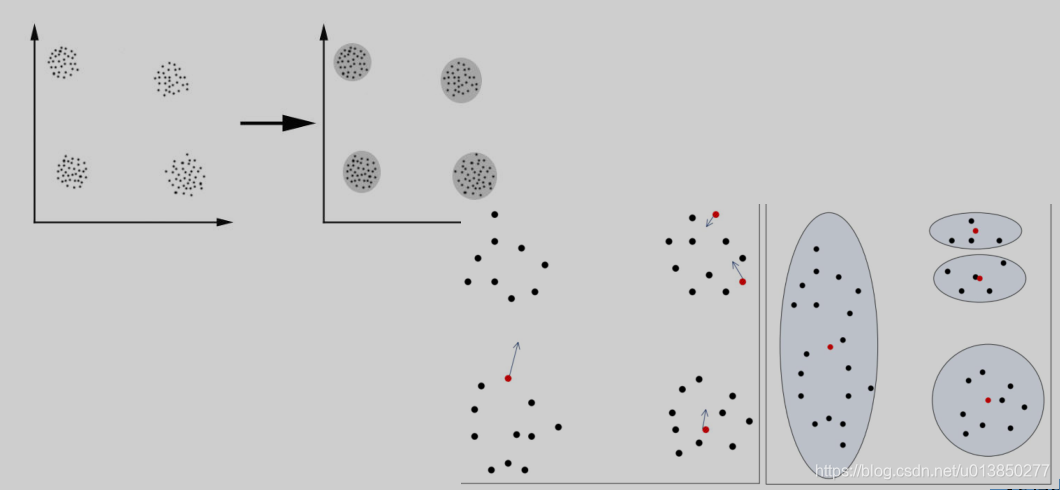
解决K-Means算法对初始簇心比较敏感的问题,二分K-Means算法是一种弱化初始质心的一种算法,具体思路步骤如下:
从队列中选择划分聚簇的规则一般有两种方式;分别如下:
1. 对所有簇计算误差和SSE(SSE也可以认为是距离函数的一种变种),选择SSE最大的聚簇进行划分操作(优选这种策略);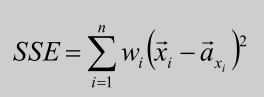
缺点:
由于聚类中心点选择过程中的内在有序性,在扩展方面存在着性能方面的问题(第k个聚类中心点的选择依赖前k-1个聚类中心点的值)。
解决K-Means++算法缺点而产生的一种算法;
主要思路是改变每次遍历时候的取样规则,并非按照K-Means++算法每次遍历只获取一个样本,
而是每次获取K个样本,重复该取样操作O(logn)次,然后再将这些抽样出来的样本聚类出K个点,
最后使用这K个点作为K-Means算法的初始聚簇中心点。
实践证明:一般5次重复采用就可以保证一个比较好的聚簇中心点。
Canopy算法属于一种“粗”聚类算法,执行速度较快,但精度较低,算法执行
步骤如下:
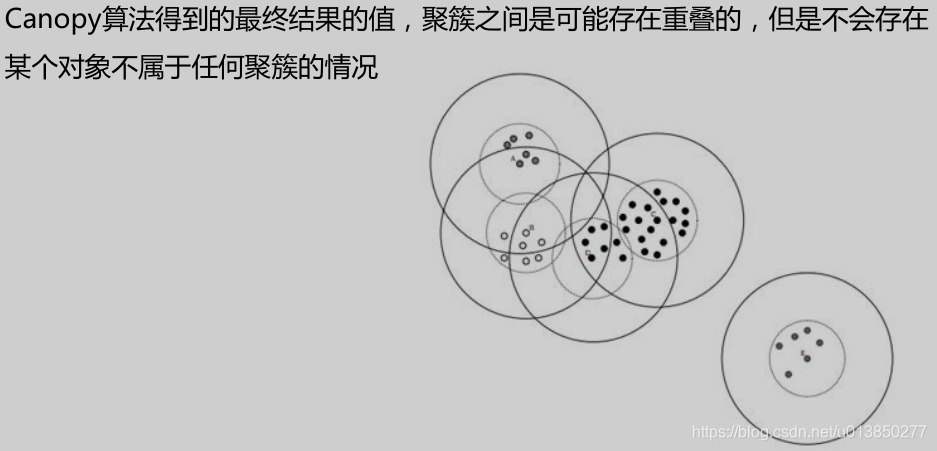
优点:
Mini Batch K-Means算法是K-Means算法的一种优化变种,采用小规模的数据子集(每次训练使用的数据集是在训练算法的时候随机抽取的数据子集)减少计算时间,同时试图优化目标函数;
Mini Batch K-Means算法可以减少K-Means算法的收敛时间,而且产生的结果效果只是略差于标准K-Means算法算法步骤如下:
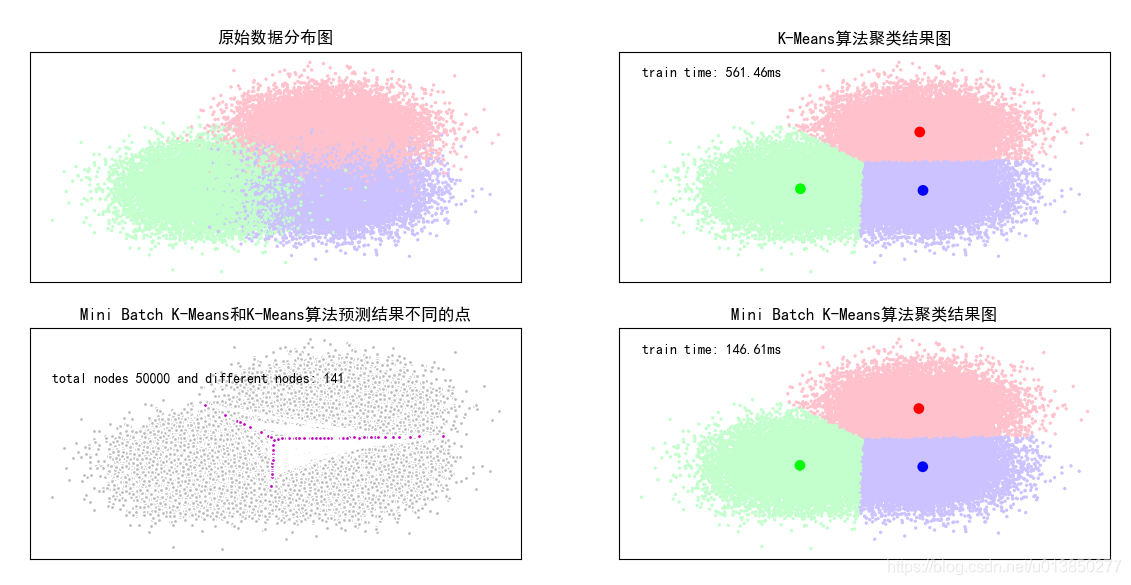
K-Means和Mini Batch K-Means算法比较案例
基于scikit包中的创建模拟数据的API创建聚类数据,使用K-means算法和MiniBatch K-Means算法对数据进行分类操作,比较这两种算法的聚类效果以及聚类的消耗时间长度。
import time import numpy as np import matplotlib.pyplot as plt import matplotlib as mpl from sklearn.cluster import MiniBatchKMeans, KMeans from sklearn.metrics.pairwise import pairwise_distances_argmin from sklearn.datasets.samples_generator import make_blobs # 设置属性防止中文乱码 mpl.rcParams[‘font.sans-serif‘] = [u‘SimHei‘] mpl.rcParams[‘axes.unicode_minus‘] = False # 初始化三个中心 centers = [[1, 1], [-1, -1], [1, -1]] clusters = len(centers) # 聚类的数目为3 # 产生50000组二维的数据,中心是意思三个中心点,标准差是.7 total_samples = 50000 X, Y = make_blobs(n_samples=total_samples, centers=centers, cluster_std=0.7, random_state=28) # 构建kmeans算法 k_means = KMeans(init=‘k-means++‘, n_clusters=clusters, random_state=28) t0 = time.time() # 当前时间 k_means.fit(X) # 训练模型 km_batch = time.time() - t0 # 使用kmeans训练数据的消耗时间 print("K-Means算法模型训练消耗时间:%.4fs" % km_batch) # 构建MiniBatchKMeans算法 batch_size = 100 mbk = MiniBatchKMeans(init=‘k-means++‘, n_clusters=clusters, batch_size=batch_size, random_state=28) t0 = time.time() mbk.fit(X) mbk_batch = time.time() - t0 print("Mini Batch K-Means算法模型训练消耗时间:%.4fs" % mbk_batch) # 预测结果 km_y_hat = k_means.predict(X) mbkm_y_hat = mbk.predict(X) # print(km_y_hat[:10]) # print(mbkm_y_hat[:10]) # print(k_means.cluster_centers_) # print(mbk.cluster_centers_) #获取聚类中心点并聚类中心点进行排序 k_means_cluster_centers = k_means.cluster_centers_ # 输出kmeans聚类中心点 mbk_means_cluster_centers = mbk.cluster_centers_ # 输出mbk聚类中心点 # print("K-Means算法聚类中心点:\ncenter=", k_means_cluster_centers) # print("Mini Batch K-Means算法聚类中心点:\ncenter=", mbk_means_cluster_centers) # 方便后面画图 order = pairwise_distances_argmin(k_means_cluster_centers, mbk_means_cluster_centers) # 画图 plt.figure(figsize=(12, 6), facecolor=‘w‘) plt.subplots_adjust(left=0.05, right=0.95, bottom=0.05, top=0.9) cm = mpl.colors.ListedColormap([‘#FFC2CC‘, ‘#C2FFCC‘, ‘#CCC2FF‘]) cm2 = mpl.colors.ListedColormap([‘#FF0000‘, ‘#00FF00‘, ‘#0000FF‘]) # 子图1:原始数据 plt.subplot(221) plt.scatter(X[:, 0], X[:, 1], c=Y, s=6, cmap=cm, edgecolors=‘none‘) plt.title(u‘原始数据分布图‘) plt.xticks(()) plt.yticks(()) plt.grid(True) # 子图2:K-Means算法聚类结果图 plt.subplot(222) plt.scatter(X[:, 0], X[:, 1], c=km_y_hat, s=6, cmap=cm, edgecolors=‘none‘) plt.scatter(k_means_cluster_centers[:, 0], k_means_cluster_centers[:, 1], c=range(clusters), s=60, cmap=cm2,edgecolors=‘none‘) plt.title(u‘K-Means算法聚类结果图‘) plt.xticks(()) plt.yticks(()) plt.text(-3.8, 3, ‘train time: %.2fms‘ % (km_batch * 1000)) plt.grid(True) # 子图三Mini Batch K-Means算法聚类结果图 plt.subplot(224) plt.scatter(X[:, 0], X[:, 1], c=mbkm_y_hat, s=6, cmap=cm, edgecolors=‘none‘) plt.scatter(mbk_means_cluster_centers[:, 0], mbk_means_cluster_centers[:, 1], c=range(clusters), s=60, cmap=cm2, edgecolors=‘none‘) plt.title(u‘Mini Batch K-Means算法聚类结果图‘) plt.xticks(()) plt.yticks(()) plt.text(-3.8, 3, ‘train time: %.2fms‘ % (mbk_batch * 1000)) plt.grid(True) # different = list(map(lambda x: (x != 0) & (x != 1) & (x != 2), mbkm_y_hat)) for k in range(clusters): different += ((km_y_hat == k) != (mbkm_y_hat == order[k])) identic = np.logical_not(different) different_nodes = len(list(filter(lambda x: x, different))) plt.subplot(223) # 两者预测相同的 plt.plot(X[identic, 0], X[identic, 1], ‘w‘, markerfacecolor=‘#bbbbbb‘, marker=‘.‘) # 两者预测不相同的 plt.plot(X[different, 0], X[different, 1], ‘w‘, markerfacecolor=‘m‘, marker=‘.‘) plt.title(u‘Mini Batch K-Means和K-Means算法预测结果不同的点‘) plt.xticks(()) plt.yticks(()) plt.text(-3.8, 2, ‘total nodes %d and different nodes: %d‘ % (total_samples, different_nodes)) plt.show()
原文:https://www.cnblogs.com/ai-ldj/p/14296143.html